Gzip vs. Brotli - Balancing CPU Usage and Network Bandwidth"
 Hooman Pegahmehr
Hooman Pegahmehr
I am delighted to share another anecdote from my freelancing experience on Fiverr. The task involved my collaboration with a developer for a seemingly straightforward job - merging records possessing the same identification numbers. These records, exported from ServiceFirst, contained repetitions due to multiple service offerings.
I recommended undertaking the task of consolidation at the backend before any new data feed was introduced. Despite this, the client inexplicably insisted that this code run on the client side. As a result, a voluminous JSON file would be transferred from the server every time a client visited the site, and the record merging process would take place at the expense of the end user's time and browser CPU resources.
I chose not to contest the client's imprudent request. Instead, I complied with their specifications, despite the inherent inefficiency. I strongly advocate for handling as much data processing as possible at the backend, thereby preventing the unnecessary burden on the end user's browser due to superfluous code.
I found myself contemplating the significant difference in the user experience if the client had agreed to compress the sizable ServiceFirst export at the very least. To test my hypothesis, I decided to experiment with a large JSON file, compressing it to evaluate the potential benefits.
Brotli and Gzip are both popular compression algorithms used to reduce the size of files and improve the loading speed of web pages. Brotli is a relatively newer compression algorithm developed by Google. It typically offers better compression ratios compared to gzip, meaning it can achieve smaller file sizes for the same content. This is especially beneficial for large files like JavaScript, CSS, and HTML files. Gzip is an older compression algorithm that has been widely used for many years. While it is effective at compressing files, it generally provides slightly larger file sizes compared to Brotli for the same content.
const fs = require("fs");
const zlib = require("zlib");
const express = require("express");
const cors = require("cors");
const app = express();
app.use(express.static("public"));
app.use(cors());
// File paths
const inputFile = "./public/data/yelp_academic_dataset_business.json";
const outputFile = "./public/data/yelp_academic_dataset_business.json.gz";
// Compress the JSON file at start-up
const compressFile = () => {
const gzip = zlib.createGzip();
const inputStream = fs.createReadStream(inputFile);
const outputStream = fs.createWriteStream(outputFile);
inputStream.pipe(gzip).pipe(outputStream);
outputStream.on("finish", () => console.log("Gzip compression completed"));
};
// Serve the compressed file
app.get("/download", (req, res) => {
fs.stat(outputFile, (err, stats) => {
if (err) {
console.error("An error occurred:", err);
res.status(500).send("Server error");
} else {
res.setHeader("Content-Type", "application/json");
res.setHeader("Content-Encoding", "gzip");
res.setHeader("Content-Length", stats.size);
const readStream = fs.createReadStream(outputFile);
readStream.pipe(res);
}
});
});
// Serve the uncompressed file
app.get("/download-uncompressed", (req, res) => {
fs.stat(inputFile, (err, stats) => {
if (err) {
console.error("An error occurred:", err);
res.status(500).send("Server error");
} else {
res.setHeader("Content-Type", "application/json");
res.setHeader("Content-Length", stats.size);
const readStream = fs.createReadStream(inputFile);
readStream.pipe(res);
}
});
});
compressFile();
app.listen(3000, function () {
console.log("Example app listening on port 3000!");
});
In this particular scenario, I intended for the compression process to occur only once. We could opt for two pathways - one serving the compressed version and the other, the uncompressed version of the files. This bifurcation would potentially highlight noticeable disparities, both in terms of file size reduction and delivery speed.
