My Journey with the AWS Cloud Resume Challenge using Terraform
 Kalyan viswanath
Kalyan viswanathTable of contents
- Getting Started
- Building the Resume
- Implementing Infrastructure as Code with Terraform
- Setting Up the S3 Bucket
- Integrating a Custom Domain
- Configuring Route 53
- Configuring the CloudFront Distribution
- Setting Up DynamoDB for Visitor Count
- Creating the Lambda Function for Visitor Count
- Defining Variables, Data Sources, and Outputs
- Creating a GitHub Repository and Uploading the Project
- Integrating CI/CD with GitHub Actions
- Conclusion
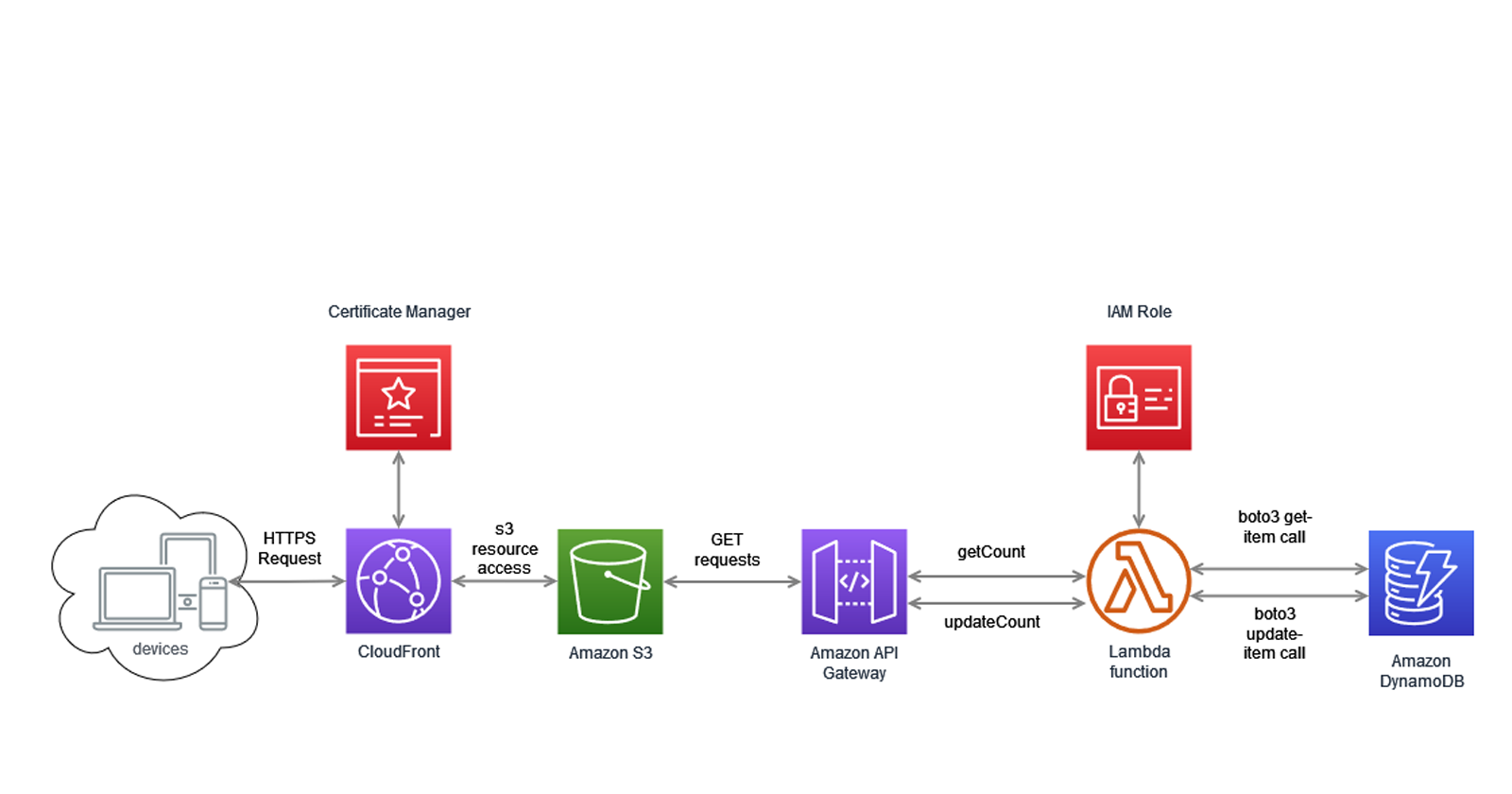
The AWS Cloud Resume Challenge is a project designed to test a variety of skills related to cloud computing, web development, and infrastructure as code. The challenge involves building a resume website hosted on AWS, complete with a visitor counter powered by a serverless backend. In this blog post, I'll walk you through my journey of completing this challenge using Terraform.
