A Beginner's guide to Practical Natural Language Processing using Spacy in 2023
 Hari Vamsi
Hari VamsiThis blog contains my learnings in the field of Natural Language Processing from multiple sources including but not limited to FreeCodeCamp, CodeBasics, Spacy Documentation, etc. #LearningInPublic
TLDR;
We will be building a Named Entity Recognition tool using Spacy on the Finacial News Article text.
This will be the input:
This will be the output:


Index
Introduction
With the boom of ChatGPT, a lot of traffic is been driven toward Natural Language Processing (NLP). Possibilities that were not thought possible before, we made possible today.
NLP is a branch of artificial intelligence focused on the interaction between computers and human language. It involves developing algorithms and models that enable machines to comprehend, interpret, and generate written and spoken language.
Let's see how we can level up and learn this powerful topic, build some cool projects, understand the pipelines involved, learn about the technical implications, and make some contributions towards its advancements.
Setup
Python 3
Spacy
pip install spacypython -m spacy download en
The text we will be using is a Financial News article from Yahoo Finance. You can download the text copy of the article from my GitHub. You can choose any textual data you want, but if you are learning this for the first time, I would suggest you stick to my example, so you can cross-validate your results.
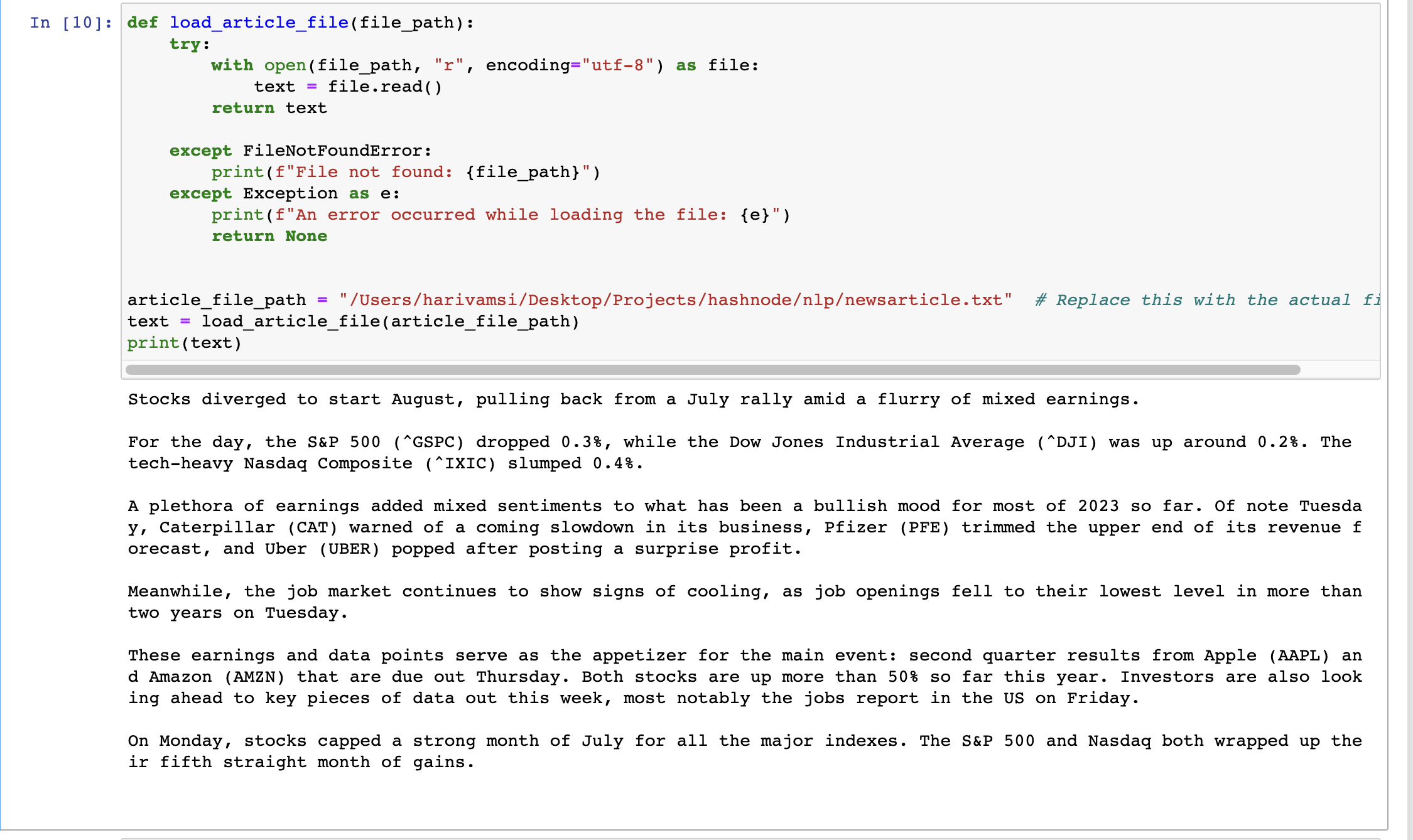
We will load up the news article file and store the content in a variable text
def load_article_file(file_path):
try:
with open(file_path, "r", encoding="utf-8") as file:
text = file.read()
return text
except FileNotFoundError:
print(f"File not found: {file_path}")