// Client side code
fetch("http://localhost:3000/download")
.then((response) => response.json())
.then((data) => console.log(data))
.catch((e) =>
console.log(`There was a problem with your fetch operation: ${e.message}`)
);
fetch("http://localhost:3000/download-uncompressed")
.then((response) => response.json())
.then((data) => console.log(data))
.catch((e) =>
console.log(`There was a problem with your fetch operation: ${e.message}`)
);
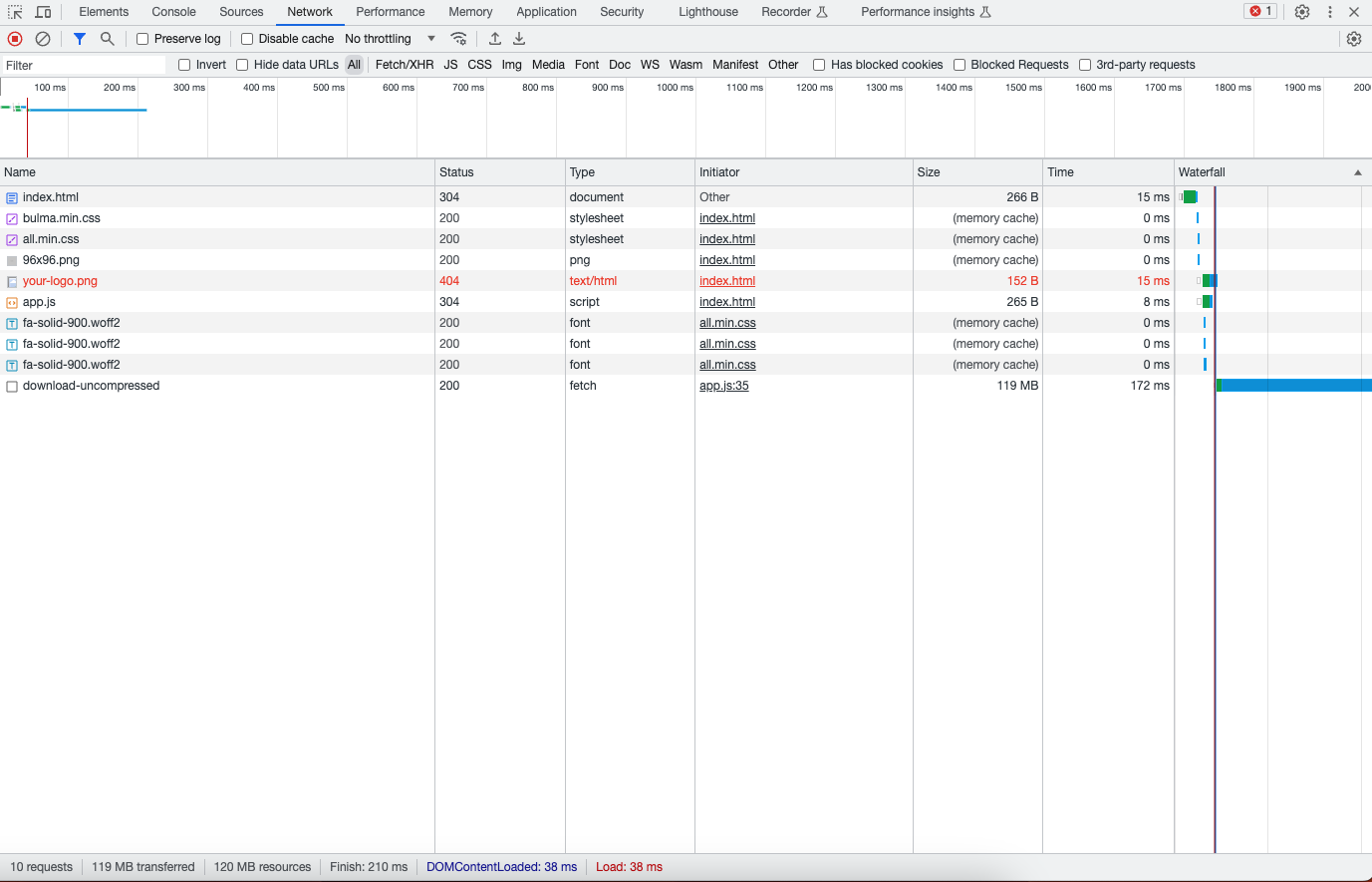
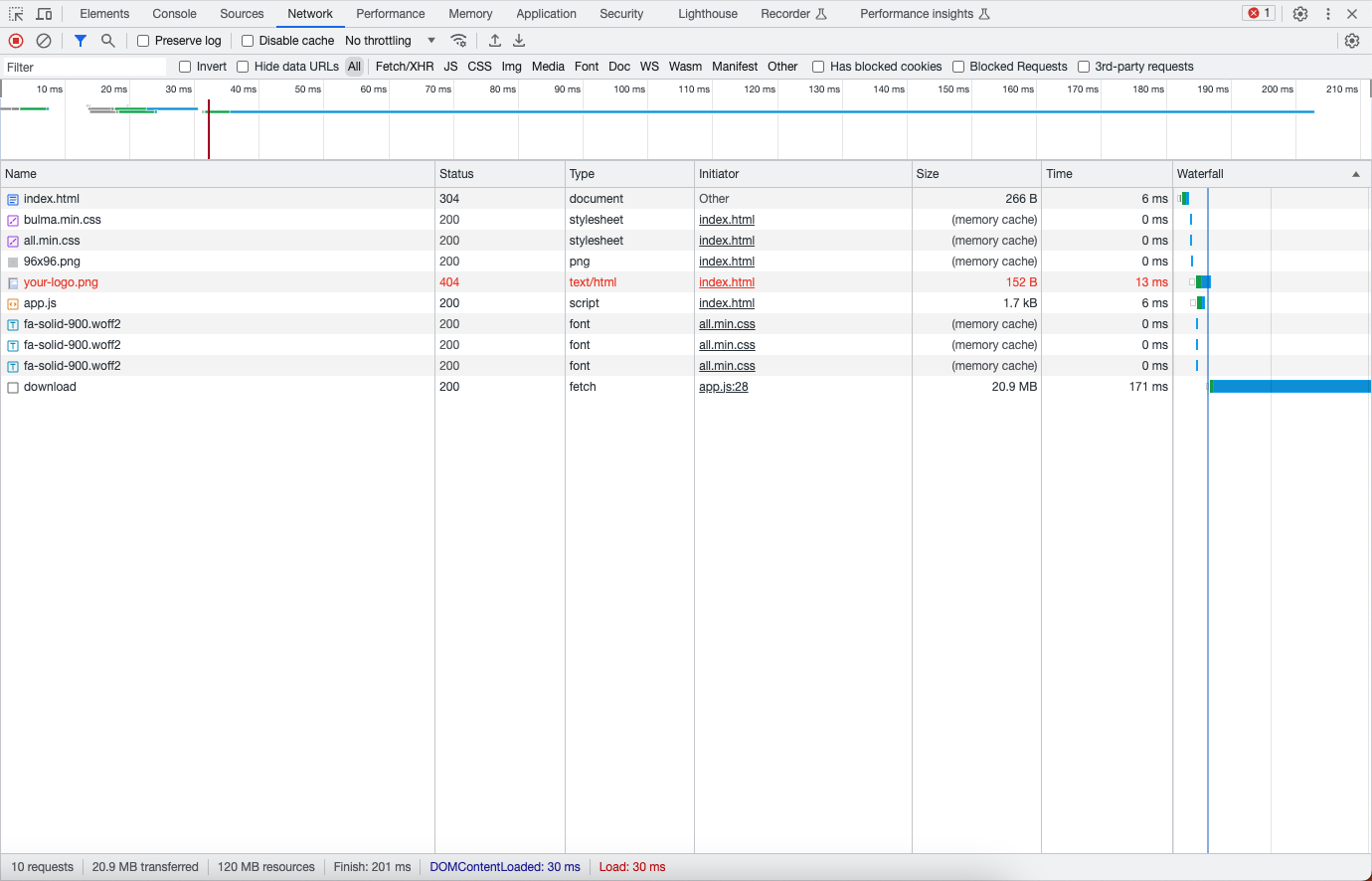
Going from 119 MB to 21 MB is a huge difference, especially on a slower connection. Now let's repeat the experiment with Brotli:
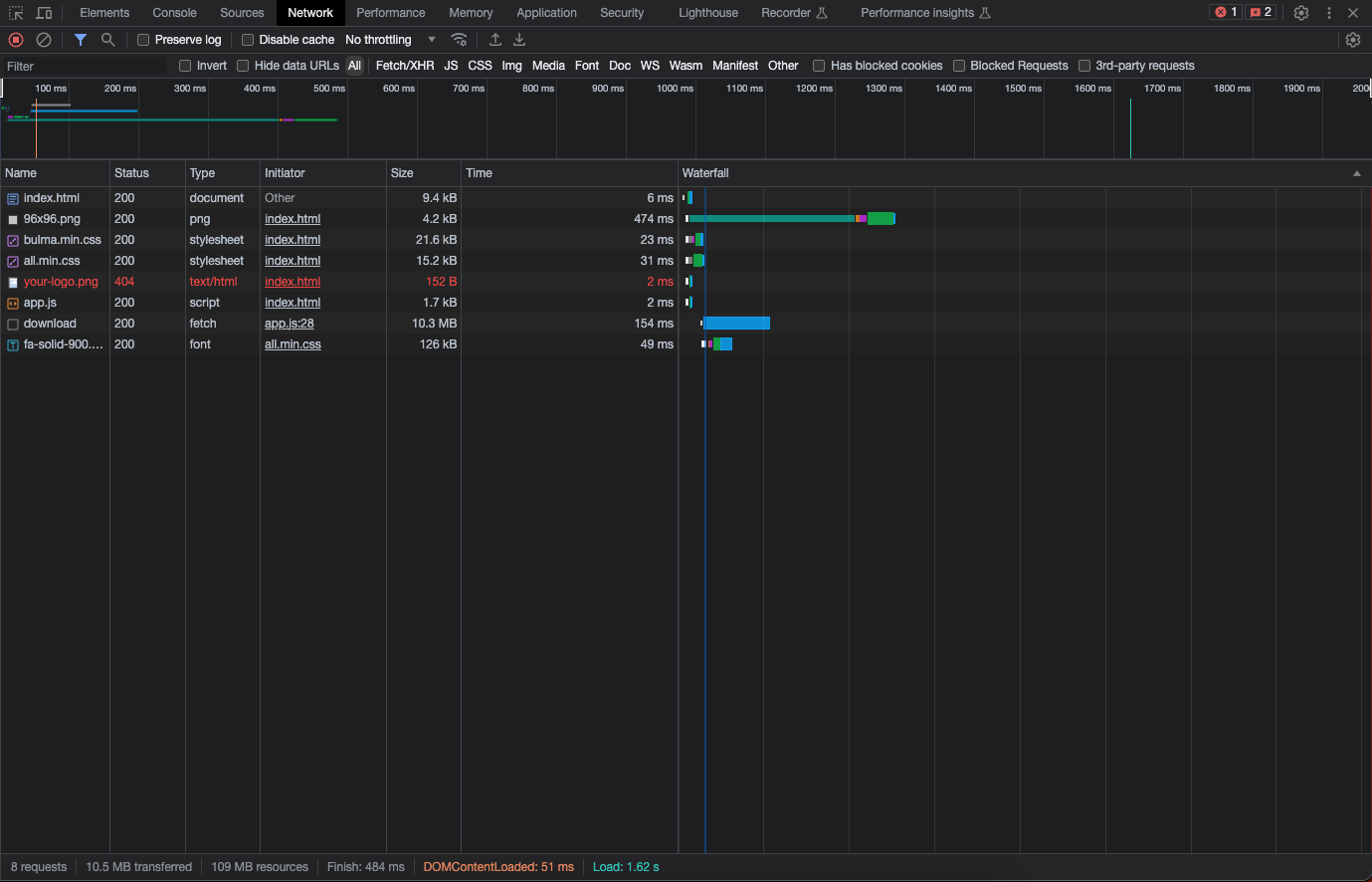
The result is very impressive using Brotli, here is the code example:
const fs = require("fs");
const zlib = require("zlib");
const express = require("express");
const app = express();
const cors = require("cors");
const port = 3000;
app.use(express.static("public"));
app.use(cors());
// File paths
const inputFile = "./public/data/yelp_academic_dataset_business.json";
const outputFile = "./public/data/yelp_academic_dataset_business.json.br";
// Compress the JSON file at start-up
const compressFile = () => {
const compressor = zlib.createBrotliCompress();
const inputStream = fs.createReadStream(inputFile);
const outputStream = fs.createWriteStream(outputFile);
inputStream.pipe(compressor).pipe(outputStream);
outputStream.on("finish", () => console.log("Compression completed"));
};
// Serve the compressed file