The Cloud Resume Challenge -AWS Official Page
Website - resume.kalyanviswanath.com
Github Repo - github.com/kalyanviswanath/aws-cloud-resume-terraform
Getting Started
The initial step in the challenge was to add the AWS Cloud Practitioner certification to my resume. This certification serves as a testament to your understanding of fundamental AWS Cloud architectural principles and services, and it's an excellent way to validate and display your cloud knowledge.

In addition to this, it's crucial to set up an AWS account if you don't already have one. This account is your gateway to accessing various AWS services. Once the account is set up, you need to create an appropriate user via AWS Identity and Access Management (IAM).
IAM lets you manage access to AWS services and resources securely. With IAM, you can create and manage AWS users and groups and use permissions to allow and deny their access to AWS resources.
After creating a user, you need to generate an access key. This access key consists of an access key ID and secret access key, which are used to sign programmatic requests that you make to AWS. If you use AWS CLI, SDKs, or direct HTTP calls, you need to provide these access keys.
Remember, it's crucial to manage these keys securely. They are similar to a username and password pair; anyone who has your access keys has the same level of access to your AWS resources that you do. Therefore, you should protect these keys and rotate them regularly.
Building the Resume
The following phase was dedicated to constructing my resume using HTML and CSS. The internet is indeed a treasure trove of HTML and CSS templates that are readily available for use. You can simply choose a template that aligns with your aesthetic, tailor it to your preference, and just like that, you have your own resume website.
Alternatively, if you're feeling adventurous and wish to have complete control over the design and functionality, you can opt to build your own website from scratch. This approach might be more time-consuming, but it provides an excellent opportunity to showcase your creativity and coding skills. Plus, it adds a personal touch to your website, making it truly unique and reflective of your personal brand.
Implementing Infrastructure as Code with Terraform

Infrastructure as Code (IaC) is a key practice in the DevOps world, and Terraform is one of the leading tools in this space. Terraform allows you to define and provide data center infrastructure using a declarative configuration language. This means you describe your desired state of infrastructure, and Terraform will figure out how to achieve that state.
For this project, I used Terraform to manage my AWS resources. Here's a look at the initial setup in my main Terraform configuration file:
terraform {
backend "s3" {
bucket = "github-aws-cloud-resume-terraform"
region = "us-east-1"
key = "terraform.tfstate"
encrypt = true
}
required_providers {
aws = {
source = "hashicorp/aws"
version = "5.5.0"
}
}
}
provider "aws" {
region = var.aws_region
}
In the terraform block, I defined the backend where Terraform will store its state file. The state file keeps track of the resources Terraform has created, so it's important to store it in a secure and reliable place. I chose to use an S3 bucket for this purpose.
The required_providers block specifies the providers required for this project. In this case, I'm using the AWS provider from HashiCorp, and I've pinned it to version 5.5.0 to ensure consistent behavior.
Finally, in the provider block, I configured the AWS provider with the region specified in a variable. This allows me to easily change the region in which I'm deploying my resources.
With this setup, I was ready to start defining my AWS resources in Terraform.
Setting Up the S3 Bucket

Amazon S3 (Simple Storage Service) is an object storage service that offers industry-leading scalability, data availability, security, and performance. For this project, I used an S3 bucket to host my resume website. Here's how I set up the S3 bucket using Terraform:
resource "aws_s3_bucket" "s3_bucket" {
bucket = "crc-s3"
force_destroy = true
tags = {
Name = "My bucket"
}
}
In the resource block, I defined an S3 bucket with the name "crc-s3". The force_destroy attribute is set to true, which means the bucket will be destroyed even if it contains objects when I run terraform destroy. The tags attribute allows me to add metadata to the bucket, which can be useful for organizing and identifying resources.
