Unleashing the power of Data: Data Storage Systems
 Warui Wanjiru
Warui Wanjiru
Introduction
As a data engineer, you'll encounter various data storage systems that play a crucial role in managing and accessing data. These storage systems exist at a higher level of abstraction than the raw storage ingredients, such as magnetic disks or solid-state drives. In this blog post, we'll delve into the major data storage systems you're likely to encounter and understand their significance in the data engineering landscape. It's important to note that storage systems go beyond raw storage components and provide functionalities that facilitate efficient data management.
Single Machine vs. Distributed Storage:
As data storage needs grow more complex, a single server may no longer be sufficient. In such cases, distributing data across multiple servers becomes necessary. Distributed storage systems coordinate the activities of multiple servers to store, retrieve, and process data at a larger scale while providing redundancy in case of server failures. Distributed storage architectures are commonly used when scalability and built-in redundancy are required for handling large amounts of data. Examples of distributed storage systems include object storage, Apache Spark, and cloud data warehouses.
Data engineers need to be aware of the consistency paradigms in distributed systems. Two common consistency patterns are eventual consistency and strong consistency. Eventual consistency is based on the concepts of basically available, soft-state, and eventual consistency (BASE). It means that while consistency is not guaranteed at all times, data will eventually become consistent. Eventual consistency is often employed in large-scale distributed systems where horizontal scaling is necessary, allowing for quick data retrieval without the need for immediate consistency across all nodes.
On the other hand, strong consistency ensures that writes to any node in the distributed database are distributed with a consensus, and any reads return consistent values. Strong consistency is suitable when higher query latency can be tolerated, and correct data is required with every read operation. The choice between eventual and strong consistency depends on the specific requirements of your data engineering projects.
File Storage:
File storage systems organize data into files and directories. Files are finite-length streams of bytes that support append operations and random access. Local disk storage, managed by the operating system's filesystem, is the most familiar type of file storage. Popular filesystems like NTFS and ext4 are used in Windows and Linux environments, respectively. Local filesystems offer features such as journaling, snapshots, redundancy, encryption, and compression, providing full read-after-write consistency.
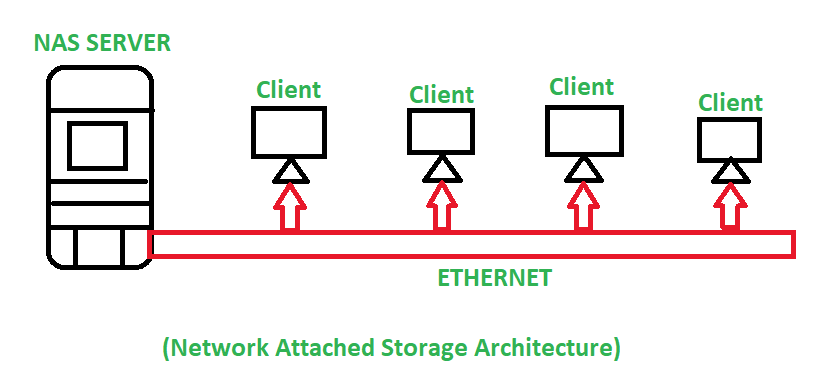
Network-attached storage (NAS) systems provide file storage over a network and are commonly used in server environments. NAS solutions offer advantages like storage virtualization, redundancy, resource control, and file sharing across multiple machines. When multiple clients access the same data, understanding the consistency model provided by the NAS system becomes crucial.
Cloud filesystem services, such as Amazon Elastic File System (EFS), provide fully managed filesystems for use with multiple cloud VMs and applications. These services handle networking, disk cluster management, failures, and configuration, offering scalability, pay-per-storage pricing models, and consistency guarantees across multiple instances. Cloud filesystems behave similarly to NAS solutions but with the added benefits of cloud management and scalability.
