The Secrets of MySQL Query Execution Plans
 Krishnaraj Venkatesan
Krishnaraj Venkatesan
Are your MySQL queries not performing as well as expected?
Understanding the various execution plans provided by the MySQL query planner can significantly improve your database's performance. In this blog, we'll discuss different execution plans for various types of queries.
Example Table - Payments
To illustrate these concepts, we'll use a simple table named "payments."
CREATE TABLE payments (
id INT AUTO_INCREMENT PRIMARY KEY,
amount DECIMAL(10, 2) NOT NULL,
name VARCHAR(100) NOT NULL
);
This table contains over a million records, which we'll use to examine query execution plans.
mysql> select count(*) from payments;
+----------+
| count(*) |
+----------+
| 1234567 |
+----------+
We'll use explain and analyze provided by MySQL to examine the queries.
Full Table Scan
It is typically used when no suitable index is available for the query conditions.
It occurs when the query needs to examine every row in a table to find the required results.
Full table scans can be slow and resource-intensive, especially for large tables.
Example
Let's consider a query to fetch all payments for a customer
Note: The table does not have any index on the column name.
mysql> explain select * from payments where name = 'AA';
+----+-------------+----------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | payments | NULL | ALL | NULL | NULL | NULL | NULL | 1232269 | 10.00 | Using where |
+----+-------------+----------+------------+------+---------------+------+---------+------+---------+----------+-------------+
There are no possible keys matching the criteria. The "rows" value (1232269) implies that it has to process almost the entire table to execute the query.
mysql> explain analyze select * from payments where name = 'AA';
| -> Filter: (payments.`name` = 'AA') (cost=123860 rows=123227) (actual time=39.9..242 rows=7136 loops=1)
-> Table scan on payments (cost=123860 rows=1.23e+6) (actual time=0.0849..173 rows=1.23e+6 loops=1)
|
It means it has to do the table scan on "payments" for almost the entire rows=1.23e+6 and then apply the "name" filter, resulting in around 7136 rows.
Index Scan
An index scan occurs when the query optimizer uses an index to fetch data instead of performing a full table scan.
Index scans are much faster than full table scans for queries that can utilize appropriate indexes.
Example
Let's create an index on the column name
mysql> CREATE INDEX idx_payment_name
-> ON payments (name);
Query OK, 0 rows affected (2.11 sec)
Records: 0 Duplicates: 0 Warnings: 0
And analyze the same query
Before analyzing, let's see the count that matches our filter condition.
mysql> select count(*) from payments where name = 'AA';
+----------+
| count(*) |
+----------+
| 7136 |
+----------+
mysql> explain select * from payments where name = 'AA';
+----+-------------+----------+------------+------+------------------+------------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+------------------+------------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | payments | NULL | ref | idx_payment_name | idx_payment_name | 402 | const | 7136 | 100.00 | NULL |
+----+-------------+----------+------------+------+------------------+------------------+---------+-------+------+----------+-------+
The key used here is idx_payment_name It can find all 7136 rows from the index directly without any extra filter.
mysql> explain analyze select * from payments where name = 'AA';
| -> Index lookup on payments using idx_payment_name (name='AA') (cost=2498 rows=7136) (actual time=0.694..29.6 rows=7136 loops=1)
|
As you can see, there is no filter involved. It can fetch all matching criteria from the index "idx_payment_name" and then fetch the row data from the table data.