except Exception as e:
print(f"An error occurred while loading the file: {e}")
return None
article_file_path = "/Users/harivamsi/Desktop/Projects/hashnode/nlp/newsarticle.txt" # Replace this with the actual file path
text = load_article_file(article_file_path)
print(text)
You will see the output of the text as:
Basic Terms and Concepts in NLP
To understand the concepts in their actual practical sense we will use the news article text that we took earlier to perform the below operations as well.
We will use "en_core_web_sm" which is a small pre-trained NLP model for English. We are leveraging this model's capabilities to perform and understand our basic tasks.
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp(text)
Just within these few lines of code, there is so much that has happened behind the scenes.

We will fully understand the above pipeline as we go deeper into the Scapy implementation in future blogs, but know that they are different stages your text will go through when you do nlp(text).
Tokenization
The process of splitting the textual data into meaningful segments. This could be sentences, words, or letters. We will look at the words tokenization.# Tokenization for token in doc: print(token.text)The output will look something like
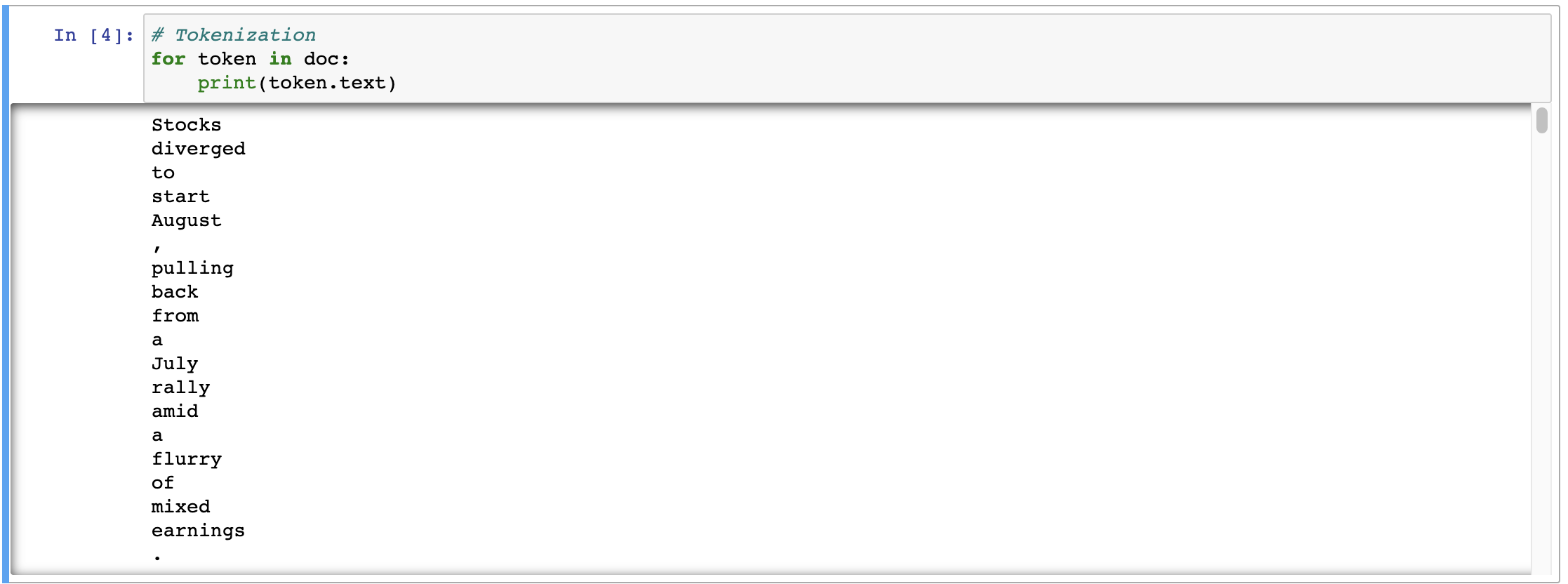
You might wonder why
print(token.text)instead of simplyprint(token). This is because the doc itself is a container, and it returned us a series of smaller containers which we call tokens. The reason why we usetoken.textis to get the actual text (string) of that token, not the token object itself. These are called Token Attributes.These token attributes can come in handy, we will see how. Say I want to extract all the numbers (could be anything like emails) in my text.
