Introduction to deep learning
 Yuvraj Singh
Yuvraj Singh
Are you looking for a resource that can teach you everything you need to know about deep learning? Then you've come to the right place, because starting today, I'm going to start a deep learning blog series that will provide you with in-depth knowledge about deep learning, and this is the first blog in my upcoming series, so without further delay, let's get started.
Where is the Kingdom of deep learning?
Before going deep into the deep learning kingdom, you must be fully aware of where it lies in the world of AI. Deep learning is a very small kingdom but is very powerful, To better understand this, take a look at the visual below.
The precise definition of deep learning is that it is a branch of machine learning that draws its inspiration from the strucutre, function, and network of neurons found in the human brain.
Reasons behind the rise of Deep learning
The concept of deep learning has its roots in the 1950s and 1960s when researchers started developing artificial neural networks as a way to model the way the brain processes information. However, it wasn't until the late 2000s that deep learning started to see significant progress and success in various applications, and there are two reasons behind the sudden growth in the field of deep learning, which are:
Increase of data: Deep learning algorithms require large amounts of labeled data to learn from, and the availability of such data has increased significantly in recent years due to the widespread adoption of the internet and devices such as smartphones and tablets etc.
Powerful computing hardware: The development of more powerful hardware, such as graphics processing units (GPUs), has made it possible to train deep learning models on large datasets, not only since as per Moore's law the cost of hardware is also decreasing thus the individuals and researchers can get started with deep learning little easier than before the 2000s.
Difference between machine learning and deep learning?
It is crucial to keep in mind the differences between deep learning and machine learning so that we can quickly determine if a given problem will be solved by deep learning or machine learning. These differences are:
Data dependency: Deep learning models typically require more data to be trained than machine learning models. So if we have less data, it is always advised to use machine learning; however, if we have large data, we must use deep learning because, beyond a certain point, machine learning models do not perform better with an increase in data.
Hardware dependency: Deep learning requires more hardware than machine learning does, and the reason for this is that it is advised to use a good GPU when training our DL model because it involves complex matrix multiplication, and if we were to use a CPU for these calculations, it would take a long time to train a model. However, as ML techniques require relatively less processing than GPU, the CPU does the job pretty well.
Interpretability: In contrast to machine learning, where we have to manually select the features on which our ML model will be trained, deep learning models themselves extract features from the data; as a result, we have no control over the features on which our DL model is being trained, making it difficult to interpret the results of deep learning models.
The fundamental unit of DL: The Perceptron
Because perceptrons are the fundamental building blocks of all neural networks, having a thorough understanding of how perceptrons work is essential to understanding the operation of simple artificial neural networks, also known as multilayered perceptrons. Therefore, let's begin our discussion.
Simply put, a perceptron is a mathematical model made up of two mathematical functions (linear and activation), where linear functions are used to model the linear relationships in the data. These functions simply add weighted inputs and bias and then transfer the result to an activation function which further takes the output from the linear function and applies a non-linear transformation to it. This allows the model to learn and model more complex relationships in the data.
There are many different types of activation functions that can be used, including sigmoid, tanh, and ReLU (Rectified Linear Unit).
In addition to the previously mentioned facts about the perceptron, weight and bias are the two crucial parameters that you should fully understand; however, we will address these two parameters in the following blog post about perceptron training.
How perceptron is similar to neurons in our brain?
In the image above, a perceptron is shown on the right, and a single neuron, which is a structure found in our brain, is shown on the left. As you can see, a neuron's dendrites (thread-like structures) receive input, followed by electrochemical reactions in the nucleus, before the output is delivered along the axon and sent to the following cell via synapses.
Similar to this, the nodes in a perceptron act as bits of information that are first given to a linear function, then pass via an activation function and ultimately pass to the following perceptron.
Perceptron: A binary classifier
A binary classifier, aka perceptron, separates the total number of data points into two zones, now to demonstrate how the perceptron functions as a binary classifier, assume that we have a student dataset with 3 columns, out of which 2 are the input features (cgpa and 12th-grade marks) and 1 is the output label (placement: yes or no). There will only be 2 input layer neurons because there are only 2 input characteristics.
