What is a Key-Value Database?
 Memgraph
Memgraph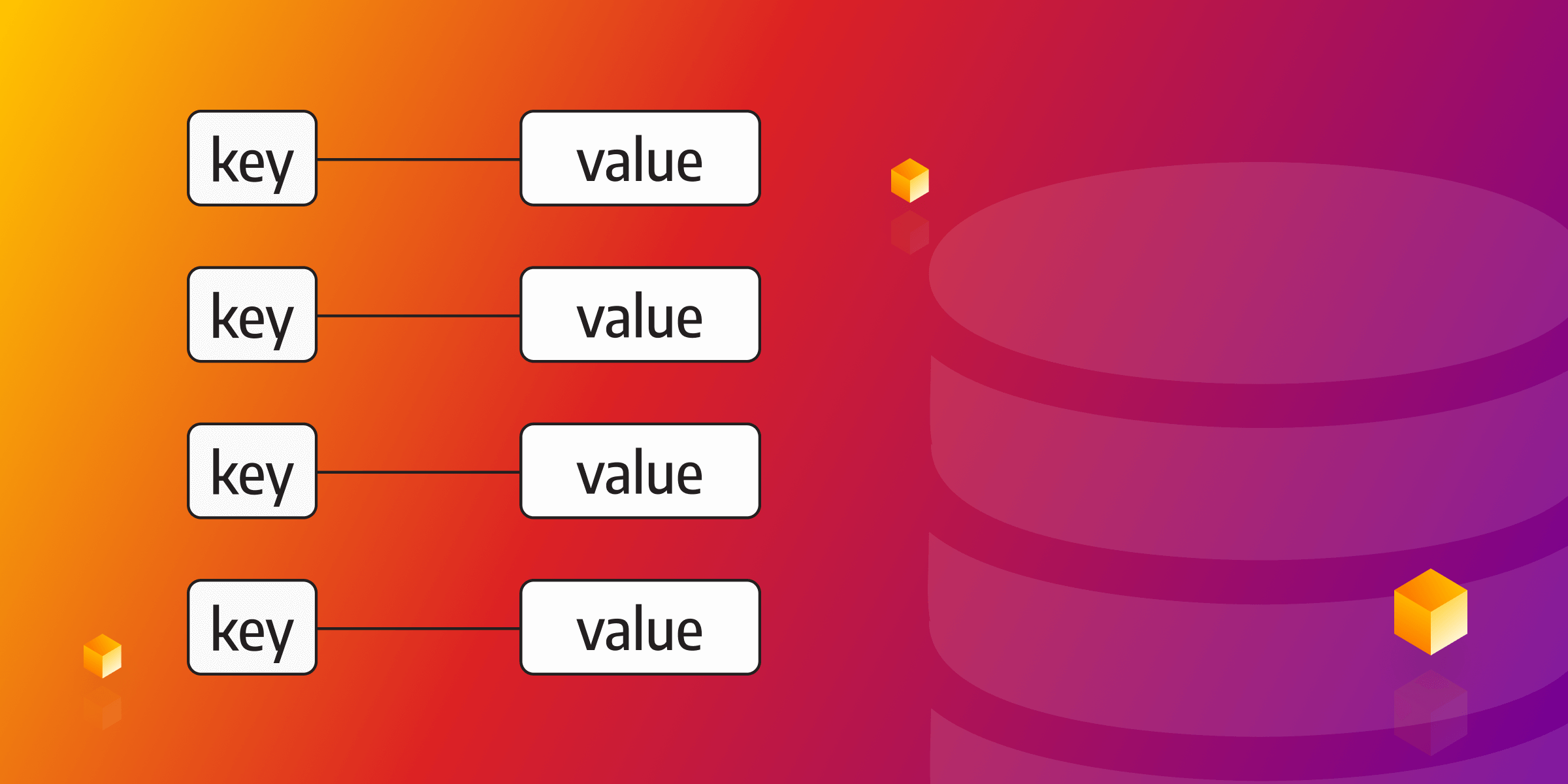
In the landscape of data management solutions, key-value databases stand apart, offering a unique blend of simplicity and performance tailored to the big data era. By abstracting data into simple key-value pairs and values, this type of database offers an intuitive and flexible data model that can seamlessly scale to accommodate large datasets. Before delving into the complexities of key-value databases, their advantages, use cases, and potential drawbacks, let's first establish a foundational understanding of these databases and how they represent a distinctive paradigm in data storage and retrieval.
Understanding a key-value store
In the ever-expanding world of databases, key-value databases have emerged as a vital element. They are designed for storing, retrieving, and managing associative arrays, a data structure commonly known as a dictionary or hash table. The dictionary contains a collection of records, each with different fields containing data. These records are stored and retrieved using a unique key. This unique approach to data management differs from traditional relational databases and makes a key-value database an optimal solution for use cases where simplicity, speed, and scalability are paramount. Key-value databases are the simplest form of NoSQL databases. Each item in the database is stored as an attribute name, or key, together with its value.
Defining key-value stores
A key-value database, or key-value store, uses a simple key-value method to store data. Each key-value pair represents a specific piece of data. The 'key' serves as a unique identifier that is used to find the data within the database. Key-value databases treat the data as a single opaque collection, which may have different fields for every record. This offers considerable flexibility and more closely aligns with modern concepts like object-oriented programming.
The primary features of a key-value database include simplicity, high performance, and the ability to handle large volumes of data efficiently. Because placeholders or input parameters do not represent optional values, key-value databases often use far less memory to store the same data, which can lead to significant performance gains in certain workloads.

