Parquet format - A deep dive : Part 3
 Raghuveer Sriraman
Raghuveer Sriraman
Previously, we talked about how to parquet writes data. In this article, we will talk about how parquet reads data. Once again, parquet borrows from Dremel and uses its record assembly algorithm. We also talk briefly on some clever optimizations parquet does to speed up data reads.
Record assembly algorithm
The basic idea is that we need to assemble the original record from the flattened data using its repetition level and definition level.
NOTE: What is described below is based on Dremel's original paper and parquet-mr. Spark implements a vectorized parquet reader based off parquet-mr, but the code flow is slightly different from what is described here and is mentioned briefly towards the end.
Let's revisit some of the key points from part 2 that will be useful to reassemble the record:
Each data record has a tree structure with potentially multiple levels. The leaf of this structure represents the unique columns.
Data can potentially repeat.
Data can be optional.
Repetition level indicates at what "repeated" field the value as repeated.
Definition level is used to capture the level up to which optional values exist (mainly so that we can capture the levels at which a value or NULL occurs).
The final data had flattened the tree structure into columns and associated them repetition and definition levels.
In simple terms: We have a multiple lists of leaf nodes with some numbers attached to it. Therefore, to reconstruct the original hierarchy we need three things:
Access specific leaf nodes inside a list. Each list is just your column data.
Jump from list to list.
Place the nodes at the correct levels.
All we need now is to specify how to "access" lists of data, "jump" across lists and "place" the nodes.
Finite state machine
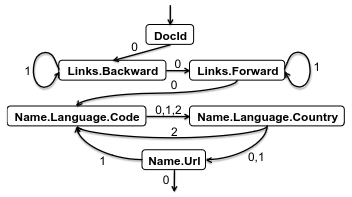
Let's visualize some of the columns and how such a jump might look like. Going with the example data from part 2 if we try to jump across columns while simultaneously trying to reconstruct the original hierarchy we can imagine doing something like this:

Even in this simplified example, rules for parsing seem to be emerging:
Go through the columns in the same order as it is in the schema.
When a "0" is encountered in the repetition level, move to the next field.
Otherwise drain all the data which has a common repetition level.
In the above example, we go from Links.Backward to Links.Forward column with RL of 1, and drain all these fields of the same RL. Once that is over, we move to RL of 0. At which point we observe its value and move to the next field.
And what about definition level? Recall that DL helps know if there are NULL values along the path of the node, and if there are optional values along the path. Which means, with DL we can know the depth of the node in the record we are building, especially given that we know the maximum definition level depth directly from the schema.
Summarizing and drawing parallels from the previous section:
Use schema to get the column order, maximum definition level.
Use RL to go from column to column.
Use DL at runtime and max definition levels to place the node.
The full state machine for the example data, taken from the Dremel paper:
Notable optimizations
When dealing with large dataset, we need to think of improving compute time. Most of the tricks below try to accomplish this in one way or another.
Predicate pushdown
This is a fairly common optimization borrowed from databases. The idea is that instead of gathering the results and then filtering, we attempt to pushdown the conditions so that the data is filtered at the lower layers before gathering them.
Fun fact: I was curious how old this technique is and a casual search on google scholar led to this paper[1] which references predicate pushdown to one of Jeffrey Ullman's[2] book from 1989!
Filtering row groups
Parquet can use the block metadata which allows it to skip over whole pages of data. It does this mostly through two important interfaces called ColumnIndex and OffsetIndex. Briefly, the metadata has statistics such as min, max values, null counts which allows parquet to scan through the data and skip pages. The original issue link[3] and a corresponding google doc[4] make for interesting reads.
Partial aggregation (Spark)
If the requested query has aggregations, then can choose to perform partial aggregations by using Parquet's column statistics instead of returning rows to Spark and aggregating upstream. This way, compute is saved and data movement also reduces.
Vectorized reader (Spark)
Spark has a vectorized reader implementation (enabled through spark.sql.parquet.enableVectorizedReader configuration setting) to read parquet data which according to the docs is based off the code in parquet-mr but it's Spark own implementation of the read operation. The basic principle is that in the vectorized approach it reads columnar data in batches, instead of the non-vectorized approach which follows a more iterative style approach to loading data. But there is a lot more to vectorized style of data processing and it can go quite low level. For more, refer to this talk[5] and this video[6] (both are from Databricks).
Summary
In short, we covered how recreate the flattened record from the repetition level and definition levels captured earlier. We also saw some tricks parquet uses to speed up its reads, the driving idea being to find ways to only process as much data as required and no more.
References
[1] Query Optimization by Predicate Move Around
[2] Jeffrey Ullman
[3] PARQUET-922 Jira issue
[4] PARQUET-922: SortColumnIndex Layout to Support Page Skipping
[5] Recent Parquet Improvements in Apache Spark
[6] Enabling Vectorized Engine in Apache Spark
Subscribe to my newsletter
Read articles from Raghuveer Sriraman directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Raghuveer Sriraman
Raghuveer Sriraman
Working mostly on Data Engineering, Machine Learning and Bayesian analytics.