Block Storage:
Fundamentally, block storage refers to the raw storage provided by solid-state drives (SSDs) and magnetic disks. Block storage allows fine control of storage size, scalability, and data durability beyond what raw disks offer. Blocks are the smallest addressable units of data supported by disks, typically ranging from 512 bytes to 4,096 bytes. Block storage applications include transactional database systems, where accessing disks at a block level optimizes performance. Block storage is also commonly used for operating system boot disks on cloud virtual machines.
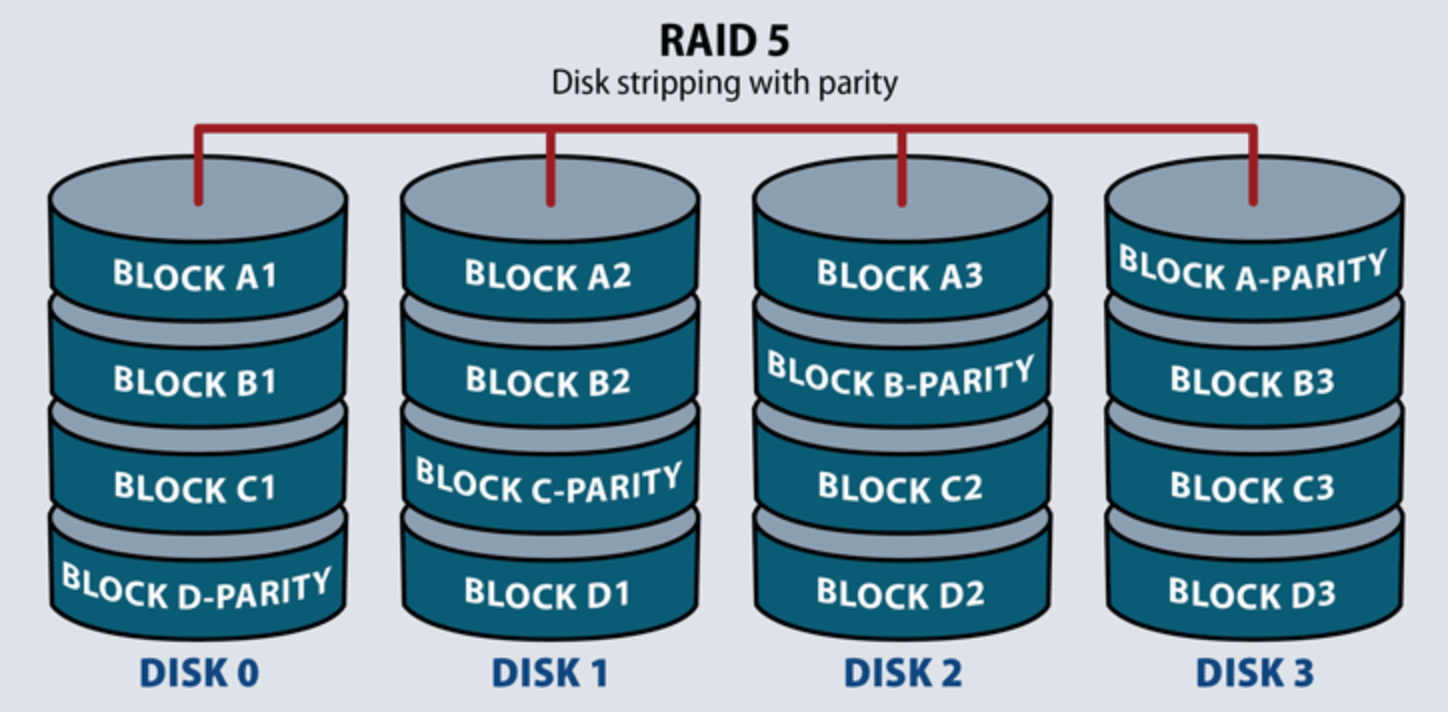
RAID (redundant array of independent disks) is a technology that combines multiple disks to improve data durability, enhance performance, and increase capacity. Various encoding and parity schemes are available in RAID to balance effective bandwidth and fault tolerance. RAID can appear to the operating system as a single-block device, offering improved storage efficiency.
