Hash Maps/Tables - Powerful Data Structure
 Cindy Kandie
Cindy Kandie
Introduction
Did you know that hash maps, also known as hash tables, are among the most popular and highly valued data structures? While they rely on underlying arrays, they offer a more efficient key-value pair storage system compared to arrays alone. In this article, we'll explore the inner workings of hash maps, their advantages over arrays, differences between the two, real-life examples of their usage, and how to handle hash collisions. We'll also provide a simple JavaScript coding challenge that demonstrates the practical application of hash maps.
Advantages of Hash Maps
Hash maps offer several advantages over other data structures, making them widely used and valued. Some key advantages include:
Efficient key-value storage with a time complexity of O(1) for insert, delete, and search operations.
Many underlying operations are abstracted away, making them easy to use and reducing complexity.
Simplicity in handling data retrieval using keys.
JavaScript provides built-in support for hash maps, making them convenient to work with.
Differences between Arrays and Hash Maps
While both arrays and hash maps store data, they have distinct differences. Here are five key differences between the two, in case you are wondering:
a) Accessing Data: In arrays, data is accessed sequentially, whereas, in hash maps, data is accessed through keys, providing direct access.
b) Key Types: Hash maps do not require keys to be integers, unlike arrays that strictly use integer indices.
c) Size Flexibility: Arrays have a fixed size, while hash maps can dynamically resize based on the number of key-value pairs.
d) Ordering: Arrays maintain the order of elements, while hash maps do not guarantee a specific order.
e) Memory Usage: Hash maps typically use more memory due to the additional overhead of storing keys.
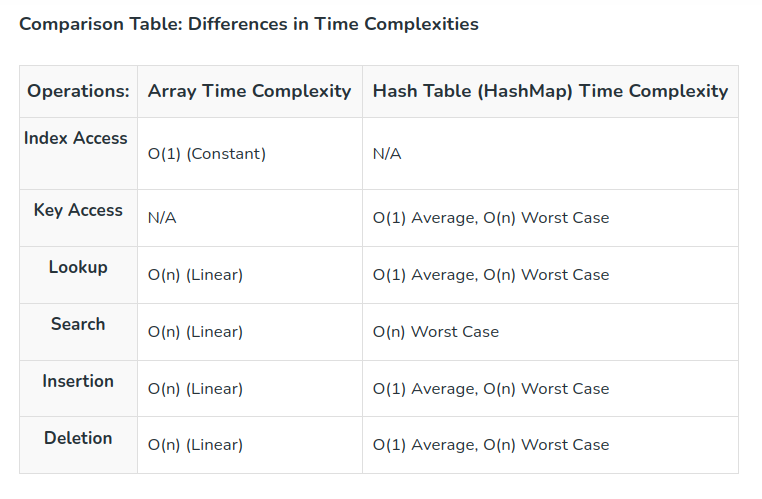
Behind the Scenes: How Hashing Works
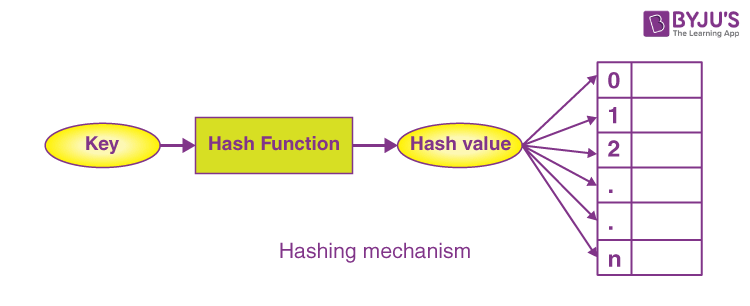
Hashing is a fundamental concept behind hash maps. It involves using a hash function to transform keys into indices within the underlying array. The hash function assigns a unique index to each key, allowing for efficient data retrieval. Here's an overview of the process:
A hash function takes the key as input and produces a hash code, which is an integer.
The hash code is then converted into an index within the underlying array using a modulo operation.
In cases of hash collisions (multiple keys hashing to the same index), hash maps use separate chaining or open addressing techniques.
// Pseudocode for a hash function
function hash(key, arraySize):
hashValue = 0
for i = 0 to key.length - 1:
hashValue = (hashValue + key[i].charCodeAt(0)) % arraySize
return hashValue
// Example usage
key = "exampleKey"
arraySize = 10
hashValue = hash(key, arraySize)
// Output
hashValue is the resulting index within the underlying array
Real-Life Examples of Hash Map Usage
Hash maps find applications in various real-life scenarios, including popular applications. Here are three examples where hash maps are commonly employed:
a) Caching: Web browsers often use hash maps to cache web pages, speeding up subsequent visits to the same website.
b) Spell Checkers: Spell-checking algorithms utilize hash maps to store dictionaries and quickly verify word spellings. eg Grammarly
c) Social Media Platforms: Hash maps are extensively used to manage user profiles, track followers, and handle notifications efficiently.
