Cache Stampede: A Problem The Industry Fights Every Day
 Zahiruddin Tavargere
Zahiruddin Tavargere
In 2010, Facebook, with 600+ Million users, was already one of the most popular and biggest websites in the world.
On September 23, 2010, their scale and limits were put to the test as it faced one of its most severe outages to date.
Facebook was down for more than 2.5 hours.
The reason. A bad configuration change led to a swarm of requests being funneled to their databases.
Today we made a change to the persistent copy of a configuration value that was interpreted as invalid. This meant that every single client saw the invalid value and attempted to fix it. Because the fix involves making a query to a cluster of databases, that cluster was quickly overwhelmed by hundreds of thousands of queries a second*.*
To make matters worse, every time a client got an error attempting to query one of the databases it interpreted it as an invalid value, and deleted the corresponding cache key. This meant that even after the original problem had been fixed, the stream of queries continued. As long as the databases failed to service some of the requests, they were causing even more requests to themselves. We had entered a feedback loop that didn’t allow the databases to recover.
For companies with a global presence, or with a very large user base, this is a common problem - and the engineers there fight this on a daily basis.
The problem is called Cache Stampede.
What is a Cache Stampede?
Let’s simplify it.
Assume that the data source is a SQL server database. The cached data is in Redis, and the time to live is 5 minutes.
...
public static object GetValue(string key, string sql)
{
object value = GetFromCache(key);
if (value == null)
{
value = QueryDb(sql);
SetToCache(value, timeout: 60);
}
return value;
}
...
In that 5-minute duration, all the requests to the web app are served data from the cache. After the 5-minute duration, when the object expires, the requests are routed to the database.
The database returns the data, and in the process, the cache is updated again.

It’s peak time, and the application is seeing a sudden influx of requests.
After the 5-minute duration, the cache object expires. All the requests are now routed to the database to serve. This puts an extreme load on the database servers.
The database starts blocking the requests before possibly going down.
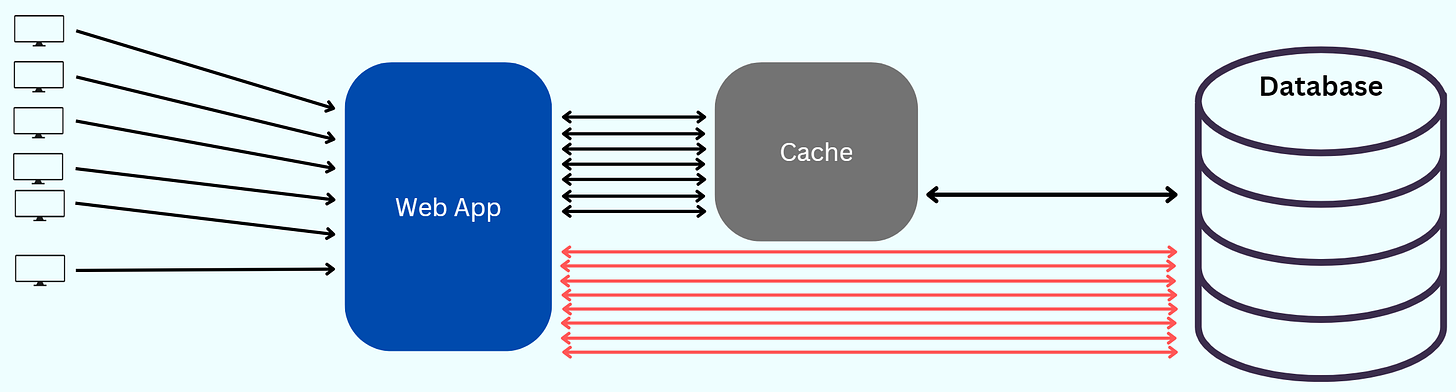
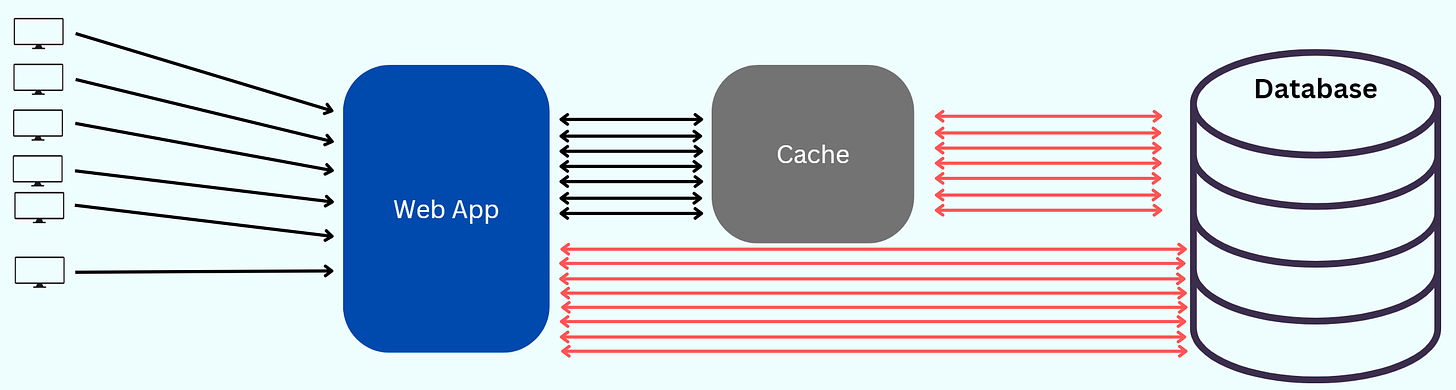
This phenomenon can be called "Cache Stampede", and it is sometimes referred to as a Dog-Piling.
A cache stampede occurs when multiple attempts to write the same data to the cache happen concurrently.
This worsens as additional requests overload the server, causing a self-reinforcing cascade of more requests and slower performance.
What are the reasons for Cache Stampede?
Cache item expiration or deletion: When a cached item expires or is deleted, multiple requests can see a cache miss and attempt to regenerate the resource simultaneously, leading to a cache stampede.