Storage area network (SAN) systems provide virtualized block storage devices over a network, offering fine-grained storage scaling, performance enhancement, availability, and durability. SAN systems are commonly used in on-premises storage environments. Cloud providers also offer cloud virtualized block storage solutions, similar to SAN but with the cloud provider handling the SAN cluster and networking details. Amazon Elastic Block Store (EBS) is an example of cloud-virtualized block storage. EBS provides different tiers of service with varying performance characteristics, offering scalability, data durability, and features like point-in-time snapshots.
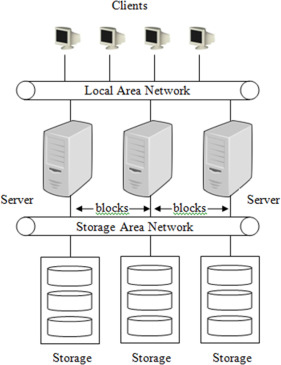
Local instance volumes, physically attached to the host server running a virtual machine, are low-cost block storage volumes that provide low latency and high input/output operations per second (IOPS). These volumes are useful when data loss is not catastrophic and advanced virtualization features are not required.
Object Storage:
Another important type of data storage is object storage. Object storage is widely used in the era of big data and cloud computing, offering a flexible and scalable solution for storing various types of files, such as TXT, CSV, JSON, images, videos, and audio.
Object storage systems like Amazon S3, Azure Blob Storage, and Google Cloud Storage (GCS) have gained popularity due to their ability to handle large volumes of data. These systems are often used as the storage layer for cloud data warehouses, databases, and data lakes.
Compared to traditional file storage, object storage has some unique characteristics. Objects in an object store are immutable, meaning they cannot be modified in place. Instead, objects are written as a stream of bytes and become immutable once written. To make changes to an object or append data, the entire object needs to be rewritten. While object stores support random reads through range requests, the performance of these lookups may not be as good as random reads from data stored on SSDs.
Although object storage may seem restrictive compared to local file storage, it offers advantages in terms of scalability and performance. Object stores can handle parallel stream writes and reads across multiple disks, enabling high-speed data processing for tasks like serving high-volume web traffic or delivering data to distributed query engines. Cloud object storage also provides durability and availability by storing data across multiple availability zones.
One of the key benefits of cloud object storage is its separation of compute and storage. By decoupling these components, organizations can process data using ephemeral clusters that can scale up or down based on demand. This makes big data processing more accessible to smaller organizations that don't have the resources to maintain their own hardware infrastructure. While some larger companies still run permanent Hadoop clusters, the general trend is towards migrating data processing to the cloud, leveraging object storage as the primary storage and serving layer.
Object stores excel in handling large batch reads and writes, making them well-suited for massive online analytical processing (OLAP) systems. While object stores may not be ideal for high-frequency transactional workloads with small updates, they are suitable for low-rate update operations that involve updating a large volume of data. Additionally, object storage is widely used in data lakes, providing a repository for unstructured data in various formats, including raw text, images, video, and audio.
When working with object storage, it's important to understand how object lookup works. Object stores utilize a key-value model, where objects are referenced by keys within logical containers, such as buckets in Amazon S3 or GCS. Unlike file stores that use a directory tree structure, object stores do not have a true directory hierarchy. Although some object stores may support directory-like semantics, the underlying object system does not traverse a directory tree. Instead, it simply matches keys to locate objects. It's worth noting that certain directory-level operations in object stores can be costly, especially when dealing with a large number of objects.
Overall, object storage offers a highly scalable and cost-effective solution for storing and processing large volumes of data in various formats. Its flexibility, durability, and parallel processing capabilities make it a crucial component in modern data engineering and analytics workflows.