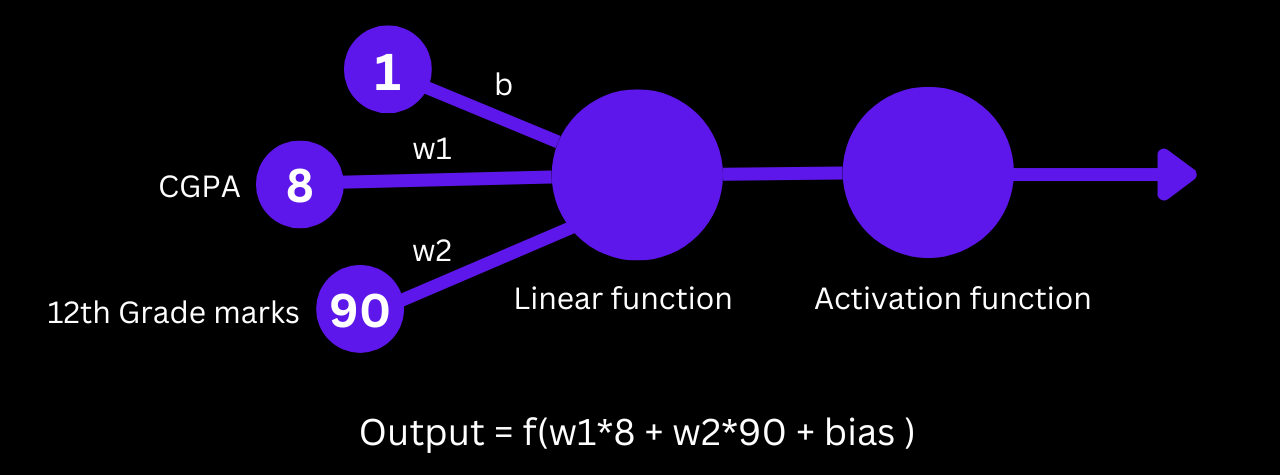
You can see from the visual above that by carefully looking at the output equation (w18 + w290 + bias), we can see the equation of the line (Ax + By + c), where w1 = A, w2 = B, x = 8, y = 90, and c = bias. Additionally, since perceptrons often use the step function as an activation function, the only output values that we can anticipate are the following:
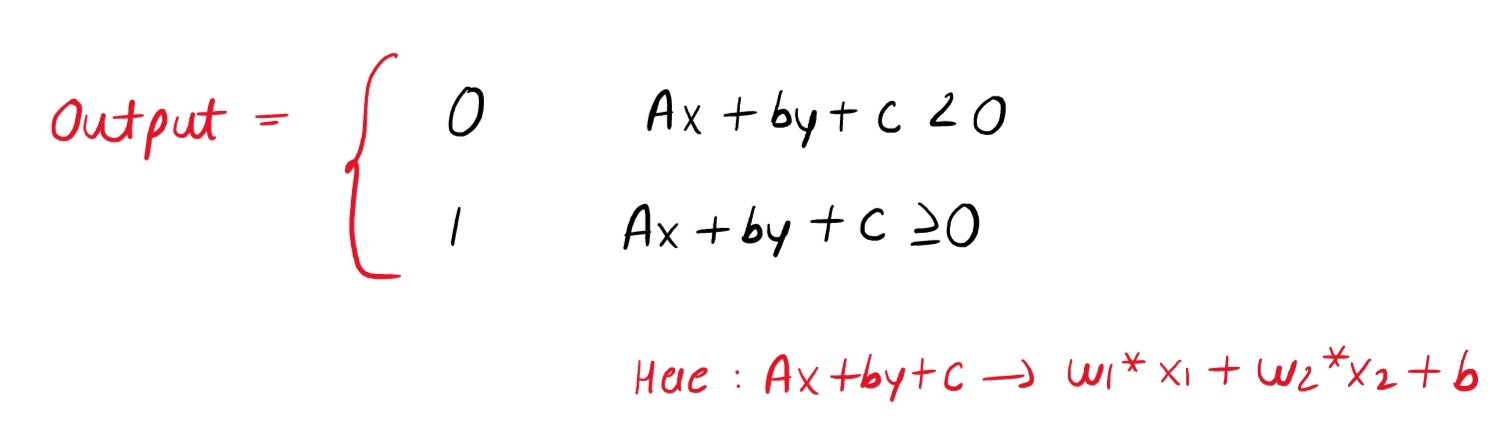
So the step function will classify a data point into one class if the output of the mathematical equation is less than 0 (negative value), and another class if the output value is more than 0 (positive value).
Finally, when we display the dataset after perceptron training, we will see that all of our data points have been divided into two zones, demonstrating that perceptron functions as a binary classifier for linear or somewhat linear data.
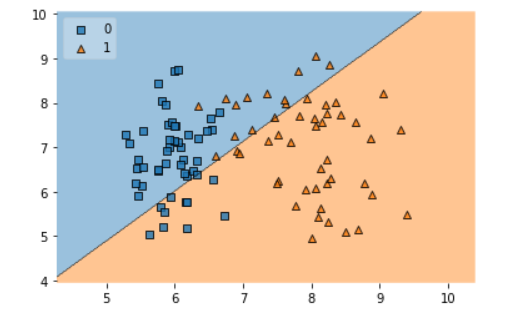
Perceptrons act as line in two-dimensional (2D) data, plane in three-dimensional (3D) data, and hyperplane in four and more dimensional data.
Short note
I hope you good understanding of what is deep learning, what are neural network in general, their comparision with biological neural networks and also about perceptron. So if you liked this blog or have any suggestions kindly like this blog or leave a comment below it would mean a to me.
Subscribe to my newsletter
Read articles from Yuvraj Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Yuvraj Singh
Yuvraj Singh
With hands-on experience from my internships at Samsung R&D and Wictronix, where I worked on innovative algorithms and AI solutions, as well as my role as a Microsoft Learn Student Ambassador teaching over 250 students globally, I bring a wealth of practical knowledge to my Hashnode blog. As a three-time award-winning blogger with over 2400 unique readers, my content spans data science, machine learning, and AI, offering detailed tutorials, practical insights, and the latest research. My goal is to share valuable knowledge, drive innovation, and enhance the understanding of complex technical concepts within the data science community.