Incremental DB migration with Hasura
 Community Hasura
Community HasuraDatabase migration is a complex, multiphase, multi-process activity. The challenges scale up significantly when you move to a new database vendor or across different cloud providers or data centers.
Despite the challenges, sometimes data migration is the only way. So how do we peel back the layers of ambiguity, keep the downtime minimal, and ensure our user’s experience does not suffer when embarking on this journey?
I had faced a similar change in the past when I was at one of Asia/India’s largest e-commerce shops. Our database storage and compute capacity had maxed out, we were using ~90%+ of our compute resources, and we had about two months left before running out of storage space.
We had to act fast and execute the entire process within that two-month period while ensuring our business continued to grow. It was a stressful period with some leap-of-faith calculations to make it happen.
In this post, I want to revisit the migration process and see how, with Hasura, we could incrementally execute the migration, tackling the uncertainties but still delivering the results on time.
The problem
We want to migrate data from one SQL database to another SQL database vendor on the cloud, and we want to achieve this process with minimal disruption.
The challenges
What are the typical challenges we must solve for when moving to a new database vendor?
Database schema migration
Usually, there are differences in data types, index types, and architectures between different vendors that need to be addressed before starting the migration.
Some characteristics need functional/performance testing to be sure.
These differences arise even if we move to a different vendor for the same types of databases (E.g., MySQL to PostgreSQL).
However, these differences further magnify when moving from SQL to NoSQL store, where write and access pattern change considerably due to schema/schema-less changes.
Data transformation
Due to changes in schema and data types, one would need to transform the data before persisting.
These ETL pipelines can become complex, as we need to reason schema by schema.
It can be a mammoth task if the table count is large (20+) with a large amount of data.
Data migration
This step could be challenging if the databases are co-located or on different cloud providers.
Inside the same data centers, the network bandwidth is usually plenty to move 100s of GB of data in a few mins to a few hours.
However, the same cannot be said for migrating the data over the internet, there are many failure scenarios to consider, and the time it takes can be a couple of days.
Performance/functional testing
If one is migrating all the data simultaneously, testing the new database’s migration and functionality/performance is paramount.
There could be a need for tweaking data types, indexes, or queries that might not work from older databases.
This step requires a thorough review of the data modeling, and the application code, specific queries, and consistency guarantees must change when undertaking such migrations.
API migration
When migrating data across databases, data access patterns with existing APIs become crucial.
If it’s a migration across a couple of days or weeks, some requests must be handled while pointing to the new database vendor, while prior data access must be redirected to the older database.
If the data is being asked in multiple databases, we must handle cross-DB queries/joins.
For writes, moving partial data could be challenging, as new inserts have to be written in the new datastore, while updates for old rows have to be redirected to the old DB for consistency.
However, if one moves entire tables to the new database, the data access layer can handle many such challenges.
An approach to solving DB migration challenges
Given the challenges above, how do we go about this problem statement?