To ensure that my S3 bucket was accessible to my CloudFront distribution, but not to the public, I created an IAM policy that allows the CloudFront origin access identity to get objects from the S3 bucket:
data "aws_iam_policy_document" "s3_policy" {
statement {
actions = ["s3:GetObject"]
resources = ["${aws_s3_bucket.s3_bucket.arn}/*"]
principals {
type = "AWS"
identifiers = [aws_cloudfront_origin_access_identity.cdn_oai.iam_arn]
}
}
}
resource "aws_s3_bucket_policy" "docs" {
bucket = aws_s3_bucket.s3_bucket.bucket
policy = data.aws_iam_policy_document.s3_policy.json
}
The data block defines the IAM policy document, and the resource block applies that policy to the S3 bucket. Now, only the CloudFront distribution can access the objects in the S3 bucket, ensuring that my resume website is secure.
Integrating a Custom Domain
Having a custom domain is a significant step toward establishing a professional online presence. For my project, I already had a domain name - kalyanviswanath.com, which I had previously set up with a hosted zone in Amazon Route 53, AWS's scalable and highly available Domain Name System (DNS).
For this specific project, I decided to create a subdomain - resume.kalyanviswanath.com. The purpose of this subdomain was to host my resume separately while keeping it under my primary domain. This approach not only maintains the professional look of a custom domain but also provides a clear and organized structure for my online presence.
Setting up the subdomain involved creating a new record set within my existing hosted zone. I created an 'A' record for the subdomain, which I then pointed to my Amazon CloudFront distribution ID. Amazon CloudFront is a fast content delivery network (CDN) service that securely delivers data, videos, applications, and APIs to customers globally with low latency and high transfer speeds.
With this setup, any visitor typing resume.kalyanviswanath.com into their browser would be directed to my CloudFront distribution, and thus, to my resume website. This way, my resume maintained a professional appearance with a memorable URL, while also benefiting from the speed and security of Amazon's CDN.
Configuring Route 53
Amazon Route 53 is a highly available and scalable cloud Domain Name System (DNS) web service. It is designed to give developers and businesses an extremely reliable and cost-effective way to route end users to Internet applications by translating domain names into the numeric IP addresses that computers use to connect to each other. For this project, I used Route 53 to route traffic to my CloudFront distribution. Here's how I set up the Route 53 record using Terraform:
resource "aws_route53_record" "terraform_alias" {
zone_id = data.aws_route53_zone.hosted_zone.zone_id
name = "resume.kalyanviswanath.com"
type = "A"
alias {
name = aws_cloudfront_distribution.cdn.domain_name
zone_id = aws_cloudfront_distribution.cdn.hosted_zone_id
evaluate_target_health = false
}
}
In the resource block, I defined a Route 53 record in my hosted zone. The name attribute is set to my subdomain, and the type is set to "A", which stands for "Address record", and is used to point a domain or subdomain to an IP address.
The alias block is used to create an alias that points to my CloudFront distribution. This means that any traffic to resume.kalyanviswanath.com is routed to my CloudFront distribution, which in turn fetches the website from the S3 bucket.
With this setup, my resume website was accessible at a custom domain, and I could take advantage of the speed and security of CloudFront and the reliability of Route 53.
Configuring the CloudFront Distribution
Amazon CloudFront is a fast content delivery network (CDN) service that securely delivers data, videos, applications, and APIs to customers globally with low latency, high transfer speeds, all within a developer-friendly environment. For this project, I used CloudFront to serve my resume website. Here's how I set up the CloudFront distribution using Terraform:
resource "aws_cloudfront_origin_access_identity" "cdn_oai" {
comment = "aws-cloud-resume-terraform-cloudfront-access"
}
locals {
s3_origin_id = "myS3Origin"
}
resource "aws_cloudfront_distribution" "cdn" {
origin {
domain_name = aws_s3_bucket.s3_bucket.bucket_regional_domain_name
origin_id = "myS3Origin"
s3_origin_config {
origin_access_identity = aws_cloudfront_origin_access_identity.cdn_oai.cloudfront_access_identity_path
}
}
enabled = true
is_ipv6_enabled = true
comment = "Some comment"
default_root_object = "index.html"
aliases = ["resume.kalyanviswanath.com"]
default_cache_behavior {
cached_methods = ["GET", "HEAD"]
allowed_methods = ["GET", "HEAD"]
target_origin_id = local.s3_origin_id
forwarded_values {
query_string = false
cookies {
forward = "none"
}
}
viewer_protocol_policy = "redirect-to-https"
min_ttl = 0
default_ttl = 0
max_ttl = 0
}
price_class = "PriceClass_200"
restrictions {
geo_restriction {
restriction_type = "none"
}
}
viewer_certificate {
acm_certificate_arn = data.aws_acm_certificate.example.arn
ssl_support_method = "sni-only"
minimum_protocol_version = "TLSv1.2_2018"
}
}
In the resource block, I defined a CloudFront distribution with an origin that points to my S3 bucket. The origin_access_identity is used to give CloudFront the permission to fetch objects from the S3 bucket.