Cache and Memory-Based Storage Systems:
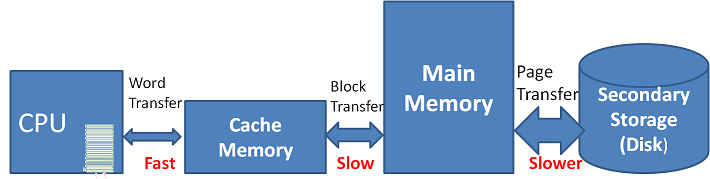
Cache and memory-based storage systems leverage the speed and efficiency of RAM to provide ultra-fast data access. Tools like Memcached and Redis are widely used for caching database query results and API call responses. These systems excel at delivering low-latency results, offloading backend systems, and enhancing overall performance. However, the data stored in these systems is typically transient and not meant for long-term retention.
The Hadoop Distributed File System (HDFS):
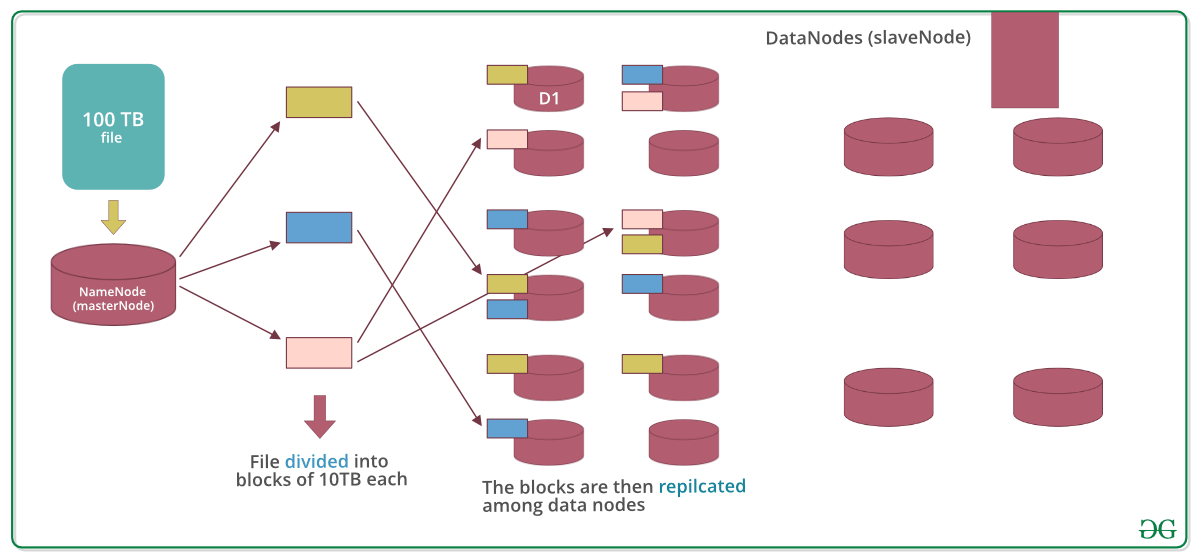
The Hadoop Distributed File System, built upon the Google File System (GFS), revolutionized big data processing. HDFS, designed for parallel processing, combines compute and storage on the same nodes. It breaks large files into blocks and replicates them across multiple nodes for increased durability and availability. While Hadoop's popularity has somewhat diminished, HDFS remains a foundational component in many big data architectures, especially for processing large volumes of data with frameworks like Apache Spark.
Streaming Storage:
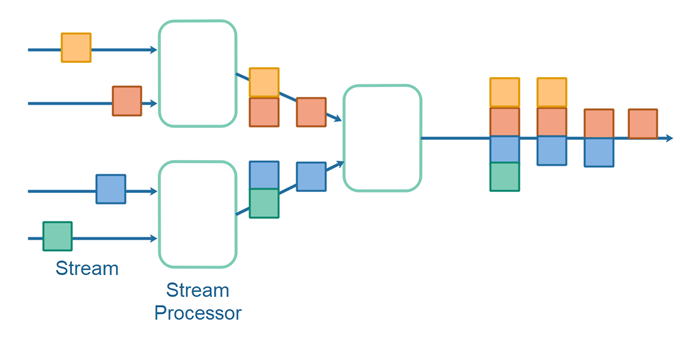
Streaming data has unique storage requirements. Distributed streaming frameworks such as Apache Kafka, Amazon Kinesis, and Apache Pulsar provide scalable and durable storage for real-time analytics. These systems allow for long data retention, facilitating the replay of historical data for batch queries or reprocessing in streaming pipelines. By pushing old and infrequently accessed messages to object storage, these frameworks enable indefinite data retention while optimizing performance and cost.
