A Beginner's Guide to BOW for AI Projects
 Yuvraj Singh
Yuvraj Singh
Hi, I hope you are doing, so today we will discuss about a very commonly used and easy to understand word embedding technique called BOW. In this blog we willfirst start of with the basic introduction to word embeddings, techniques we can use for creating embeddings and a detailed explanation of BOW. So without any further delay let's get started.
What are word embeddings
Word embeddings are simply numerical representation of textual words, where numerical representation means vector.
Types of word embeddings
There are basically 2 different approaches which we can use for creating word embeddings, these are 👇🏻
Frequency based word embeddings
Prediction based word embeddings
Frequency based word embeddings
As the name suggest these are basically those techniques which use the frequency of the word in the vocabulary to create embeddings. Such techniques include
Bag of words (BOW)
Term frequency inverse document frequency (TF-IDF)
Prerequisites for BOW implementation
Before the implementation of any of mentioned technique there are some processes which must be performed ⬇️
Tokenization : If we are dealing with textual data stored form of long paragraphs then we must perform tokenization on those long papagraphs to break them down into small texts , known as token.
Lowering the sentences : After pplying tokenization , lowering the sentences is also an important process to perform , because even we humans know that both 'hut' and 'Hut' means some , but when we will convert the words into their numerical representtion then , both of these word will be considered different , thus in order to prevent this we lower the sentences.
Stop word removal : The process of stop word removal is also very much important in order to remove less important words which don't contribute a lot while deducing the meaning of the sentence . Some of these words are : The , he , she , is , are etc.
Stemming or Lemmatization : Stemming or Lemmatization is the last process which you can perform in order to reduce the inflection of words to their base form , so that Machine learning algorithm could easily process and learn the similar words.
Bag of Words
BOW which is a short form for Bag of words is a Natural language processing technique that can is used for creating word embeddings by utilizing the vocabulary of the corpus.To better understand the working of the Bag Of Words , let us take 3 documents as our reference ⬇️
Doc 1 : He is a good boy
Doc 2: She is a good girl
Doc 3 : Both boy and girl are good listeners and good speakers.
Here in this case after lowering the sentences , removing the stop words and applying the stemming/lemmatization we will be having above 3 documents in the form 🎰
Doc 1 : He good boy
Doc 2: She good girl
Doc 3 : Both boy girl good listeners good speakers
Now after cleaning the documents the next step is buidling vocabulary out of this corpus of 3 documents. In case you are not aware about vocabulary don't worry it is nothing more than collection of all the unique words. Now once vocabulary will be build the algorithm will simply assign a numerical value to each word present in the document and this numerical value would represent frequency count of the word.

Types of Bag Of Words
Now since you are aware about how does BOW technique works, let me give you some information abut BOW. There are 2 different ways in which we can implement Bag of Words technique.
Normal Bag Of Words : In this type the numerical value assigned to a word in the document represents its occruence in that document.
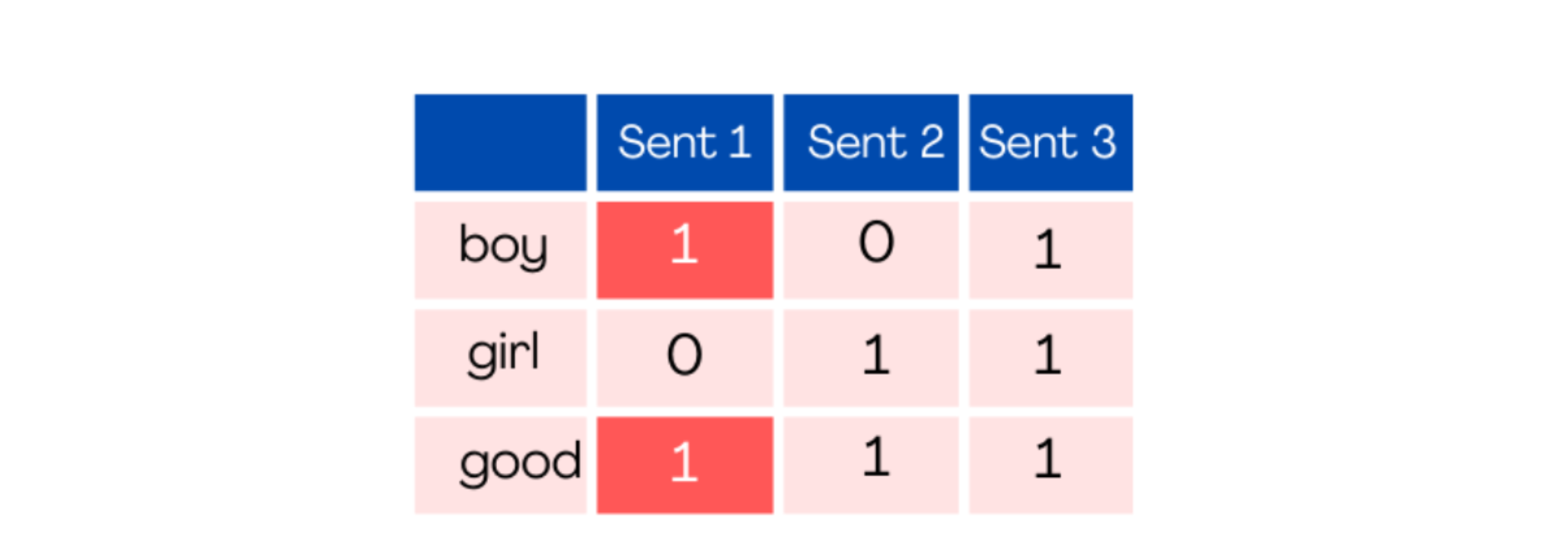
Binary Bag Of Words : In this type only 2 type of numerical values are assigned to every word in document and these 2 values are 0 or 1, where 1 represents the presence of word and 0 represents the absence of word in the document.
Advantages of Bag Of Words
It is very much simple to understand and implement
It make sure that the dimensionality of vectors remain same
Drawback of Bag Of Words
It doesn't consider out of vocabulary words which have the possibility of providing useful information
It creates high dimensional sparse vectors in case vocabulary is very large.
It doesn't capture semantic information and also doesn't focus on ordering of words in document.
Practical implementation of Bag Of Words Using Python
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
# Create a list of documents
documents = ["This is a bag of words example.", "This is another example."]
# Create a CountVectorizer object
vectorizer = CountVectorizer()
# Fit the CountVectorizer to the documents
vectorizer.fit(documents)
# Transform the documents into vectors
bow_representations = vectorizer.transform(documents)
# Print the bow representations
print(bow_representations.toarray())
Short note
I hope you good understanding of what are word embeddings, what are the various techniques we can use, how does BOW works and types of BOW. So if you liked this blog or have any suggestion kindly like this blog or leave a comment below it would mean a to me.
Subscribe to my newsletter
Read articles from Yuvraj Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Yuvraj Singh
Yuvraj Singh
With hands-on experience from my internships at Samsung R&D and Wictronix, where I worked on innovative algorithms and AI solutions, as well as my role as a Microsoft Learn Student Ambassador teaching over 250 students globally, I bring a wealth of practical knowledge to my Hashnode blog. As a three-time award-winning blogger with over 2400 unique readers, my content spans data science, machine learning, and AI, offering detailed tutorials, practical insights, and the latest research. My goal is to share valuable knowledge, drive innovation, and enhance the understanding of complex technical concepts within the data science community.