app.get("/download", (req, res) => {
fs.stat(outputFile, (err, stats) => {
if (err) {
console.error("An error occurred:", err);
res.status(500).send("Server error");
} else {
res.setHeader("Content-Type", "application/json");
res.setHeader("Content-Encoding", "br");
res.setHeader("Content-Length", stats.size);
const readStream = fs.createReadStream(outputFile);
readStream.pipe(res);
}
});
});
compressFile();
app.listen(port, () => {
console.log(`Server running at http://localhost:${port}/`);
});
Using the browser's built-in support for compression (e.g., Brotli or gzip) when transmitting data has several advantages:
Reduced Bandwidth Usage: Compressing data before transmitting can significantly reduce the size of the data, which in turn reduces the amount of bandwidth used. This can be particularly beneficial for users with slower internet connections or data limits.
Faster Load Times: Smaller data sizes mean that resources load faster, which can improve the performance of your web application and lead to a better user experience.
Offloading Computation: By using the browser's built-in support for decompression, you offload some of the computation from your server to the client's machine. This can reduce server load and increase its capacity to handle more requests.
Standardized Support: Compression methods like gzip and Brotli are widely supported across nearly all modern web browsers. This means you can reliably use these compression techniques and expect them to work for the vast majority of your users.
However, it's also worth noting that while compression is beneficial, it's not always necessary for smaller data payloads. The process of compressing and decompressing data can add additional CPU overhead, so it's often more beneficial when dealing with larger data sizes. Always consider the trade-off between CPU usage and network bandwidth in your specific use case.
Subscribe to my newsletter
Read articles from Hooman Pegahmehr directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Hooman Pegahmehr
Hooman Pegahmehr
Hooman Pegahmehr is a performance-driven, analytical, and strategic Technology Management Professional, employing information technology best practices to manage software and web development lifecycle in alignment with client requirements. He builds high-quality, scalable, and reliable software, systems, and architecture while ensuring secure technology service delivery as well as transcending barriers between technology, creativity, and business, aligning each to capture the highest potential of organization resources and technology investments. He offers 8+ years of transferable experience in creating scalable web applications and platforms using JavaScript software stack, including MongoDB, Express, React, and Node, coupled with a focus on back-end development, data wrangling, API design, security, and testing. He utilizes a visionary perspective and innovative mindset to collect and translate technical requirements into functionalities within the application while writing codes and producing production-ready systems for thousands of users. He designs, develops, and maintains fully functioning platforms using modern web-based technologies, including MERN Stack (MongoDB, Express, React, Node). As a dynamic and process-focused IT professional, Hooman leverages cutting-edge technologies to cultivate differentiated solutions and achieve competitive advantages while supporting new systems development lifecycle. He excels in creating in-house solutions, replacing and modernizing legacy systems, and eliminating outsourcing costs. He exhibits verifiable success in building highly responsive full-stack applications and incident management systems using advanced analytical dashboards while translating complex concepts in a simplified manner. Through dedication towards promoting a culture of collaboration, Hooman empowers and motivates diverse personnel to achieve technology-focused business objectives while administering coaching, training, and development initiatives to elevate personnel performance and achieve team synergy. He earned a winning reputation for transforming, revitalizing, streamlining, and optimizing multiple programs and web-based applications to drive consistent communications across cross-functional organization-wide departments. He manages multiple projects from concept to execution, utilizing prioritization and time management capabilities to complete deliverables on time, under budget, and in alignment with requirements.