HUGE 🔥 LLaMA 2 with 32K Context Length
 Sumi Sangar
Sumi Sangar
LLaMA 2 model with a 32k context window is here, yes you are right, 32,000 tokens can be inputted or either be outputted, you can generate or give as an input. This is a huge achievement and accomplishment in the open source world because now the short-term memory of the LLaMA 2 model has tremendously increased.

Thanks to a company called Together.ai and they have done this massive work of taking the existing LLaMA 2 model and using a technique called position interpolation to create this. Position interpolation and the model and how the model does. Before we discuss all these things we are going to just see a quick demo just to show you that this works. So I went and got Paul Graham’s essays. So when I took this and then added it to the playground that they have got and I added this and I asked a question. The question is do you know what happened in 2019 from the above document? So in a particular place at the end of this document, this says what happened. So it says in the fall of 2019 Bell was finally finished and it talks about Lisp and if you go there and it tells you the exact answer.
So typically what happens is that when you have a playground or when you have any web interface when you upload a text that is beyond the context window of a large language model it truncates that it takes only the particular part. So this is just to make sure that 32k seems to be working fine. I’m not extensively tested it but for now, let us assume that this works fine. And now going back together and what they have done?
Here first they have taken the existing LLaMA 2 model and used a technical position interpolation. This is necessarily a technique that has been introduced very recently. So for all the models that support Rope or the Rope-based model Rope PE in Rope stands for positional embeddings. So you can extend the context window up to 32,000 characters or 32,000 tokens with very minimal fine-tuning within 1000 steps that also did not degrade the model performance.

It demonstrated strong empirical results on various tasks that require long context. So there are a lot of tasks that require a long context. For example summarization document questions and answers. So this seems to show that there is a promising way for us to use positional interpolation and get these large language models to support longer context windows. And that is exactly what together have done and then made this new model that is available for us. They’ve added a screenshot of their playground creating or completing a book using the 32K model which I did not reproduce or test and we don’t have a way to reproduce. That’s a different topic altogether. Not just that they used positional interpolation and then made the model longer or support a longer context. They also supported or included flash attention. The model has gained some speed-up.
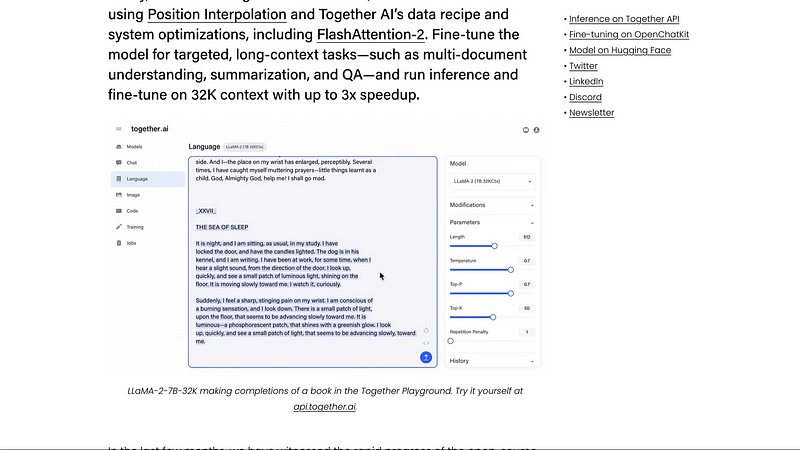
So now we have got a model that has longer memory and we have got a model that is faster and very good for us is the model itself is open source. So we can go ahead and then play with this model in itself. So that is available on Hanging Face if you want to play with the model. They have open source the 7 billion parameter model. So now going into this announcement, the more what are the things that they are sharing. They are sharing a bunch of things. One they are sharing the model in itself. LLaMA 2 7 billion 32K model and they are also sharing some examples of how to fine-tune this model for specific applications like book summarization and long context question and answering especially they are using Salesforce’s book sum to show you how you can do question and how you can do book summarization and also they are providing the support the scripts to do the summarization and they have got their platform. So if you are wondering hey why would they do this for free water they are going to do it to make money. Then this is the answer for you. So they have got their interface like the one where we were running the model.