for token in doc: if token.like_num: print(token.text, " | ", token.like_num)We will get output something like,
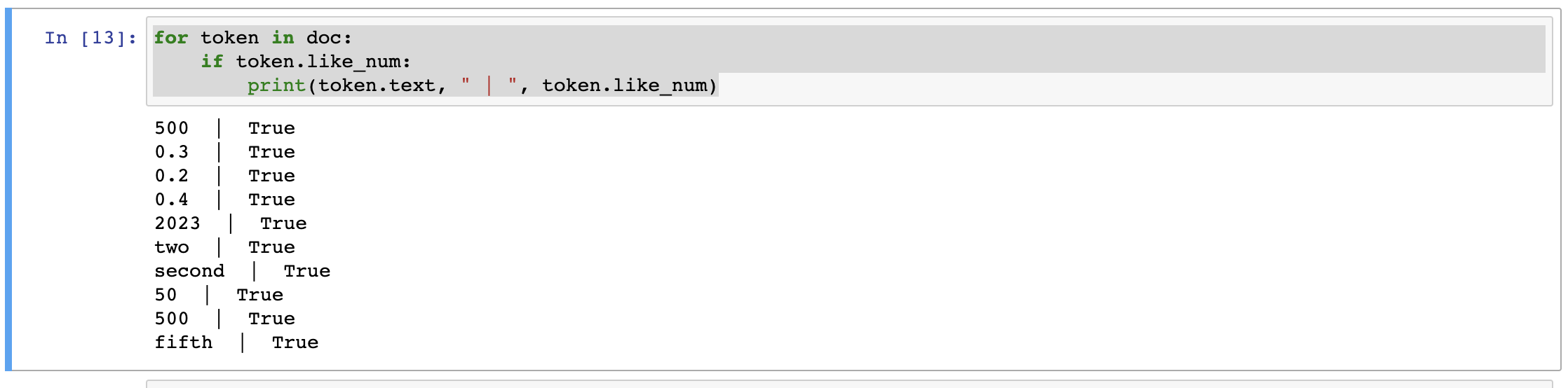
You can already see how robust spacy is in retrieving the numbers from the given text even if the number is written in numeric or word format.
