Impurity in Decision Trees: A Beginner's Guide
 Yuvraj Singh
Yuvraj Singh
I hope you are doing great so today we will discuss about some importatnt topics related to decision tree algorithm and these topics are concept of impurity and measures of impurity in decision tree. Wihtout any further delay let's get started
Introduction to Decision Trees
Decision tree is a supervised machine learning algorithm that is used to solve both classification as well as regression problems and because of this unique property of this algorihtm, it is also known as CART i.e. classification and regression tree. Now before moving on to indepth understanding of working of decision tree, let me give you a simple overview of how decision tree works.
What is stopping criterion ?
In the overview of working of decision tree above I mentioned about stopping criterion so let's make this clear at the start what does this mean and what commonly used stopping criterion for classification and regression problem.
Stopping criterion is like a condition which if gets satisfied we simply stop the further expansion/growth of the decision tree, it is like setting up a bounding function for decison tree. Now let's see what is most commonly used stopping criterion for classification and regression problems.
| Stopping Criterion | Classification Problem | Regression Problem |
| Maximum Depth | Limits the depth of the tree to control model complexity | Limits the depth of the tree to control model complexity |
| Minimum Data Points | Stops splitting if the number of data points is below a specified threshold | Stops splitting if the number of data points is below a specified threshold |
| Impurity Threshold | Stops splitting if the impurity (e.g., Gini impurity or entropy) falls below a specified threshold | Not applicable |
| Information Gain Threshold | Stops splitting if the information gain falls below a specified threshold | Not applicable |
| Variance Reduction Threshold | Not applicable | Stops splitting if the reduction in variance falls below a specified threshold |
Concept of impurity in decision trees
While studying about decision tree from any of the resource you would often hear a particular term called "impurity" now instead of directly jumping on to discussing the technqiues used to measure impurity let us first understand what does impurity actaully means in the context of solving classification problems using decision trees.
In the context of classification impurity basically means the measure of homogeneity within the class labels like after splitting the parent dataset into the child datasets we want that the randomness or disorder withing the class labels of the child datasets must be reduced leading to increase in homogeneity.
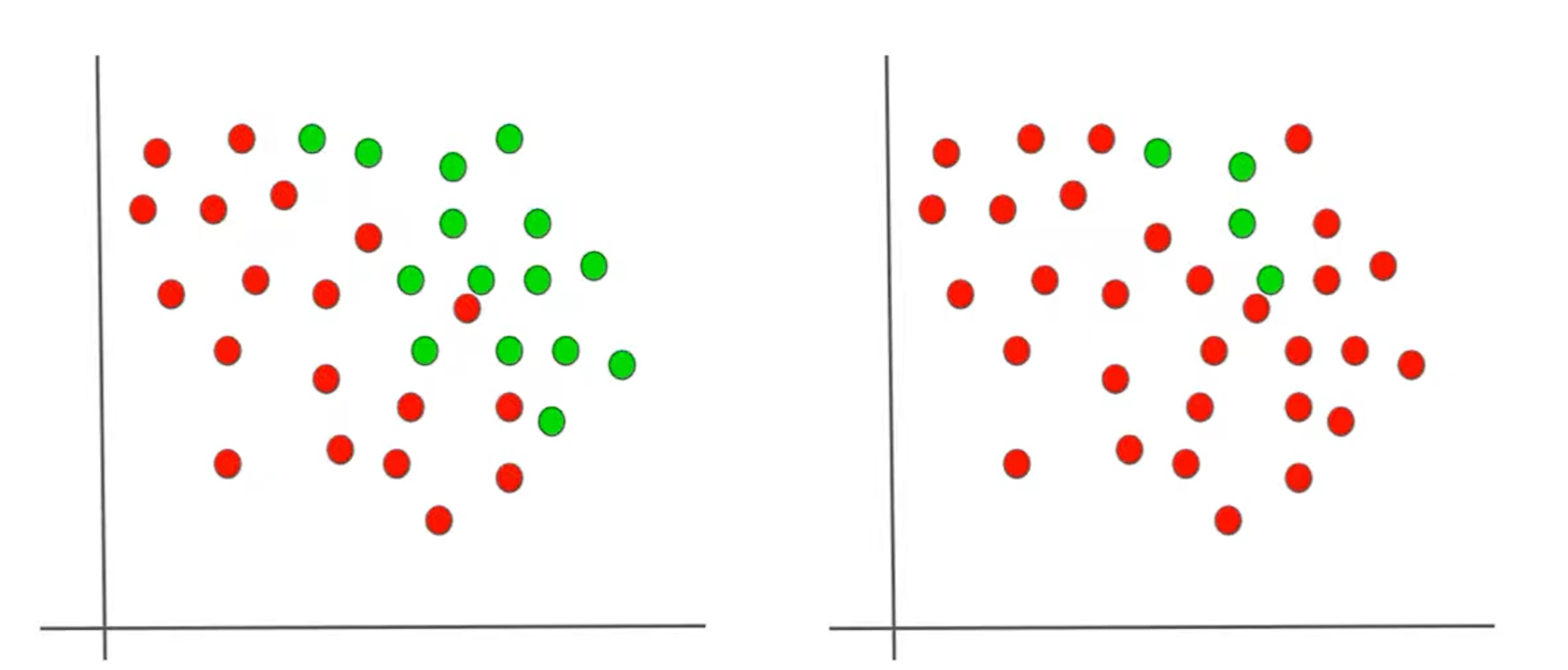
Small test for checking your understanding
