Unlocking the Power of Database Indexing
 Opere Peter
Opere Peter
Introduction
In the vast world of databases, where data is abundant and dynamic, the art of accessing information swiftly becomes a pivotal challenge. Enter the solution: database indexing. A fundamental technique embraced by database management systems, indexing serves as a powerful key to unlock the true potential of data retrieval. By carefully organizing and optimizing data structures, indexing dramatically enhances the performance and efficiency of database queries. In this comprehensive exploration, we delve into the inner workings of database indexing, uncovering its benefits, mechanisms, and best practices, all aimed at empowering developers and database administrators with the tools to streamline and expedite data access like never before. So, let us embark on a journey to understand the art and science behind database indexing and harness its prowess to elevate the responsiveness and fluidity of our data-driven world.
Database indexing
Database indexing is a technique used to improve the performance of querying and retrieving data from a database table. It involves creating a separate data structure (the index) that stores a sorted copy of one or more columns of the table, along with pointers to the actual rows in the table. Indexes facilitate faster data retrieval and help reduce the need for full table scans when executing queries.
In PostgreSQL, indexes can be created on individual columns or combinations of columns in a table. Here's how indexing works, along with a step-by-step example using mockup data:
Create a Table
Let's assume we have a simple table called "employees" with the following schema:
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
age INTEGER,
department VARCHAR(50)
);
Insert Data
Insert some mockup data into the "employees" table:
INSERT INTO employees (first_name, last_name, age, department)
VALUES
('John', 'Doe', 30, 'IT'),
('Jane', 'Smith', 28, 'Marketing'),
('Mike', 'Johnson', 35, 'HR'),
('Lisa', 'Williams', 32, 'Finance'),
('Chris', 'Lee', 27, 'IT'),
('Anna', 'Miller', 29, 'Marketing');
--Now view all the files
SELECT * FROM employees;
Create an Index
Let's create an index on the "department" column to demonstrate how indexing works:
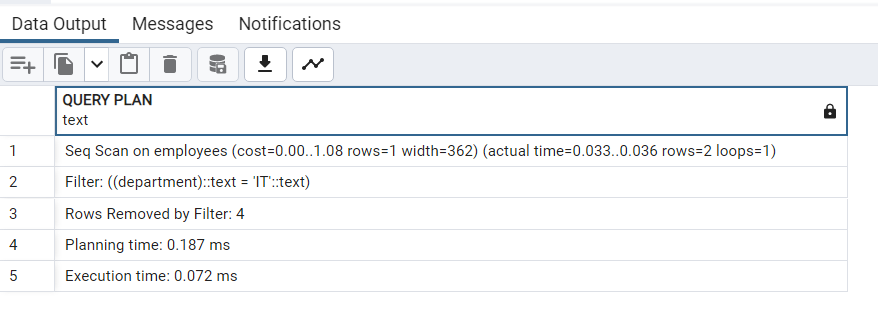
If there is no index on the "department" column, PostgreSQL will need to perform a full table scan to find all rows where the "department" is 'IT'. This means it will sequentially read each row of the "employees" table and check if the "department" column value matches 'IT'. For larger tables, this can be slow and resource-intensive, especially if the "employees" table has a significant number of rows.
Create an Index
Let's create an index on the "department" column to demonstrate how indexing works:
CREATE INDEX idx_department ON employees (department);
Query Using the Index
Now, let's perform a query to find all employees in the "IT" department:
EXPLAIN ANALYZE SELECT * FROM employees WHERE department = 'IT';
If there is an index on the "department" column, PostgreSQL can utilize the index to speed up the data retrieval process. When you execute the query, the output of EXPLAIN ANALYZE will show that the index is being used for the query.
The steps involved with index usage are as follows:
The query planner will recognize that there is an index on the "department" column, and it will decide to use that index to perform the search.
PostgreSQL will navigate the index to find all rows where the "department" column value is 'IT'. This is much faster than a full table scan because the index is a sorted data structure that allows for quick lookup based on the indexed column values.
Once the rows matching the condition are identified using the index, PostgreSQL will then retrieve the corresponding rows from the "employees" table using the pointers stored in the index.
Finally, the result set containing the rows with the "department" value of 'IT' will be returned.
Using an index on the "department" column significantly improves the performance of the query compared to executing it without an index. Without an index, the database needs to scan the entire table, while with an index, the database can efficiently look up the rows that match the condition by using the index structure. This improvement becomes more pronounced as the size of the "employees" table increases, making indexing an essential tool for optimizing query performance in large databases.
Difference between index and Primary Key
The primary key is a specific type of index that enforces uniqueness and non-nullability for a column or a combination of columns. A table can have only one primary key. If a primary key is defined on a column(s), it will automatically create a unique index to enforce the primary key constraints. On the other hand, an index is a more general data structure that can be created on any column(s) to improve query performance, but it does not necessarily enforce uniqueness or non-nullability.
SELECT indexname, indexdef FROM pg_indexes WHERE tablename = 'employees';
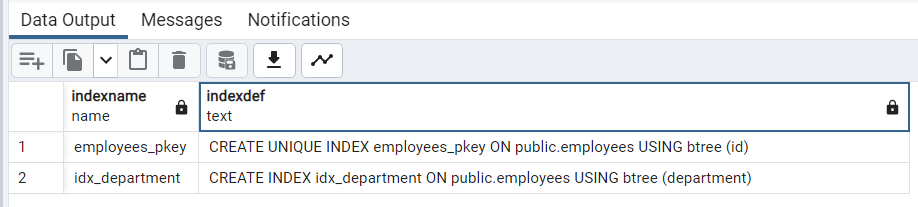
employees_pkey (Primary Key Index) | idx_department (Non-Primary Key Index) | |
Purpose | is an index automatically created when you define the "id" column as the primary key of the "employees" table. It enforces the uniqueness and non-nullability of the "id" column. The primary key is used to uniquely identify each row in the table and is a crucial constraint for maintaining data integrity. | is an index you manually created on the "department" column. It is not a primary key, but rather an index that you explicitly defined to optimize queries based on the "department" column. The purpose of this index is to speed up data retrieval for queries filtering by the "department" column. |
Behavior | The primary key index is a type of B-tree index, which is a balanced tree data structure that allows efficient data lookup based on the "id" values. The primary key index is automatically maintained by PostgreSQL, and any insert, update, or delete operations that modify the "id" column will also update the primary key index | is also a B-tree index. It allows PostgreSQL to quickly locate rows that match the specified "department" value when executing queries with a condition like WHERE department = 'IT'. This index will only be updated when you perform insert, update, or delete operations that modify the "department" column. |
Indexed Column(s) | is specifically created on the "id" column because it serves as the primary key of the table. | specifically created on the "department" column to optimize queries using this column. |
Conclusion
Database indexing is a vital technique for enhancing the performance and efficiency of database systems. By creating structured data representations, indexes enable rapid data retrieval and minimize the need for time-consuming full-table scans. Understanding how indexes work and strategically implementing them can significantly boost query speeds and overall database responsiveness. Whether it's for small-scale applications or large enterprise systems, leveraging the power of indexing can greatly optimize data management and provide an improved user experience.
Twitter and LinkedIn Links: Follow me on
Twitter: https://twitter.com/OperePeter9
Subscribe to my newsletter
Read articles from Opere Peter directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Opere Peter
Opere Peter
Data engineer and a python developer