You can also tokenize based on the sentences,
# Tokenize by sentenses for sent in doc.sents: print(sent)The output is going to look like
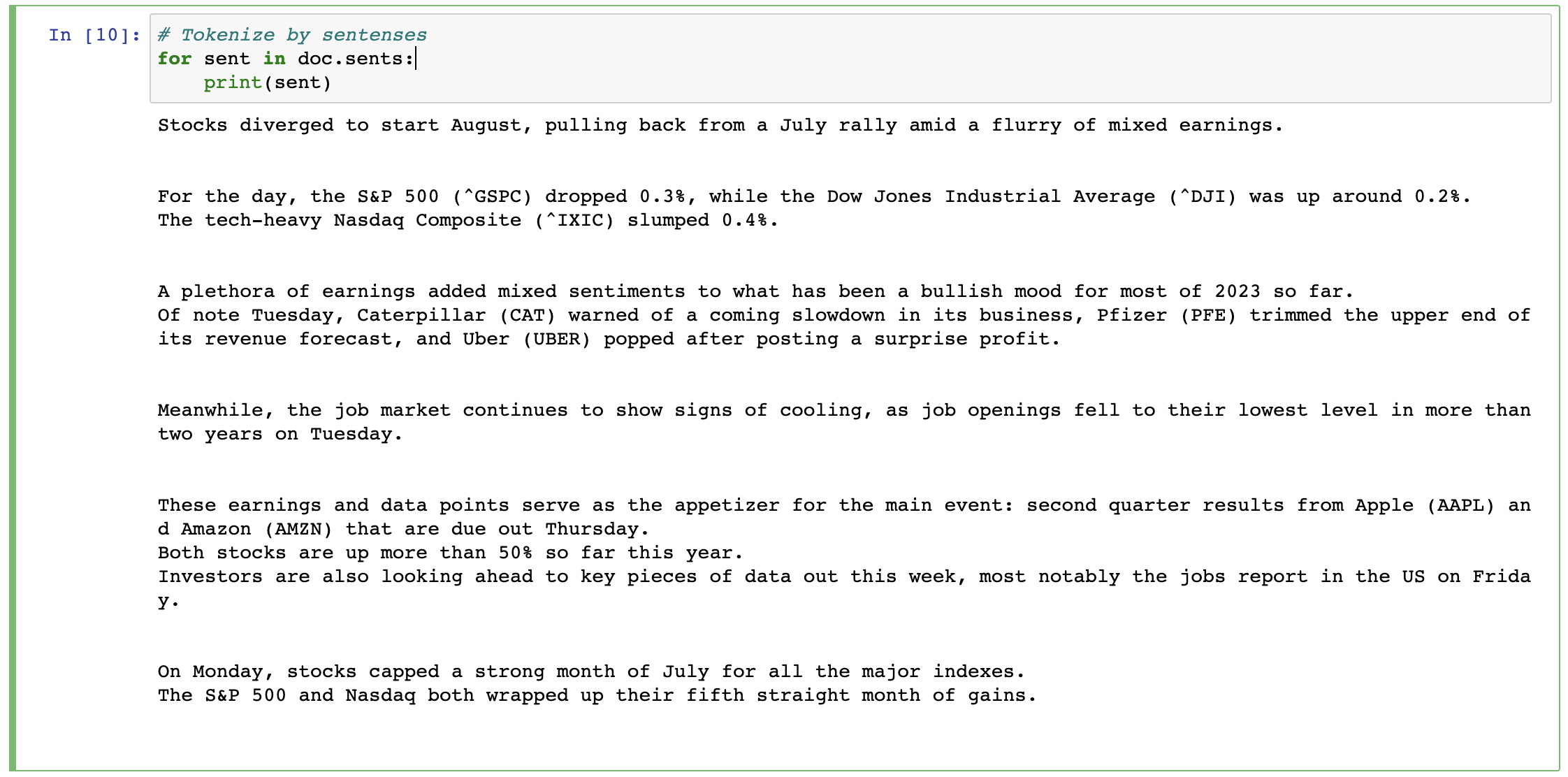
Notice how efficient the tokenization is. For example, if we were to write a logic to token into sentences just by using
string.split('.')we will end up with so many wrongly tokenized sentences like look at the cases in our text "0.3%", "0.2%", or even in general consider "etc.", or salutations like "Dr. ", "Mr. ", "Mrs. ".Stemming
Stemming is the process of removing the suffixes like -able, -ing, etc. to derive a base word to achieve word normalization. Word normalization can be defined as the process of representing words as close as possible to their true root word form.
Examples:
Talking -> talk
eating -> eat
ate -> ate
ability -> abil
Note that the Stemmed words may not be a proper word itself like the last example. Spacy does not have built-in support for stemming. Instead, spaCy focuses on lemmatization, which is generally considered more advanced and linguistically accurate than stemming.Lemmatization
It is a more advanced form of word normalization that involves transforming words to their base or dictionary form (referred to as the "lemma"). The key difference in lemmatization is that it takes into account the word's part of speech (POS) and produces valid words.