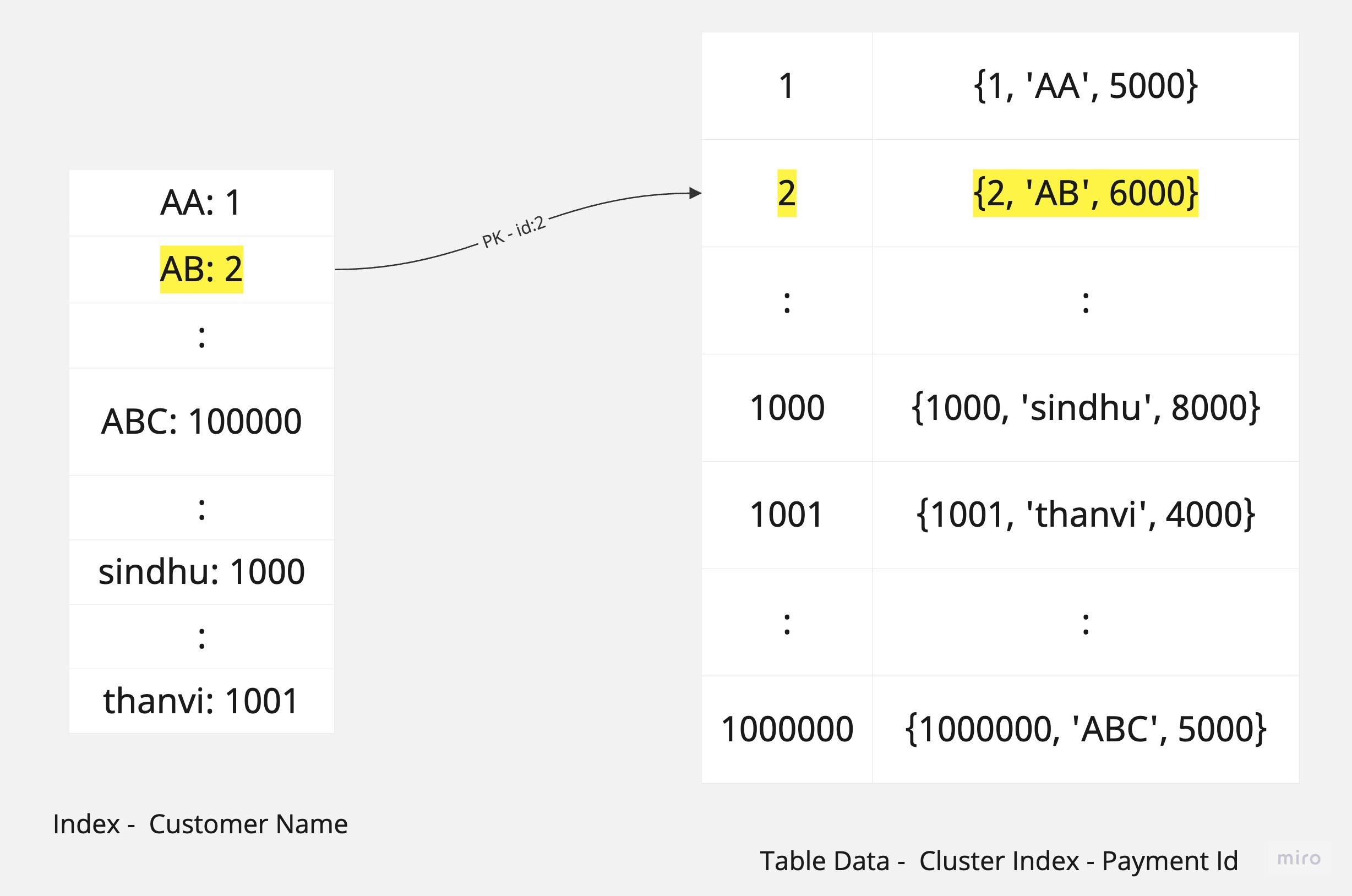
Covering Index Scan
A covering index scan (can also be called an index-only scan) is more performant than an index scan.
It happens when the query can retrieve all the required data directly from the index without accessing the actual table data. In this case, the index "covers" all the columns needed for the query.
It avoids disk reads and reduces I/O, making it highly efficient for queries where the necessary data is entirely present in the index.