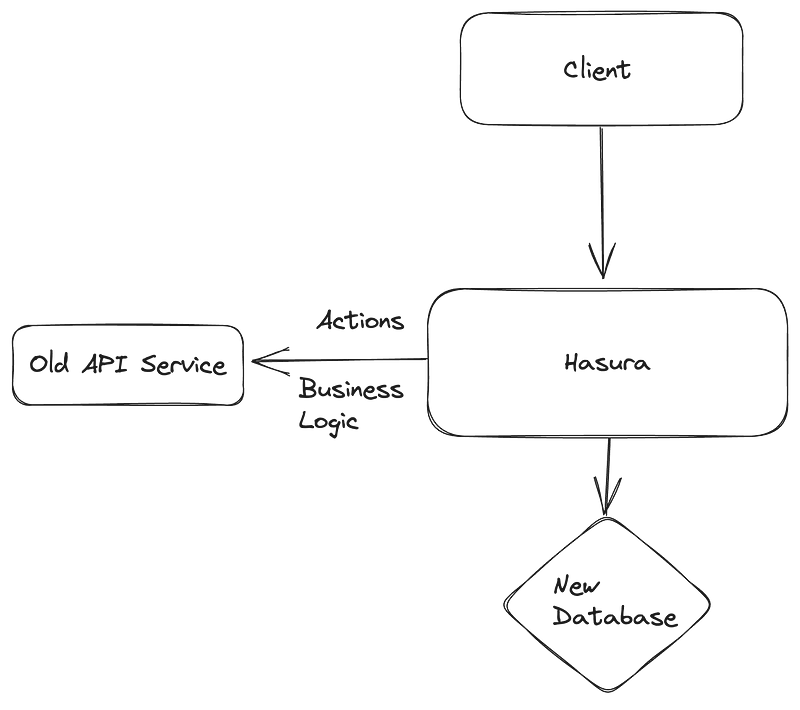
First, the data migration problem is also an API migration problem. If we can provide the flexibility of querying multiple data sources while running existing business logic, we can support migrations using an incremental approach.
Her are the steps, using Hasura, to help address the uncertainties:
Introduce Hasura and connect it to the old database.
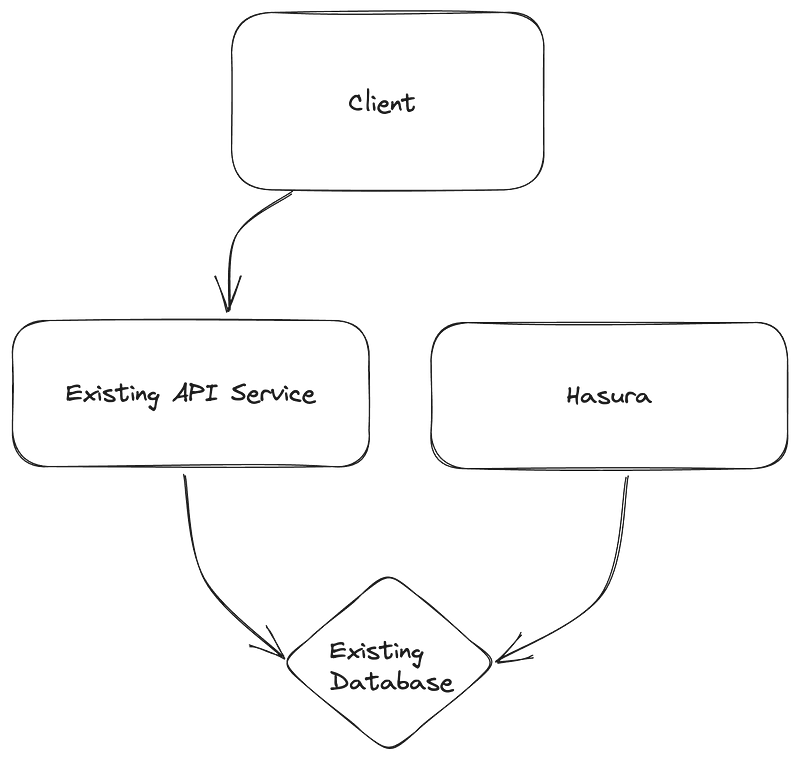
Connect existing API service with Hasura.