The default_cache_behavior block specifies how CloudFront should handle requests for my website. I configured it to redirect HTTP requests to HTTPS, ensuring that all traffic to my website is encrypted.
The aliases attribute is used to specify the custom domain for the CloudFront distribution. In this case, I used the subdomain I created earlier - resume.kalyanviswanath.com.
The viewer_certificate block is used to specify the SSL certificate for the CloudFront distribution. This ensures that my website is served over HTTPS.
With this setup, my resume website was not only hosted on a custom domain but also delivered quickly and securely to visitors around the world.
Setting Up DynamoDB for Visitor Count
Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance at any scale. It's a fully managed, multiregion, multimaster, durable database with built-in security, backup and restore, and in-memory caching for internet-scale applications. For this project, I used DynamoDB to store the visitor count for my resume website. Here's how I set up the DynamoDB table using Terraform:
resource "aws_dynamodb_table" "crc-dynamodb" {
name = "crc-dynamodb"
billing_mode = "PAY_PER_REQUEST"
hash_key = "ID"
attribute {
name = "ID"
type = "S"
}
tags = {
purpose = "cloudresumechallenge"
Environment = "production"
}
}
In the resource block, I defined a DynamoDB table with the name "crc-dynamodb". The billing_mode attribute is set to "PAY_PER_REQUEST", which means I only pay for what I use, making it cost-effective for applications with unpredictable traffic patterns.
The hash_key attribute is set to "ID", which is the primary key for the table. The attribute block defines the attributes for the primary key.
The tags attribute allows me to add metadata to the table, which can be useful for organizing and identifying resources.
Next, I added an item to the DynamoDB table to initialize the visitor count:
resource "aws_dynamodb_table_item" "event_test" {
table_name = aws_dynamodb_table.crc-dynamodb.name
hash_key = aws_dynamodb_table.crc-dynamodb.hash_key
lifecycle {
ignore_changes = all
}
item = <<ITEM
{
"ID": {"S": "1"},
"views":{"N":"700"}
}
ITEM
}
The resource block defines an item with an "ID" of "1" and a "views" count of "700". The lifecycle block with ignore_changes = all is used to prevent Terraform from trying to manage the item after it's created.
With this setup, each visit to my resume website increments the "views" count in the DynamoDB table.
Creating the Lambda Function for Visitor Count
AWS Lambda is a serverless compute service that lets you run your code without provisioning or managing servers. For this project, I used a Lambda function to increment a visitor count each time someone visits my resume website. Here's how I set up the Lambda function using Terraform:
resource "aws_lambda_function" "myfunc" {
filename = data.archive_file.zip.output_path
source_code_hash = data.archive_file.zip.output_base64sha256
function_name = "myfunc"
role = aws_iam_role.iam_for_lambda.arn
handler = "func.lambda_handler"
runtime = "python3.10"
depends_on = [aws_iam_role_policy_attachment.attach_iam_policy_to_iam_role]
}
In the resource block, I defined a Lambda function with the name "myfunc". The filename attribute points to the location of the packaged Lambda function code, and the source_code_hash attribute is used to trigger updates to the Lambda function whenever the source code changes.
The role attribute is set to the ARN of an IAM role that I created for the Lambda function. This role grants the Lambda function the necessary permissions to execute and access other AWS resources.
The handler attribute is set to "func.lambda_handler", which is the entry point to my Lambda function code. The runtime attribute is set to "python3.10", which is the runtime environment for the Lambda function.