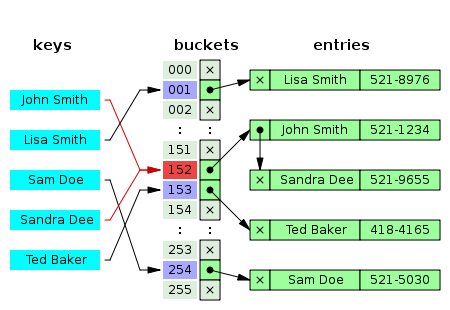
Handling Hash Collisions
Hash collisions occur when multiple keys map to the same index within the underlying array. To mitigate collisions, hash maps employ various strategies, mainly:
a) Separate Chaining: In separate chaining, each index in the array acts as a linked list, with each node containing a key-value pair. Collisions are resolved by appending new nodes to the linked list.
b) Open Addressing: Open addressing involves finding an alternative (often nearby) empty slot within the array to store the collided key-value pair. Various techniques like linear probing and quadratic probing can be used for open addressing.
// Pseudocode for handling collisions with separate chaining
// Initialize an array of linked lists
arraySize = 10
hashArray = new Array(arraySize)
// Pseudocode for inserting key-value pairs
function insert(key, value):
index = hash(key) // Determine the index using the hash function
// If the index is empty, create a new linked list and add the key-value pair
if hashArray[index] is empty:
hashArray[index] = new LinkedList()
hashArray[index].add(key, value)
// Pseudocode for retrieving a value by key
function get(key):
index = hash(key) // Determine the index using the hash function
// Traverse the linked list at the index to find the key-value pair
currentNode = hashArray[index].head
while currentNode is not null:
if currentNode.key is equal to key:
return currentNode.value
currentNode = currentNode.next
// Key not found
return null
// Pseudocode for removing a key-value pair
function remove(key):
index = hash(key) // Determine the index using the hash function
// Traverse the linked list at the index to find and remove the key-value pair
currentNode = hashArray[index].head
prevNode = null
while currentNode is not null:
if currentNode.key is equal to key:
if prevNode is null:
hashArray[index].head = currentNode.next
else:
prevNode.next = currentNode.next
return true // Key-value pair successfully removed
prevNode = currentNode
currentNode = currentNode.next
// Key not found
return false
// Example usage
insert("key1", "value1")
insert("key2", "value2")
insert("key3", "value3")
insert("key4", "value4")
insert("key5", "value5")
// Output
The keys "key1" and "key4" generate the same hash code and collide at the same index within the array. Separate chaining is used to handle the collision, where each index contains a linked list of key-value pairs.
Resizing for Optimal Performance
When hash maps experience a significant number of key-value pairs or frequent collisions, resizing becomes necessary to maintain optimal performance. Resizing involves creating a new array with a larger size, rehashing the existing key-value pairs using a new hash function, and transferring them to the new array. Resizing is also triggered when the number of key-value pairs decreases to prevent excessive memory usage.
//Pseudocode for the resizing process of a hash map
//Initialize an initial array size and load factor threshold
initialArraySize = 10
loadFactorThreshold = 0.75
//Initialize a count to keep track of the number of key-value pairs in the hash map
count = 0
// Pseudocode for inserting key-value pairs
function insert(key, value):
if count / arraySize > loadFactorThreshold:
resize() //Trigger resize if the load factor threshold is exceeded
index = hash(key) // Determine the index using the hash function
// Insert the key-value pair into the hash map
// Pseudocode for the resize function
function resize():
newArraySize = arraySize * 2 // Double the size of the array
newArray = new Array(newArraySize) // Create a new array with the new size
// Rehash and transfer the existing key-value pairs to the new array
for each key-value pair in the current array:
index = hash(key, newArraySize) // Determine the new index using the new hash function
newArray[index].add(key, value) // Add the key-value pair to the new array
array = newArray // Replace the current array with the new array
arraySize = newArraySize // Update the array size
// Example usage
insert("key1", "value1")
insert("key2", "value2")
insert("key3", "value3")
insert("key4", "value4")
insert("key5", "value5")
// Output
When the load factor threshold is exceeded, the resize process is triggered.
The array is doubled in size, and the existing key-value pairs are rehashed using a new hash function and transferred to the new array.
Coding Challenge
To demonstrate the practical application of hash maps in JavaScript, let's consider the following problem:
Given an array of integers, find the first non-repeating element. You can solve this problem efficiently using a hash map to store the frequency of each integer.
// Function to find the first non-repeating element in an array
function findFirstNonRepeatingElement(arr) {
const frequencyMap = new Map(); // Create a hash map to store the frequency of each number
// Count the frequency of each number in the array using the hash map
for (const num of arr) {
frequencyMap.set(num, (frequencyMap.get(num) || 0) + 1); // Increment the frequency count
}
// Find the first non-repeating element by iterating over the hash map
for (const [num, frequency] of frequencyMap) {
if (frequency === 1) { // If the frequency is 1, it means the number is non-repeating
return num; // Return the first non-repeating element
}
}
return -1; // If no non-repeating element is found, return -1
}
const arr = [1, 2, 3, 2, 1, 4, 4, 5];
const result = findFirstNonRepeatingElement(arr);
console.log("The first non-repeating element is:", result);
Conclusion
Hash maps, or hash tables, provide an efficient key-value pair storage system, outperforming arrays for insert, delete, and search operations. They offer advantages such as simplicity, abstraction of underlying operations, and ease of use in JavaScript. While hash maps require understanding the complexities of hashing and addressing collisions, they find practical applications in various domains. By leveraging hash maps, developers can efficiently solve problems and optimize performance in their applications.
Subscribe to my newsletter
Read articles from Cindy Kandie directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Cindy Kandie
Cindy Kandie
Overly ambitious dev hoping it pays off, bet you relate...