Indexes, Partitioning, and Clustering:
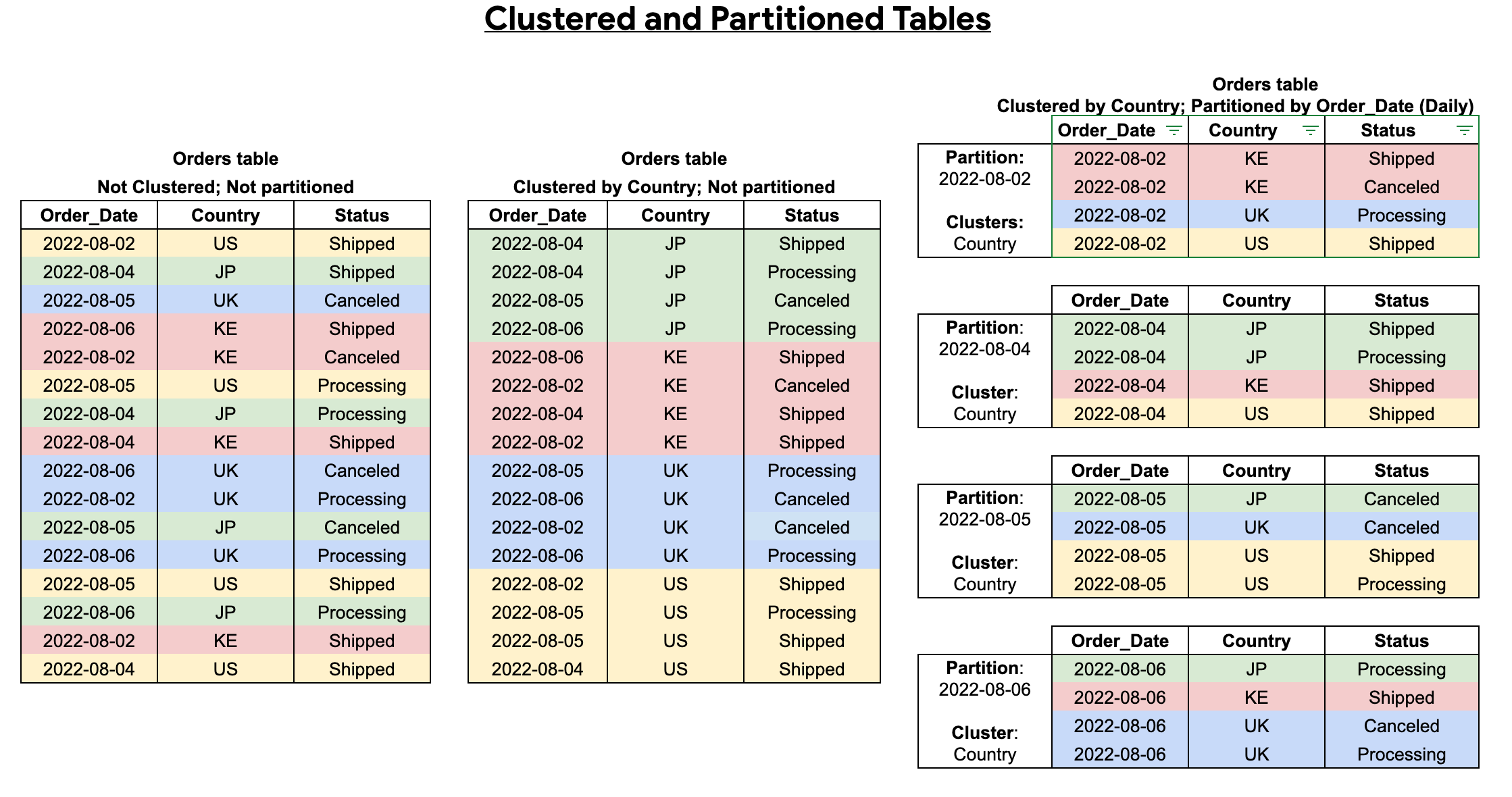
In analytics-oriented storage systems, indexes, partitions, and clustering techniques play a crucial role in optimizing performance. Traditional row-oriented databases heavily rely on indexes to speed up record lookup. However, with the rise of columnar databases, which excel at scanning large volumes of data, indexes have become less prevalent. Instead, partitioning tables based on specific fields (e.g., time-based partitioning) and clustering similar values within columns have become popular techniques for improving query performance. Snowflake's micro-partitioning is an excellent example of an advanced approach that leverages metadata to optimize data pruning and scanning.