The IAM role for the Lambda function is defined as follows:
resource "aws_iam_role" "iam_for_lambda" {
name = "iam_for_lambda"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Effect": "Allow",
"Sid": ""
}
]
}
EOF
}
This IAM role allows the Lambda service to assume the role. The role is then attached to a policy that grants the necessary permissions for the Lambda function:
resource "aws_iam_role_policy_attachment" "attach_iam_policy_to_iam_role" {
role = aws_iam_role.iam_for_lambda.name
policy_arn = aws_iam_policy.aws_iam_policy_for_resume_project.arn
}
The data block is used to create a ZIP archive of the Lambda function code, which is then uploaded to AWS Lambda:
data "archive_file" "zip" {
type = "zip"
source_dir = "${path.module}/lambda"
output_path = "${path.module}/lambda/packedfunc.zip"
}
Finally, I created a URL for the Lambda function using the aws_lambda_function_url resource. This URL can be used to invoke the Lambda function:
resource "aws_lambda_function_url" "url1" {
function_name = aws_lambda_function.myfunc.function_name
authorization_type = "NONE"
cors {
allow_credentials = true
allow_origins = ["*"]
allow_methods = ["*"]
allow_headers = ["date", "keep-alive"]
expose_headers = ["keep-alive", "date"]
max_age = 86400
}
}
With this setup, each visit to my resume website triggers the Lambda function, which increments the visitor count.
Defining Variables, Data Sources, and Outputs
In Terraform, variables allow you to customize aspects of your resources and modules, data sources allow you to fetch data from outside of Terraform, and outputs let you extract information about your resources after they've been created. Here's how I used variables, data sources, and outputs in this project:
Variables
In the variables.tf file, I defined two variables:
variable "aws_region" {
type = string
default = "us-east-1"
}
variable "domain_name" {
type = string
description = "The domain name to use"
default = "kalyanviswanath.com"
}
The aws_region variable is used to specify the AWS region where the resources will be created, and the domain_name variable is used to specify the domain name for the CloudFront distribution and Route 53 record.
Data Sources
In the data.tf file, I defined two data sources:
data "aws_route53_zone" "hosted_zone" {
name = var.domain_name
}
data "aws_acm_certificate" "example" {
domain = "*.kalyanviswanath.com"
statuses = ["ISSUED"]
}
The aws_route53_zone data source fetches information about the Route 53 hosted zone for my domain, and the aws_acm_certificate data source fetches information about the ACM certificate for my domain.
Outputs
In the output.tf file, I defined several outputs:
output "cloudfront_distribution_domain_name" {
value = aws_cloudfront_distribution.cdn.domain_name
}
output "s3_bucket_name" {
value = aws_s3_bucket.s3_bucket.id
}
output "aws_route53_zone" {
value = data.aws_route53_zone.hosted_zone.name
}
output "certificate_arn" {
value = data.aws_acm_certificate.example.arn
}
output "aws_route53_zone_id" {
value = data.aws_route53_zone.hosted_zone.zone_id
}
output "cloudfront_distribution_hosted_zone_id" {
value = aws_cloudfront_distribution.cdn.hosted_zone_id
}
These outputs extract various pieces of information about the resources that were created, such as the domain name of the CloudFront distribution, the name of the S3 bucket, the name of the Route 53 zone, the ARN of the ACM certificate, the ID of the Route 53 zone, and the hosted zone ID of the CloudFront distribution.
With these variables, data sources, and outputs, I was able to create a flexible and reusable Terraform configuration.
Creating a GitHub Repository and Uploading the Project
To manage and version control my project, I used GitHub, a web-based hosting service for version control using Git. Here's how I set up my GitHub repository:
Create a new repository: On GitHub, I clicked on the '+' button in the upper right corner and selected 'New repository'. I gave the repository a name, set it to public (you can also set it to private if you prefer), and clicked 'Create repository'.
Clone the repository to my local machine: I opened a terminal on my local machine, navigated to the directory where I wanted to store the project, and ran the command
git clonehttps://github.com/username/repository.git, replacing 'username' and 'repository' with my GitHub username and the name of the repository I just created.Add the project files to the repository: I moved all my project files, including the Terraform configuration files and the
resume-sitedirectory, into the cloned repository directory on my local machine.Commit and push the changes: In the terminal, I navigated to the repository directory and ran the following commands:
git add .to stage all the new files for commit.git commit -m "Initial commit"to commit the changes with a message.git push origin mainto push the changes to the main branch of the repository on GitHub.