Examples:
ate -> eat
ability -> ability# Lemmatization for token in doc: print(token.text, " | ", token.lemma_)The output will look something like,
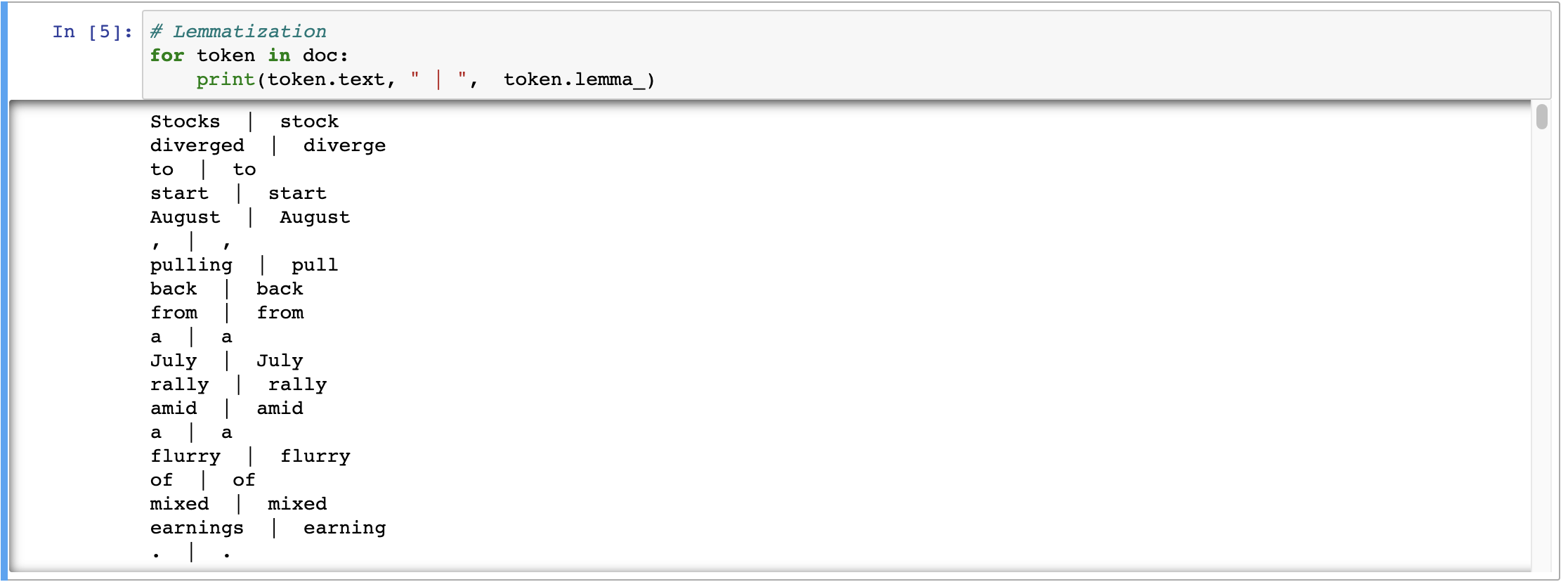
POS Tagging (Part-of-Speech Tagging)
POS tagging is the process of assigning grammatical labels (such as noun, verb, adjective, etc.) to each word in a given text. The POS tags provide information about the word's syntactic role in the sentence and are crucial for many NLP tasks, such as parsing, text classification, and named entity recognition.# POS Tagging for token in doc: print(token.text, " | ", token.lemma_, " | ", token.pos_)The output will look something like,
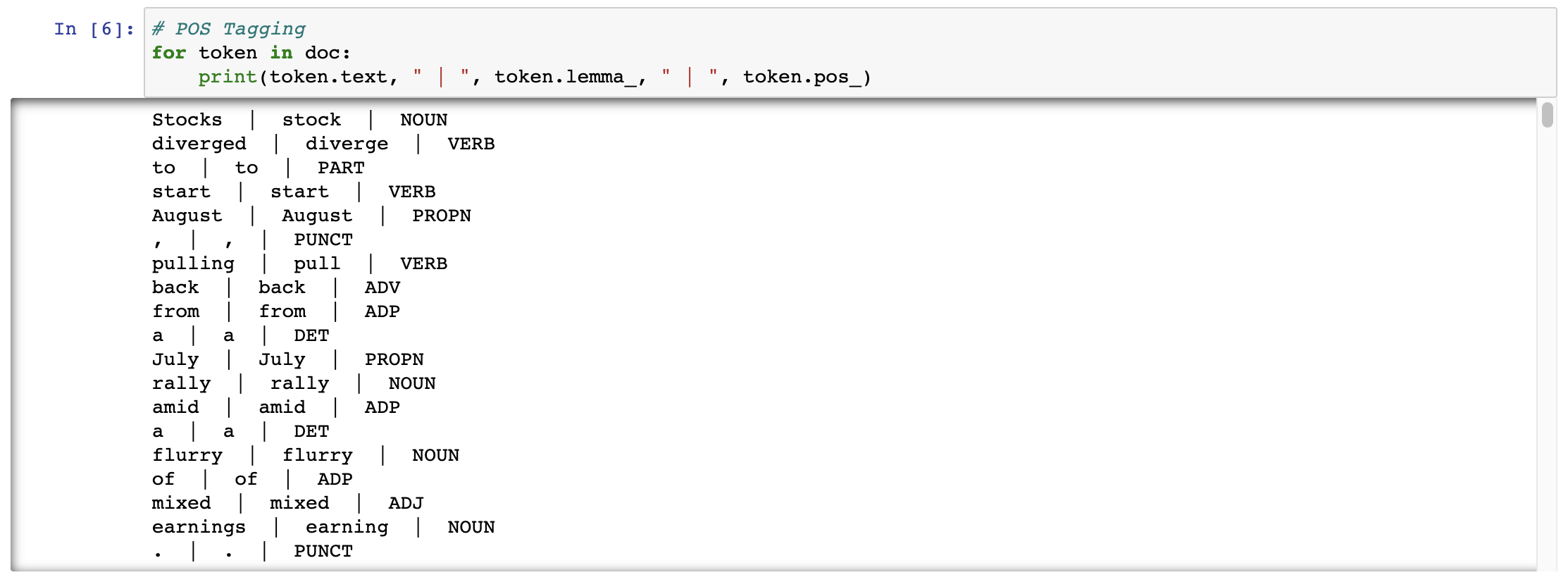
Named Entity Recognition (NER)
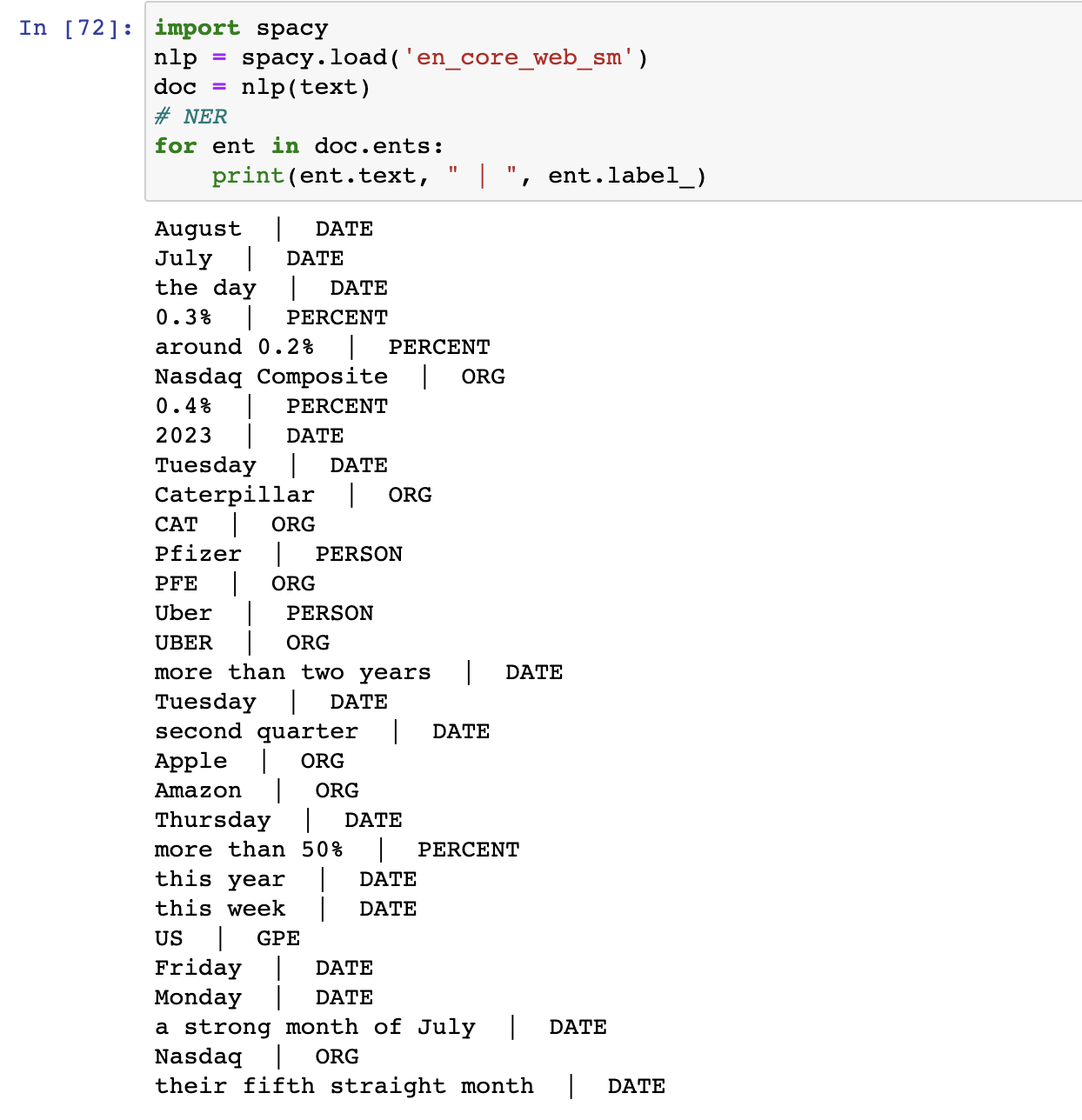