Choosing the Right Storage System:
Selecting the appropriate data storage system for your specific use case requires careful consideration of various factors, including data volume, access patterns, performance requirements, scalability, and cost. Here are some key points to keep in mind when making your decision:
Understand your data: Analyze the nature of your data, including its structure, size, and velocity. Different storage systems are better suited for different types of data, such as structured, unstructured, or streaming data.
Consider workload characteristics: Evaluate the workload patterns of your data processing and analytics tasks. Determine whether you require low-latency random access, high-speed batch processing, or real-time streaming capabilities.
Scalability and elasticity: Assess your scalability needs and consider whether your storage system can handle the growing volume of data and the increasing demands of your applications. Cloud-based storage systems often offer scalability and elasticity advantages.
Integration with existing infrastructure: Consider how the storage system integrates with your existing data infrastructure, including databases, analytics platforms, and other storage systems. Compatibility and interoperability are essential for seamless data flow and processing.
Conclusion:
In this comprehensive guide to data storage systems, we explore various storage options beyond the basics. From file storage and block storage to object storage, cache systems, and streaming storage, each storage system has its unique characteristics and applications. By understanding the strengths and weaknesses of these systems, you can make informed decisions when architecting your data infrastructure and optimizing data processing workflows. As the data landscape continues to evolve, staying up to date with the latest advancements in storage technologies is crucial for unlocking the full potential of your data-driven initiatives.
Remember, there is no one-size-fits-all solution when it comes to data storage. Assess your specific requirements, consider the pros and cons of different systems, and choose the ones that best align with your business objectives. With the right storage system in place, you can unleash the power of your data and gain actionable insights to drive innovation and growth.
Stay tuned for our next installment, where we will explore the fascinating world of data processing frameworks and their role in extracting value from stored data.
Subscribe to my newsletter
Read articles from Warui Wanjiru directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Warui Wanjiru
Warui Wanjiru
I am a passionate and highly motivated Junior Data Engineer, driven by my curiosity and eagerness to explore the vast world of data. With a solid foundation in data analytics, programming, and database management, I thrive on the challenge of extracting, cleaning, transforming, and visualizing data to uncover valuable insights. My journey in the realm of data engineering has exposed me to various programming languages and tools, including Python, SQL, and Tableau. However, I don't stop there—I am constantly seeking new knowledge and skills to stay ahead of the curve. Currently, I am immersing myself in the world of Rust, harnessing its speed and efficiency prowess. Embracing this new language allows me to tackle complex data engineering tasks with even greater efficiency and effectiveness. What truly sets me apart is my genuine enthusiasm for learning and taking on new challenges. I thrive in dynamic environments that push me to think creatively and find innovative solutions. With a solid understanding of data structures and algorithms, I relish the opportunity to dive into complex datasets, unearthing patterns and unlocking actionable insights. Above all, I am dedicated to making a real impact through data engineering. I believe in the power of data to drive transformative change and improve decision-making processes. By harnessing the power of data, I strive to empower organizations to make informed choices and achieve tangible results. Let's embark on this exciting journey together, where I can contribute my authentic enthusiasm, my thirst for knowledge, and my unwavering commitment to delivering exceptional data solutions.