With these steps, my project was now on GitHub and under version control. Any changes I made to the project could be tracked and managed through Git and GitHub.
In addition to version control, GitHub also provides other features that are useful for project management, such as issues for tracking bugs and feature requests, pull requests for managing code reviews, and actions for automating tasks like CI/CD, which I used to automatically deploy my resume website whenever I pushed changes to the deploy branch.
Integrating CI/CD with GitHub Actions
Continuous Integration/Continuous Deployment (CI/CD) is a method to frequently deliver apps to customers by introducing automation into the stages of app development. The main concepts attributed to CI/CD are continuous integration, continuous delivery, and continuous deployment. For this project, I used GitHub Actions to implement a CI/CD pipeline that automatically deploys my resume website whenever I push to the deploy branch. Here's how I set up the GitHub Actions workflow:
name: Terraform Plan and Build
on:
push:
branches:
- deploy
workflow_dispatch:
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
AWS_REGION: ${{ secrets.AWS_REGION }}
AWS_S3_BUCKET: ${{ secrets.AWS_S3_BUCKET }}
jobs:
terraform_plan:
name: 'Terraform Plan'
runs-on: ubuntu-latest
environment: Production
defaults:
run:
shell: bash
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Set up Terraform
uses: hashicorp/setup-terraform@v1
- name: Terraform Init
run: terraform init
- name: Terraform Plan
run: terraform plan
terraform_apply:
name: 'Terraform Build'
runs-on: ubuntu-latest
needs: [terraform_plan]
environment: dev
defaults:
run:
shell: bash
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Set up Terraform
uses: hashicorp/setup-terraform@v1
- name: Terraform Init
run: terraform init
- name: Terraform apply
run: |
terraform apply -auto-approve
upload:
runs-on: ubuntu-latest
needs: [terraform_apply]
steps:
- uses: actions/checkout@v2
- name: Copy file to S3
shell: bash
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
AWS_REGION: ${{ secrets.AWS_REGION }}
AWS_S3_BUCKET: ${{ secrets.AWS_S3_BUCKET }}
run: |
aws configure set aws_access_key_id $AWS_ACCESS_KEY_ID
aws configure set aws_secret_access_key $AWS_SECRET_ACCESS_KEY
aws configure set default.region $AWS_REGION
aws s3 sync --delete ./resume-site/ s3://$AWS_S3_BUCKET/
sleep 5
This workflow is divided into three jobs: terraform_plan, terraform_apply, and upload.
The terraform_plan job checks out the code, sets up Terraform, initializes the Terraform configuration, and creates a plan for the changes to be made.
The terraform_apply job, which depends on the terraform_plan job, applies the changes to the AWS resources.
The upload job, which depends on the terraform_apply job, syncs the contents of the resume-site directory to the S3 bucket, effectively deploying the website.
The env section at the top of the workflow defines environment variables that are used throughout the workflow. These variables are stored as secrets in the GitHub repository to keep them secure.
With this setup, each push to the deploy branch triggers the workflow, ensuring that my resume website is always up-to-date with the latest changes.
Conclusion
Building a cloud resume using AWS services and Terraform was a challenging yet rewarding experience. It allowed me to delve into various AWS services like S3, CloudFront, Route 53, DynamoDB, and Lambda, and understand how they interact with each other. It also gave me the opportunity to learn about Infrastructure as Code (IaC) using Terraform, which is a powerful tool for managing and provisioning cloud resources.
The project also involved setting up a CI/CD pipeline using GitHub Actions, which automated the process of deploying the website whenever changes were pushed to the repository. This not only streamlined the development process but also ensured that the live website was always up-to-date with the latest changes.
Moreover, the project was a great exercise in learning how to secure and manage AWS credentials, handle domain names and SSL certificates, and work with HTML/CSS for website design.
Overall, this project was a great hands-on experience in cloud computing, IaC, and CI/CD, and I would highly recommend it to anyone looking to gain practical experience in these areas.
Remember, the best way to learn is by doing. So, don't hesitate to get your hands dirty and start building. Happy coding!
Subscribe to my newsletter
Read articles from Kalyan viswanath directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by