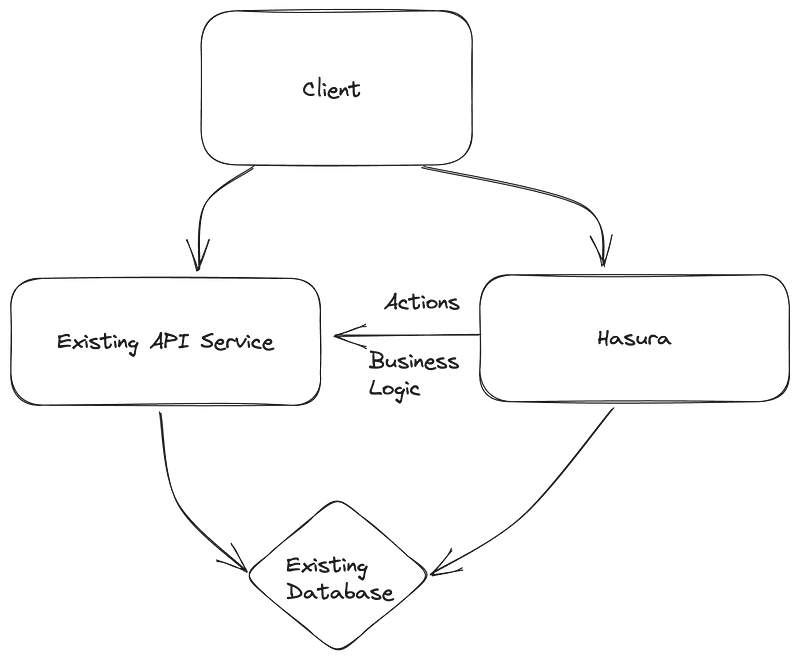
The existing APIs will become a source of business logic and data validation for Hasura, and with that, we can start migrating some of the client API calls to Hasura.
For GraphQL, we can use remote schemas, and for REST APIs, we can use actions.
Once we’ve migrated some client API calls, we can slowly move all clients to Hasura. Post that, we can start replicating some table schemas to the new database vendor. There are many ways to replicate data across different data sources.
Once those tables have been replicated successfully and after conducting functional and performance tests over the new data source, we can connect Hasura with the new database.
Connect Hasura to the new database.
Make remote joins across databases.
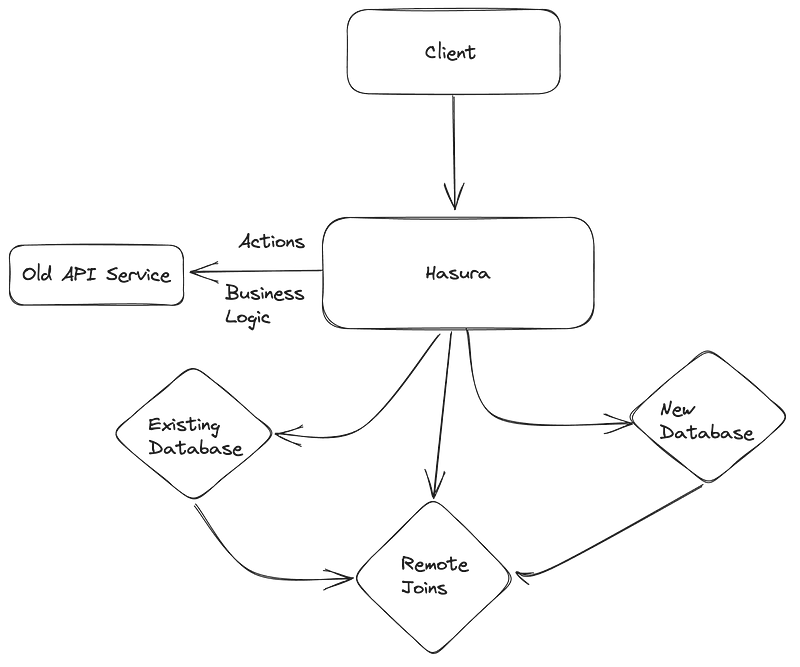
Remove old data sources from Hasura.
Conclusion
We saw how using Hasura, we could have a clear strategy for migrating API, which allowed us to move data to the new vendor incrementally while causing minimal client disruptions.
Using this approach, we can easily guard against any uncertainties that may arise when moving to a new database vendor while providing a fantastic experience to our API consumers.
Sign up now for Hasura Cloud and get started for free!
Originally published at https://hasura.io on July 24, 2023.
Subscribe to my newsletter
Read articles from Community Hasura directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by