Example
In the same query, let's fetch only the id, and name instead of fetching all the values in the table data.
mysql> explain select id, name from payments where name = 'AA';
+----+-------------+----------+------------+------+------------------+------------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+------------------+------------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | payments | NULL | ref | idx_payment_name | idx_payment_name | 402 | const | 7136 | 100.00 | Using index |
+----+-------------+----------+------------+------+------------------+------------------+---------+-------+------+----------+-------------+
The key used here is "idx_payment_name." It can find all 7136 rows from the index directly without any extra filter and it can fetch all the data ("id," "name") required for the query directly from the index.
mysql> explain analyze select id, name from payments where name = 'AA';
| -> Covering index lookup on payments using idx_payment_name (name='AA') (cost=1054 rows=7136) (actual time=0.522..4.78 rows=7136 loops=1)
|
Note the mention of the covering index using the index "idx_payment_name." It can fetch all matching rows and data ("id," "name") required from the index. No additional filters are involved.
Index Range Scan
It occurs when the query needs to retrieve a range of rows based on a range of values in the indexed column(s)
Typically happens when a query is executed with conditions involved with range operators like
>, <, BETWEENBased on factors like data distribution, and query cost estimation the query optimizer may decide not to use an index range scan even if it finds an index on the column.
Example
Let's consider a query to select all payments having id between a range.
And here's the count
mysql> select count(*) from payments where id > 986032 and id < 996032;
+----------+
| count(*) |
+----------+
| 9999 |
+----------+
mysql> explain select * from payments where id > 986032 and id < 996032;
+----+-------------+----------+------------+-------+---------------+---------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+-------+---------------+---------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | payments | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 19026 | 100.00 | Using where |
+----+-------------+----------+------------+-------+---------------+---------+---------+------+-------+----------+-------------+
The primary key is used here. It needs to scan through 19026 rows to fetch the matching 9999 rows by doing an extra filter using the where condition.
mysql> explain analyze select * from payments where id > 986032 and id < 996032;
| -> Filter: ((payments.id > 986032) and (payments.id < 996032)) (cost=3810 rows=19026) (actual time=0.138..12.8 rows=9999 loops=1)
-> Index range scan on payments using PRIMARY over (986032 < id < 996032) (cost=3810 rows=19026) (actual time=0.13..11.1 rows=9999 loops=1)
|
As you can see, first it scans through 19026 rows using the primary key and then it filters 9999 rows matching the condition.
Clustered Index Scan
It occurs when queries fetch rows based using the primary index. In MySQL, the primary key index is usually implemented as a clustered index.
The clustered index scan is generally efficient because it fetches rows in the order of the clustered index, which reduces the need for extra disk seeks (I/O).
Example
Let's fetch the first 100 payments ordered by the "id".
mysql> explain select * from payments order by id limit 100;
+----+-------------+----------+------------+-------+---------------+---------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+-------+---------------+---------+---------+------+------+----------+-------+
| 1 | SIMPLE | payments | NULL | index | NULL | PRIMARY | 4 | NULL | 100 | 100.00 | NULL |
+----+-------------+----------+------------+-------+---------------+---------+---------+------+------+----------+-------+
As you can see, the primary key (here, the clustered index) is used here to fetch all 100 rows, and there is no additional seek required to fetch table data for the matching records.
mysql> explain analyze select * from payments order by id limit 100;
| -> Limit: 100 row(s) (cost=0.0522 rows=100) (actual time=1.28..1.31 rows=100 loops=1)
-> Index scan on payments using PRIMARY (cost=0.0522 rows=100) (actual time=1.27..1.3 rows=100 loops=1)
|
The primary index is used to fetch all the matching 100 rows
Full index scan
It occurs if the query uses an index but requires to scan through every entry in the index to fetch the required results.
It may be faster than a full table scan since it operates on a smaller dataset (only the index entries and not the entire table which is too big!)
However, it will still incur significant I/O if the index is large.
And there will be additional I/O required to fetch the table data if the index does not contain all the required columns.