Let's me take a small test of yourself about your understanding of the concept of impurity of homogeneity. Take a look at the 2 data distributions below and answer which one will be having more entropy ?
Measures of impurity
As we just discussed about the concept of impurity in decision trees in the context of classification and regression let us now talk about an important measure of impurity/homegeneity for classification problems gini impurity and entropy. In the coming couple minutes we will take a look at
How to calculate gini impurity and entropy ?
Which measure to use when ?
Gini impurity
Gini impurity also called "Gini index" is a measure of impurity of homgeneity used in decision tree. Mathematically gini impurity or gini index is defined as
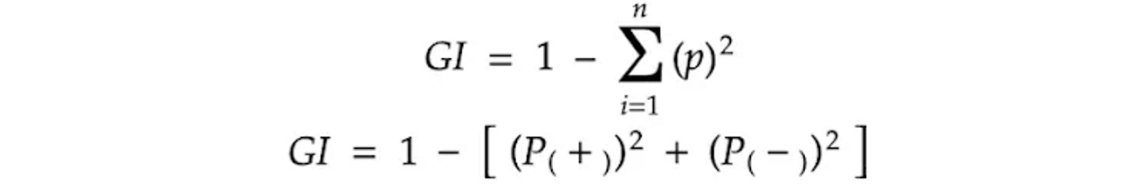
Now to better understand this let us consider a dataset and in that dataset we will calculate the gini impurity.
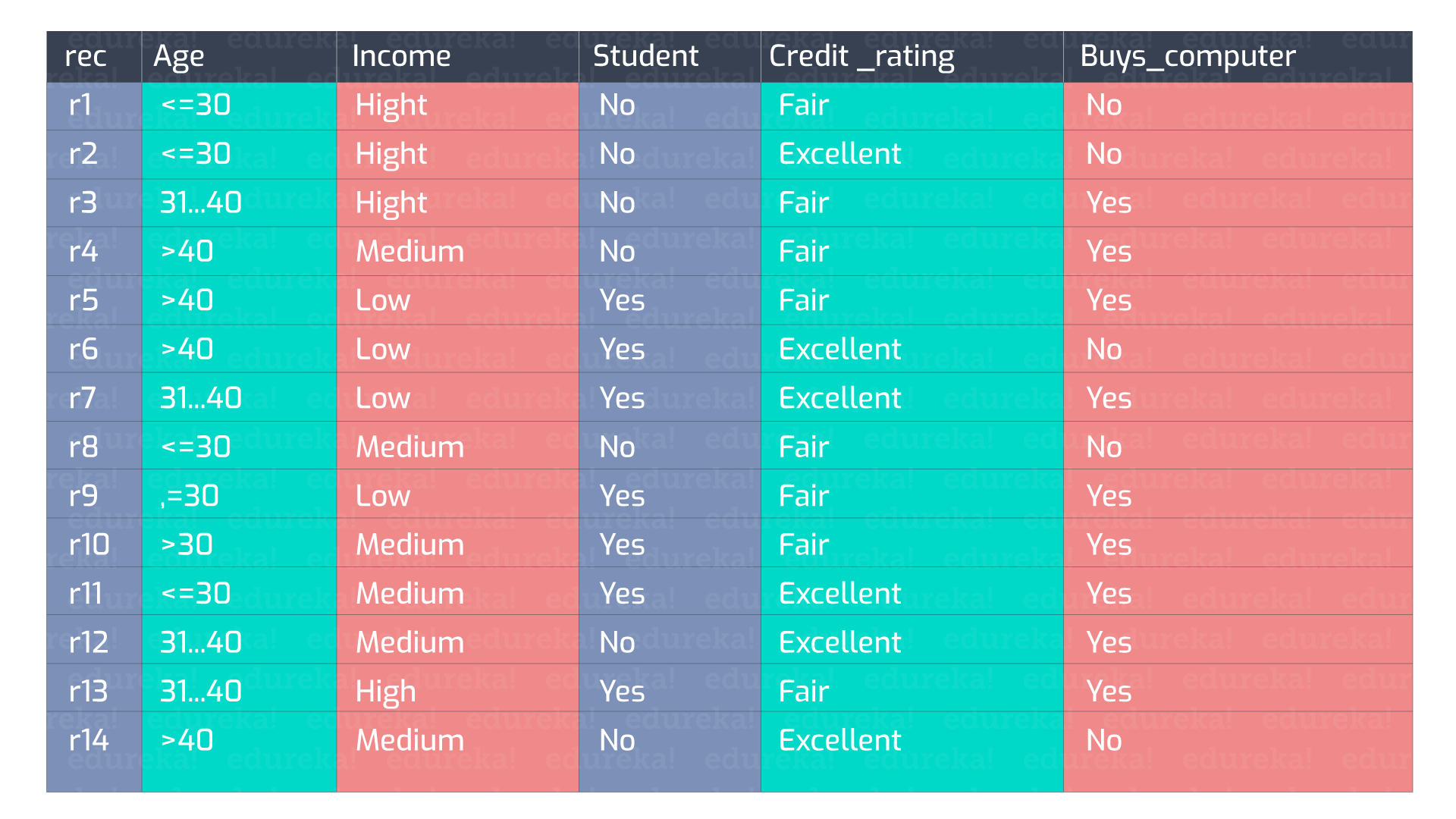
In the above dummy dataset we have 5 main features ( ignoring the rec ) and out of these 5 features the Buys_computer is our target label having 2 classes No and Yes. So in this case this case there will be 2 unqiue values for p i.e. p(Yes) and p(No)

Entropy
Just like gini impurity entropy is also a measure of impurity or homogeneity, mathematicall entorpy is defined as
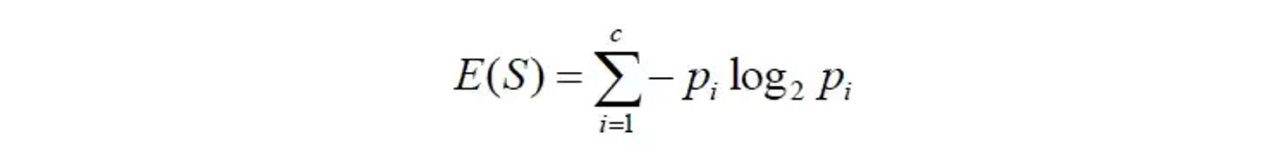
Now again to get better understanding of how to calculate entropy let us take the above dummy dataset and calculate entropy for that dummy dataset.
