Unleashing the power of Data : Storage
 Warui Wanjiru
Warui Wanjiru
Introduction:
Welcome to the second installment of our blog series on data storage. In the previous blog post, we explored the origins of data and the importance of understanding source systems. In this article, we will dive deeper into the role of storage in the data engineering lifecycle. Storage is a critical component that supports key stages like data ingestion, transformation, and serving. It ensures that data is stored and persisted until it is ready for further processing and transmission. By choosing the right storage solutions, data engineers can design efficient and reliable data architectures. Let's explore the intricacies of storage systems and the factors to consider when making storage decisions.
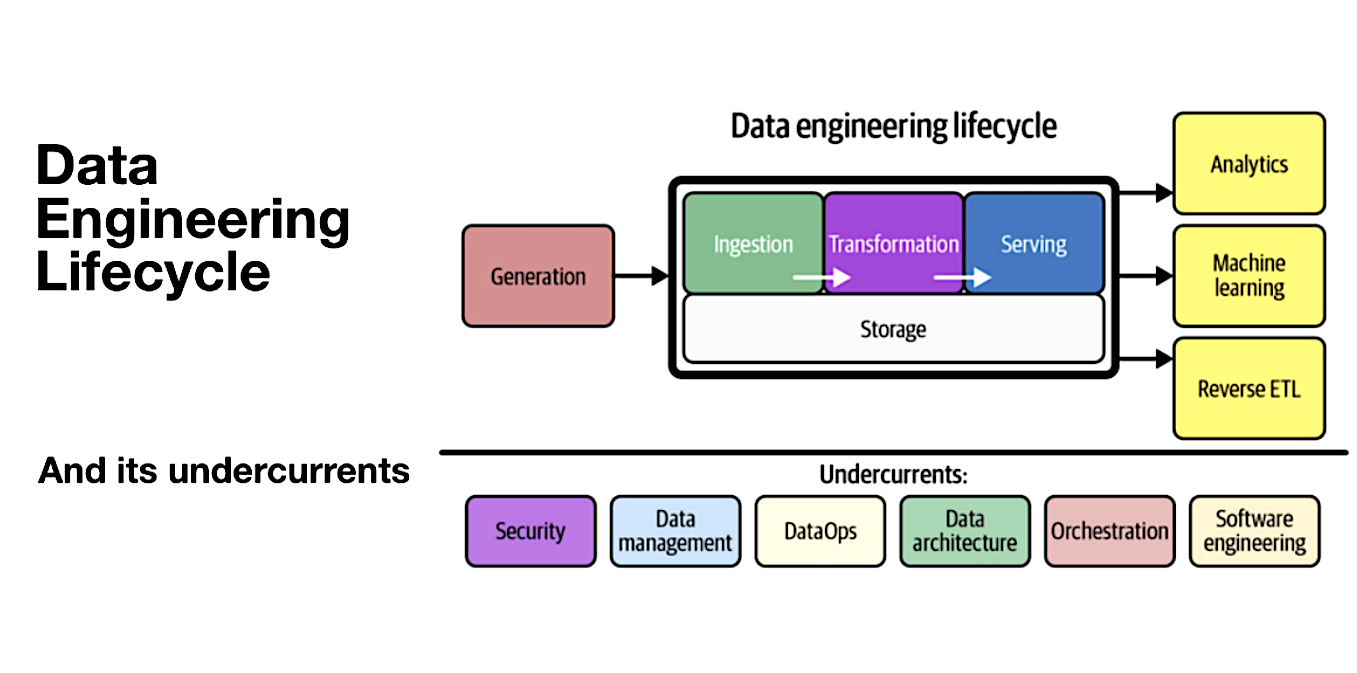
Storage in the Data Engineering Lifecycle:
While we briefly touched upon storage in the previous blog post, our focus was primarily on source systems that are typically outside the control of data engineers. In this chapter, we shift our attention to the storage systems that data engineers directly handle. These systems play a vital role in the data engineering lifecycle, encompassing stages like data ingestion, transformation, and serving. It is essential to understand the different forms of storage and their impact on the entire data engineering process.
Understanding Raw Ingredients and Storage Systems:
To gain a comprehensive understanding of storage, let's start by studying the raw ingredients that compose storage systems. These ingredients include hard disk drives (HDDs), solid-state drives (SSDs), and system memory. Each of these physical storage technologies has unique characteristics that must be considered when designing a storage architecture. Additionally, we will explore concepts like serialization, compression, and caching, which are key software elements of practical storage. Understanding caching is particularly crucial, as it plays a vital role in assembling storage systems.
Raw Ingredients of Data Storage:
Magnetic Disk Drives: Hard disk drives (HDDs) consist of spinning platters coated with a ferromagnetic film. They are cost-effective for bulk data storage but have limitations in terms of speed and input/output operations per second (IOPS). Despite these limitations, HDDs are widely used in data centers due to their low cost and high storage capacity.

Solid-State Drives: Solid-state drives (SSDs) store data as charges in flash memory cells and offer significant performance improvements compared to HDDs. They provide faster access times, higher IOPS, and higher transfer speeds. However, SSDs are more expensive, making them less common for high-scale analytics data storage. Nevertheless, they are extensively utilized in transactional databases due to their exceptional performance.

Random Access Memory (RAM): RAM, or system memory, offers significantly higher transfer speeds and faster retrieval times compared to storage devices like SSDs. It is used for caching, data processing, and indexes, enabling ultra-fast read and write performance.

Networking and CPU: Networking and CPU are crucial components in distributed storage architectures. Networking performance and network topology play a significant role in achieving high performance, while CPUs handle request servicing, data aggregation, and write distribution.