Working with a key-value database
Key-value databases are known for their ease of use, making them a good starting point for beginners in the database realm. Thanks to their straightforward data structure, they provide a simple, user-friendly interface. The process involves storing unique keys associated with their corresponding data values and retrieving the associated value using its unique key.
Key-value databases excel in use cases that involve frequently accessed data. For instance, in e-commerce platforms, a key-value database could be used to store product details. The unique identifier or 'key' could be the product ID, with all the related product data stored as the associated 'value'. Another scenario is user logs, where key-value stores prove to be efficient. Popular key-value database examples include Redis, DynamoDB, Riak, and RocksDB have active community support and extensive documentation, making it easier for developers to get started and troubleshoot issues.
Benefits and advantages of a key-value database
Developers and organizations choose key-value databases for several reasons.
Speed
One of the main reasons is their speed. Key-value databases can handle large volumes of reads and writes with minimal latency. The simplicity of the data structures used in a key-value store makes it easy for developers to quickly store and retrieve data. They offer impressive speed and performance, handling large volumes of data and providing rapid, random data access.
Horizontal scaling
Scalability is a critical factor for modern applications dealing with ever-growing data volumes and increasing user demands. Key-value stores offer an advantage in this area, as they can easily scale horizontally. Horizontal scaling involves adding more servers to the existing network to distribute the data and workload across multiple nodes. As a result, key-value databases can maintain their performance levels even as data grows, ensuring that applications can handle a high number of concurrent users and massive data storage needs. This ability to scale out effectively makes them a preferred choice for applications that require elasticity and flexibility.

Ease of use and development
Key-value databases provide a simple and straightforward interface for data storage and retrieval. Developers can easily interact with the database using basic operations like "get" and "put" based on the associated keys. The straightforward API and data model reduce the complexity of the application code, making it easier to develop and maintain. Additionally, the ease of integration with various programming languages and frameworks allows developers to quickly incorporate key-value stores into their applications without a steep learning curve.
Flexible data models
Key-value databases are schema-less, meaning that they do not enforce a fixed data structure or data types. This flexibility allows developers to store and manage various types of data within the same database without strict predefined schemas. This is particularly advantageous for applications dealing with diverse and evolving data formats. Whether it's storing user profiles, session data, configurations, or complex objects, key-value databases can handle different data formats efficiently, eliminating the need for complex and costly data transformations.
Potential drawbacks of a key-value database
While key-value databases are powerful, they aren't always the ideal choice.
Complex queries
They lack the ability to perform complex queries or handle sophisticated relationships between data, which relational databases excel at. If your use case involves complex queries or requires understanding the relationships between different data entities, then a relational database or a graph database might be a better fit. Also, they may not be suitable for applications that require multi-record transactions or complex data manipulation.
Lack of data relationships
Key-value databases do not inherently support relationships between data items. While data can be organized and retrieved efficiently based on keys, establishing complex relationships between different pieces of data requires additional application logic. This can lead to potential data inconsistencies and increased complexity in managing relationships outside the database layer. For applications heavily reliant on data relationships, such as social networks or recommendation systems, graph databases may provide more natural and performant solutions, as they are specifically designed to handle and traverse complex data relationships efficiently.
Handling complex data types
Another challenge with key-value databases is the handling of complex data types. While they can handle structured, semi-structured, and unstructured data, they lack the advanced capabilities of a document database in managing complex objects.
Data size and indexing
As the data size grows significantly, key-value databases may face challenges with indexing and maintaining performance. While they excel at handling fast key-based lookups, large datasets can impact the efficiency of these operations. Proper index design and tuning are crucial to ensure optimal performance. Additionally, some key-value databases may not offer sophisticated indexing options, limiting their capabilities to efficiently handle specific types of queries or data access patterns.
Overcoming limitations of a key-value database
Despite these limitations, there are strategies and tools that can help overcome them. For example, secondary indexing and query languages like Redis's RediSearch and Amazon DynamoDB's Query Language can help perform more complex queries. Hybrid models, combining a key-value database with other database types like document databases, can handle complex queries or manage complex relationships between data entities. Additional technologies that can be incorporated into key-value databases to enhance functionality include secondary indexing to create efficient index structures to accelerate application responses.

Takeaways
Key-value databases offer a compelling mix of simplicity, speed, and scalability that can be highly beneficial in certain situations. As with any technology, it's important to understand its strengths and weaknesses to make the most of it. The key-value database world is constantly evolving, and it's an exciting area to explore for any developer or organization looking to optimize their data storage and retrieval needs.
They are a fantastic choice for use cases that involve handling large volumes of frequently accessed data or where horizontal scalability is required. However, it's crucial to understand the capabilities and limitations of key-value databases before choosing them as a solution. Overall, with ongoing evolution and innovation in the database world, the future looks promising for the key-value database scene.
Subscribe to my newsletter
Read articles from Memgraph directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Memgraph
Memgraph
Open Source Graph Database Built For Real-Time Streaming Data, Compatible With Neo4j.