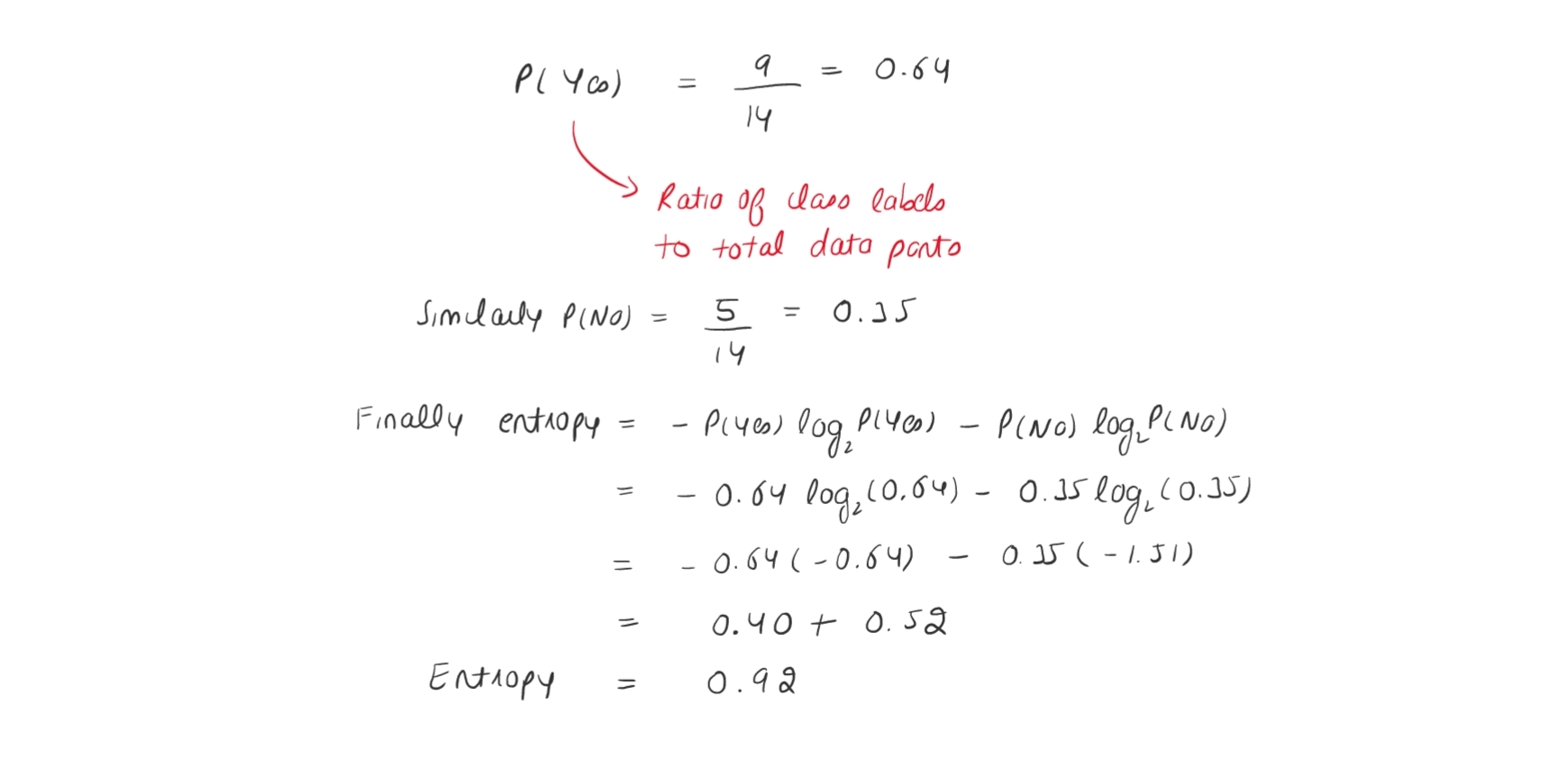
How to decide wheter to use gini or entropy
The answer to this question is that it is totally based on the data which you are having at hand, for smaller dataset you can use gini as well as entropy as measure of impurity but for the larger dataset it is always recommended to use the gini impurity and the reason is that in case of entropy is computatinally expensive because logbase 2 is involved in the mathematical expression and due to this log the overall computation could take a good amount of time, whereas in case of gini the computation is less for calulcating the impurity thus better for larger dataset.
Short note
I hope you good understanding of what are decision trees, what is the conept of impurity and what are the ways to measure impurity. So if you liked this blog or have any suggestions kindly like this blog or leave a comment below it would mean a to me.
Subscribe to my newsletter
Read articles from Yuvraj Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Yuvraj Singh
Yuvraj Singh
With hands-on experience from my internships at Samsung R&D and Wictronix, where I worked on innovative algorithms and AI solutions, as well as my role as a Microsoft Learn Student Ambassador teaching over 250 students globally, I bring a wealth of practical knowledge to my Hashnode blog. As a three-time award-winning blogger with over 2400 unique readers, my content spans data science, machine learning, and AI, offering detailed tutorials, practical insights, and the latest research. My goal is to share valuable knowledge, drive innovation, and enhance the understanding of complex technical concepts within the data science community.