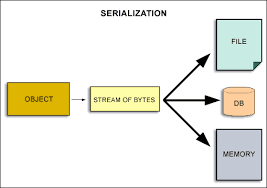
Serialization: Serialization involves flattening and packing data into a standard format that can be easily decoded. It ensures interoperability and facilitates data exchange between different programming languages and CPUs.
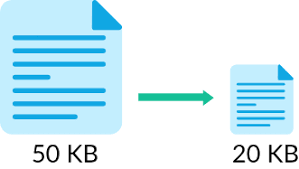
Compression: Compression reduces the size of data, resulting in benefits such as reduced storage space and improved performance. However, compression introduces additional time and resource overhead during data reading and writing operations.
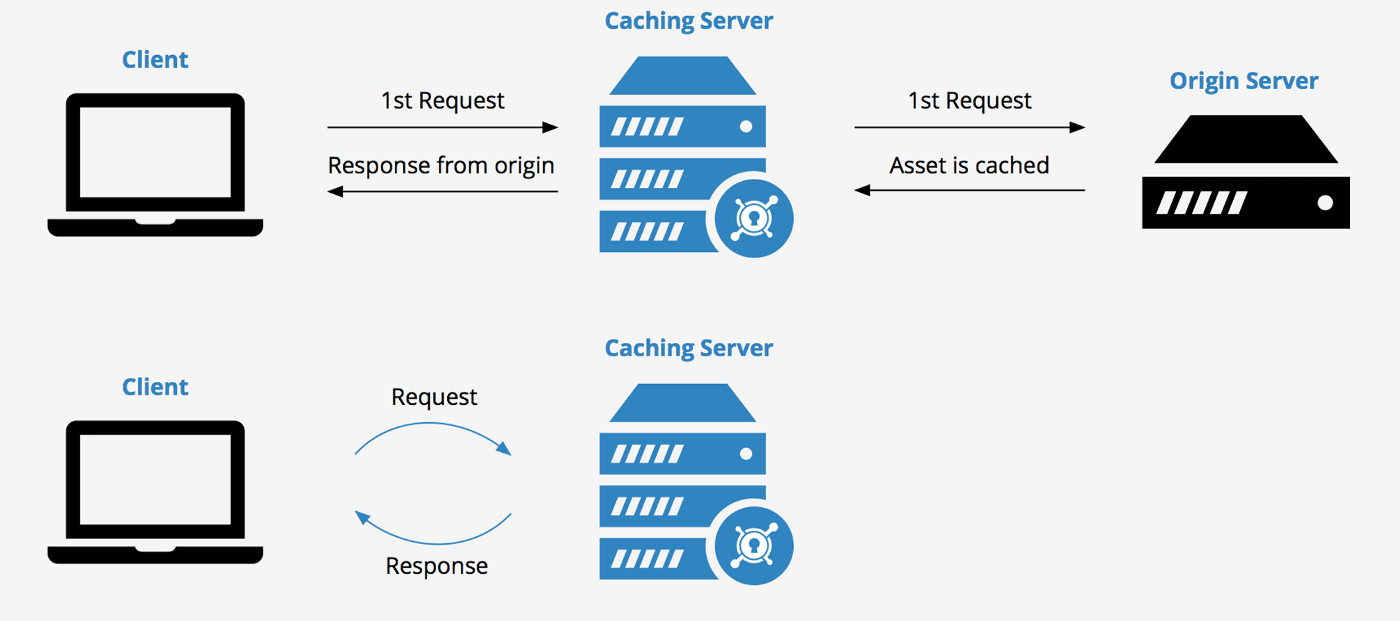
Caching: Caching involves storing frequently or recently accessed data in a fast access layer, improving data retrieval performance. Data engineers need to consider cache hierarchies and choose suitable cache layers based on performance requirements and cost considerations.
Conclusion
Storage is an integral part of the data engineering lifecycle, underpinning the stages of ingestion, transformation, and serving. By understanding the raw ingredients, storage systems, and storage abstractions, data engineers can make informed decisions to design efficient and reliable data architectures.
In the next blog post, we will dive deeper into the world of data storage systems, discussing different types of storage, their characteristics, and use cases. Stay tuned for more insights on this critical aspect of data engineering!
Subscribe to my newsletter
Read articles from Warui Wanjiru directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Warui Wanjiru
Warui Wanjiru
I am a passionate and highly motivated Junior Data Engineer, driven by my curiosity and eagerness to explore the vast world of data. With a solid foundation in data analytics, programming, and database management, I thrive on the challenge of extracting, cleaning, transforming, and visualizing data to uncover valuable insights. My journey in the realm of data engineering has exposed me to various programming languages and tools, including Python, SQL, and Tableau. However, I don't stop there—I am constantly seeking new knowledge and skills to stay ahead of the curve. Currently, I am immersing myself in the world of Rust, harnessing its speed and efficiency prowess. Embracing this new language allows me to tackle complex data engineering tasks with even greater efficiency and effectiveness. What truly sets me apart is my genuine enthusiasm for learning and taking on new challenges. I thrive in dynamic environments that push me to think creatively and find innovative solutions. With a solid understanding of data structures and algorithms, I relish the opportunity to dive into complex datasets, unearthing patterns and unlocking actionable insights. Above all, I am dedicated to making a real impact through data engineering. I believe in the power of data to drive transformative change and improve decision-making processes. By harnessing the power of data, I strive to empower organizations to make informed choices and achieve tangible results. Let's embark on this exciting journey together, where I can contribute my authentic enthusiasm, my thirst for knowledge, and my unwavering commitment to delivering exceptional data solutions.