NER is the task of identifying and classifying named entities (such as names of people, organizations, locations, dates, etc.) in a text. NER is essential for extracting meaningful information from unstructured text and is used in various applications, such as information retrieval, sentiment analysis, and question-answering systems, document similarity.# NER for ent in doc.ents: print(ent.text, " | ", ent.label_)The output will look something like
Let's look at the output more beautifully by using displacy
from spacy import displacy displacy.render(doc, style='ent')The rendered output will look like
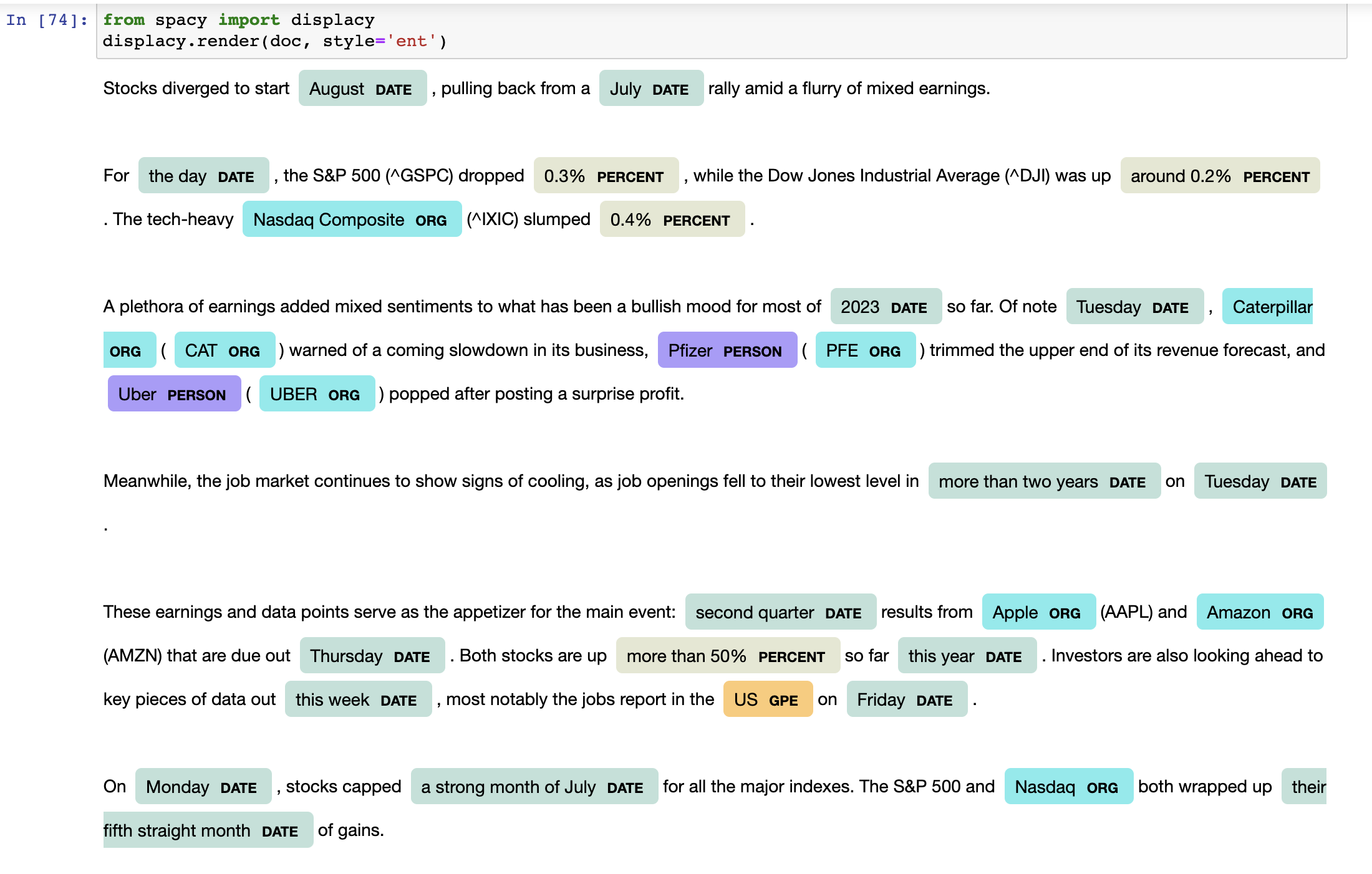
If you look closely, We have stock tickers GSPC, DJI, IXIC, CAT, PFE, UBER, AAPL, AMZN that were not labeled properly. Moreover, Pfizer and Uber are Companies but are labeled as PERSON. So we will fix these now with the help of EntityRuler.