Example
Let's select all payments belonging to customers having a name that contains "aa"
mysql> explain select id, name from payments where name like '%aa%';
+----+-------------+----------+------------+-------+---------------+------------------+---------+------+---------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+-------+---------------+------------------+---------+------+---------+----------+--------------------------+
| 1 | SIMPLE | payments | NULL | index | NULL | idx_payment_name | 402 | NULL | 1232269 | 11.11 | Using where; Using index |
+----+-------------+----------+------------+-------+---------------+------------------+---------+------+---------+----------+--------------------------+
mysql> explain analyze select id, name from payments where name like '%aa%';
| -> Filter: (payments.`name` like '%aa%') (cost=123860 rows=136905) (actual time=8.64..271 rows=7259 loops=1)
-> Covering index scan on payments using idx_payment_name (cost=123860 rows=1.23e+6) (actual time=0.227..198 rows=1.23e+6 loops=1)
|
As it is clearly seen, it almost scans through all the rows 1232269 in the "idx_payment_name" index and then applies the filter using the where condition to fetch matching 7259 rows.
Full Table Scan
The full table scan is the least performant scan method.
It occurs when the query needs to examine every row in the table to find the required results.
Full table scans are resource-intensive, especially for large tables, and should be avoided.
Example
Let's use the same query but this time, we will fetch all table data.
mysql> explain select * from payments where name like '%aa%';
+----+-------------+----------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | payments | NULL | ALL | NULL | NULL | NULL | NULL | 1232269 | 11.11 | Using where |
+----+-------------+----------+------------+------+---------------+------+---------+------+---------+----------+-------------+
You can see, the query optimizer ignored the index on the name and decide to scan through the entire table using the table cluster.
mysql> explain analyze select * from payments where name like '%aa%';
| -> Filter: (payments.`name` like '%aa%') (cost=123860 rows=136905) (actual time=6.11..285 rows=7259 loops=1)
-> Table scan on payments (cost=123860 rows=1.23e+6) (actual time=0.521..215 rows=1.23e+6 loops=1)
|
It has to do a full table scan and applies the filter to fetch the required 7259 rows
Using Filesort
The "Using Filesort" in the query plan indicates that MySQL needs to perform an external sort operation to complete the query.
It is usually seen in queries with
ORDER BYclauses that can't be satisfied by an existing index.
Example
Let's fetch the first 100 payments ordered by the amount column which is not part of the index.
mysql> explain select * from payments order by amount limit 100;
+----+-------------+----------+------------+------+---------------+------+---------+------+---------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+---------+----------+----------------+
| 1 | SIMPLE | payments | NULL | ALL | NULL | NULL | NULL | NULL | 1232269 | 100.00 | Using filesort |
+----+-------------+----------+------------+------+---------------+------+---------+------+---------+----------+----------------+
mysql> explain analyze select * from payments order by amount limit 100;
| -> Limit: 100 row(s) (cost=123860 rows=100) (actual time=356..356 rows=100 loops=1)
-> Sort: payments.amount, limit input to 100 row(s) per chunk (cost=123860 rows=1.23e+6) (actual time=356..356 rows=100 loops=1)
-> Table scan on payments (cost=123860 rows=1.23e+6) (actual time=0.377..223 rows=1.23e+6 loops=1)
|
First, it scans through the entire table data and then orders them using the column amount using external file sort to fetch the required 100 rows.
To conclude, As developers, it is important to continually monitor and fine-tune queries to adapt to changing data and query patterns. Understanding query execution plans by leveraging the insights provided by EXPLAIN and ANALYZE will help you improve your queries for better performance.
Thank you for taking the time to read up to this point. I hope you found the information shared here to be insightful and helpful.
Your feedback is invaluable to me, and I would greatly appreciate hearing your thoughts on the content. If you found it useful, don't hesitate to show your appreciation by clicking the heart button.
Happy reading, and I look forward to bringing you more exciting content in the future!
Subscribe to my newsletter
Read articles from Krishnaraj Venkatesan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Krishnaraj Venkatesan
Krishnaraj Venkatesan
Principal Software Engineer at Chargebee. Expert in Java, Database, Integrations, and cloud. Passionate about technology to solve business problems.