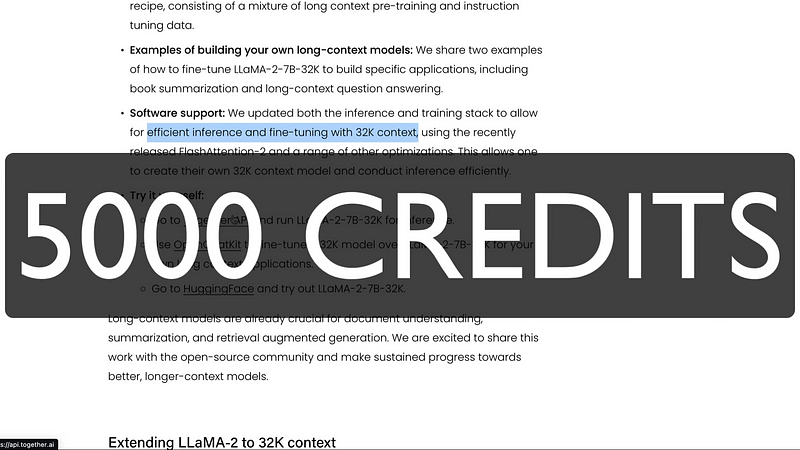
They’ve got this own interface the playground where you can go launch a lot of models host a lot of models just do inference of a lot of models. So they have included inference and training stack to allow efficient inferencing and fine-tuning with 32K using flash attention and you know you can do it for your data as well. You can go play with the model for free. The free is limited they give you 5,000 credits.
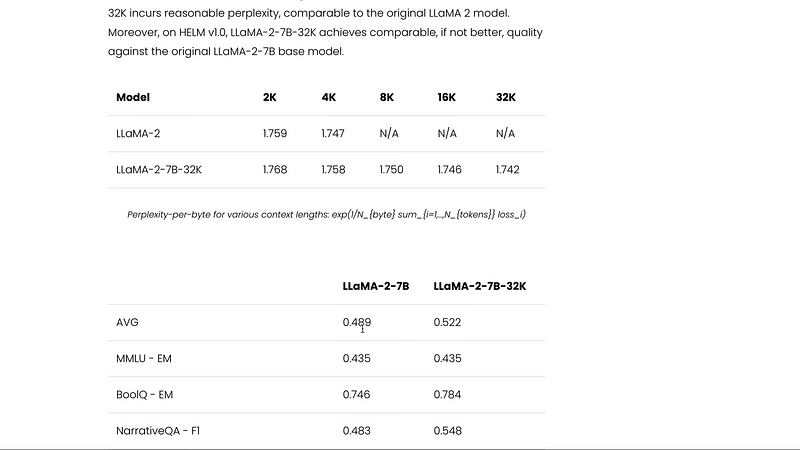
I think I’m already running out of my credit so that’s one thing. The second thing is they have given you an open chat kit to fine-tune the model and they have given the hugging face uploaded model and hugging face model up. So the model is uploaded with the llama to license. If you have got less than 700 million users then you can use it for anything but if you’ve got more than 700 million users you cannot it’s it’s that weird license but are now talking about this particular model in itself. If you see the benchmarks this model is doing good. Typically the complaint that people have is the model that supports longer context length does not necessarily have really good coherence when they generate but there are a bunch of benchmarks that they’ve shown especially that they’ve shown that on helm v1.0 benchmark LLaMA to 7 billion 32k achieves comparable.