#Create the EntityRuler ruler = nlp.add_pipe("entity_ruler", before="ner") #List of Entities and Patterns patterns = [ {"label": "STOCK", "pattern": "^GSPC"}, {"label": "STOCK", "pattern": "^DJI"}, {"label": "STOCK", "pattern": "^IXIC"}, {"label": "STOCK", "pattern": "CAT"}, {"label": "STOCK", "pattern": "PFE"}, {"label": "STOCK", "pattern": "UBER"}, {"label": "STOCK", "pattern": "AAPL"}, {"label": "STOCK", "pattern": "AMZN"}, {"label": "ORG", "pattern": "Pfizer"}, {"label": "ORG", "pattern": "Uber"}, ] ruler.add_patterns(patterns) doc = nlp(text) # NER for ent in doc.ents: print(ent.text, " | ", ent.label_) from spacy import displacy displacy.render(doc, style='ent')The output of this will look something like


However, one key thing to note here, we are using the EntityRuler and defining the rules to specify the labels. The problem we could potentially run into is when we have Amazon (River) and Amazon (Company) or Tesla (Person) and Tesla (Company) in the same text, the rule base approach will fail to properly label our entities.
Hurray 🎉🎉!!!! We did it! Kudos to you 👏🏻! We have come a long way starting from 0 to somewhere (optimistically) 0.1 (pessimistically)!
The code for the example used in this blog can be found on my GitHub.
Link: https://github.com/harivamsi9/LearningInPublic/blob/main/nlp/basics/Named%20Entity%20Recognition%20on%20Financial%20news%20data.ipynb
References
Spacy EntityRuler https://spacy.pythonhumanities.com/02_01_entityruler.html
Spacy Token Attributes https://spacy.io/api/token
CodeBasics NLP Playlist https://www.youtube.com/watch?v=R-AG4-qZs1A&list=PLeo1K3hjS3uuvuAXhYjV2lMEShq2UYSwX
FreeCodeCamp Natural Language Processing with spaCy & Python - Course for Beginners https://www.youtube.com/watch?v=dIUTsFT2MeQ
Subscribe to my newsletter
Read articles from Hari Vamsi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by