Cache cold start: When the cache is empty or has not been populated yet, all the requests will miss the cache, and the system will have to generate the resources from scratch, leading to a cache stampede.
Cache invalidation: When a cached item is invalidated due to changes in the underlying data, all the requests that depend on that item will miss the cache and attempt to regenerate the resource simultaneously, leading to a cache stampede.
Cache synchronization: In a distributed caching system, when the cache nodes need to synchronize their data, all the requests can miss the cache simultaneously, leading to a cache stampede.
How can we mitigate this Cache Stampede problem?
Some obvious solutions that one can think of are...
Distributed Caching and Load Balancing: Store cached data strategically across regions.
Proactive Cache Updates: Update cache every time there is a write to the database.
Rate Limiting
However, the recommendations in the whitepaper Optimal Probabilistic Cache Stampede Prevention make absolute sense.
External re-computation: Instead of recreating cache items when they expire, there is a separate process that periodically recreates them in the background. The drawbacks though are additional maintenance of the daemon job and unnecessary consumption of resources when cache regeneration was not required.
Locking: Upon a cache miss, a request attempts to acquire a lock for that cache key and regenerates the item only if it acquires it.
Probabilistic early expiration: Each individual request may regenerate the item in the cache before its expiration by making an independent probabilistic decision. The probability of performing an early expiration increases as the request time gets closer to the expiration of the item
Conclusion
Cache Stampede is not a common problem for most companies, but if you are working at big tech or a startup that is scaling fast, then this a concept you should definitely dive deep into.
Each technique and tool discussed here has its own advantages and disadvantages, depending on the context and requirements of the system. Therefore, it is important to understand the trade-offs and choose the best solution for your system.
I write about System Design, UX, and Digital Experiences. If you liked my content, do kindly like and share it with your network. And please don't forget to subscribe for more technical content like this.
Below are some of my popular posts...
Subscribe to my newsletter
Read articles from Zahiruddin Tavargere directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Zahiruddin Tavargere
Zahiruddin Tavargere
I am a Journalist-turned-Software Engineer. I love coding and the associated grind of learning every day. A firm believer in social learning, I owe my dev career to all the tech content creators I have learned from. This is my contribution back to the community.