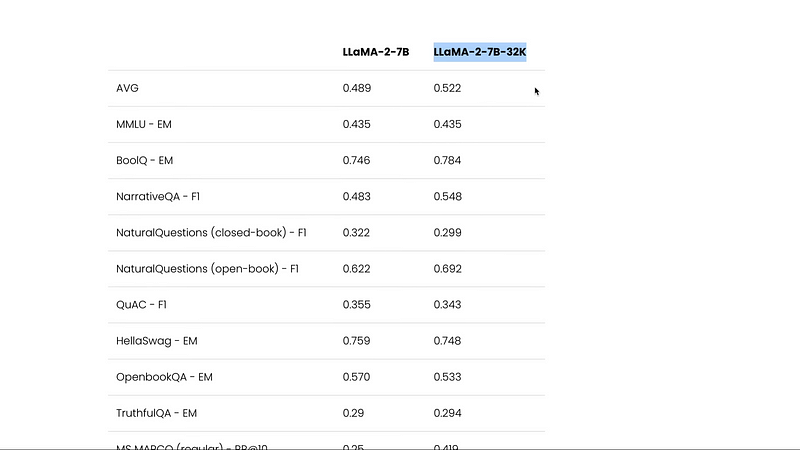
If not better quality against the original llama to base model and you can see how this model is doing. If you see multiple benchmarks you can see that LLaMA to 7 billion 32k model is consistently doing better than the base model in itself. And if you specifically are interested in you know longer context like how this behaves. You can see that the LLaMA to model scores the LLaMA to 7 billion 32k and the llama to 7 billion 32k with fine-tuning with fine tuning of course it does like it beats everything else but if you see the accuracy of like multi-document questions and answering with various documents you can see that the LLaMA to 7 billion 30 k is better than the base model.
And if you’re wondering how they you know give a longer document in the base model they were truncating and chunking it and giving but the point here is that the LLaMA to 7 billion 30 k model is doing better than every other llama to the version that they have got so that is the good thing that the new 32k model is not just you know just for the sake of longer context window we’ve got a theoretical model but it’s a model that works completely fine for us and I guess this is a really good direction rather than being happy about this model I’m happy that this concept of positional interpolation has jumped into the open source world and people are going to use this along with flash attention to develop multiple more models in the future that can support longer context windows and also faster inference. I’m looking forward to trying this model and meanwhile, you can go ahead and then read this blog post. I’ll link it in the YouTube description and play with this interface but just remember that they provide only one time 5,000 credits after they probably you cannot use it. So make sure that you try this every time. You try this model the way you can try this you can go launch a model then you can open this and then you can start questioning it one thing that was a little confusing for me is the length because by default or maximum. You can make it 32,000 here but I’m not sure how efficient that is you can go here and paste the text and then ask some questions and then it would answer once you’re done with this go ahead and then stop it because that is very important for you to charge you 30 cents for hosting.
You can go to your profile and click settings and then see the credits that we have spent. I was just doing simple trials and I’ve already run out of 3000 or 4000 credits approximately so if you want to play around with that is something that you need to keep in mind or if you have got a really good GPU then you can go ahead download the model from hugging face model up and start playing around this model I’m looking forward to trying this model on google collab or some other interface where we can try this model but until then you can try this model in their playground and also let me know what do you feel about this direction of 32k a lot of people were telling me that you know Claude supports 100k and something that supports this much just please remember that Claude and any other new company that supports longer context window is not open source.
I think this is the best way I’ve got an open source which is one of the state-of-the-art models LLaMA2 with a 30k context window. I think this is a blessing in disguise and I’m looking forward to seeing what the open-source community does with this see in another blog.
Subscribe to my newsletter
Read articles from Sumi Sangar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sumi Sangar
Sumi Sangar
Software Engineer with more than 10 years of experience in Software Development. I have a knowledge of several programming languages and a Full Stack profile building custom software (with a strong background in Frontend techniques & technologies) for different industries and clients; and lately a deep interest in Data Science, Machine Learning & AI. Experienced in leading small teams and as a sole contributor. Joints easily to production processes and is very collaborative in working in multidisciplinary teams.