Exploring AWS: My Journey through labs and learnings
 Kavya Bhalodia
Kavya Bhalodia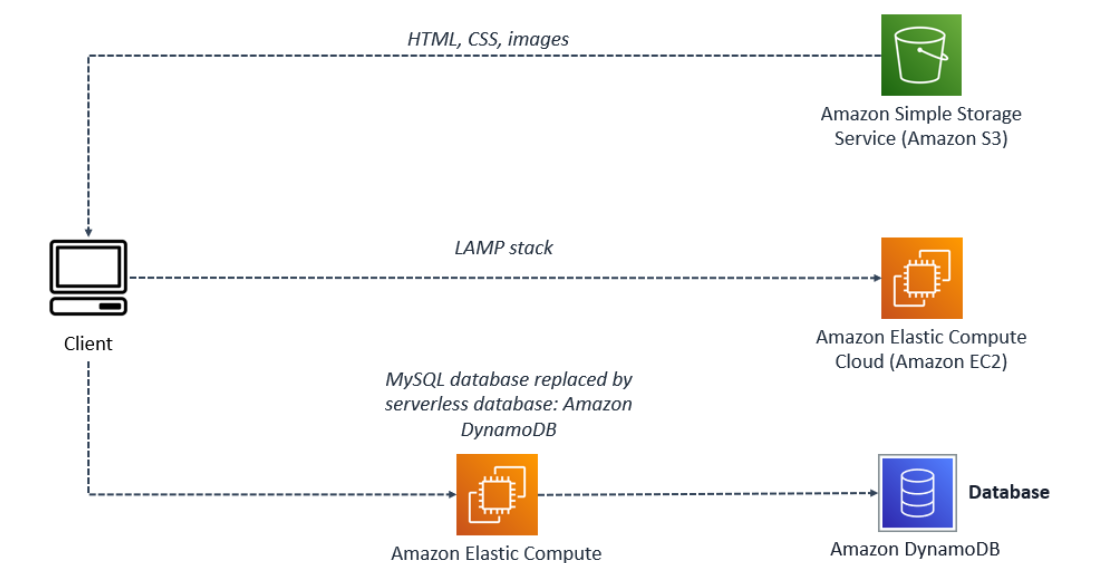
Welcome to my blog! Here, I'll be sharing what I've learned from my AWS labs. Let's explore different services and their practical uses in the cloud. Join me on this journey to understand the incredible possibilities of AWS in simple terms.
Here's the link to the free labs available on AWS: http://bit.ly/free-3labs
Lab 1: Evolution of a website: Going from a single server to serverless
In Lab 1, we were given a real-life scenario where a company wanted to create a static website displaying their ice cream flavors. We followed the given instructions and uploaded the object after writing the source code.
As the business grew, customers requested new features on the website, such as seeing the flavor of the day or knowing when a flavor sold out. To meet these demands, we suggested migrating the server to an Amazon EC2 instance with LAMP installed. This setup would allow the website to generate dynamic content using a database, enabling us to update flavors in real time as inventory changed.
We chose Amazon EC2 with LAMP for several reasons:
Scalability: EC2 provides scalable compute resources, allowing us to easily adjust the instance's capacity based on traffic and usage. This ensures the website can handle increasing loads as it grows.
Flexibility: EC2 instances with LAMP installed offer a high degree of flexibility in configuration. We can choose different instance types, operating systems, and customize the LAMP stack to suit our specific needs.
Web Hosting: LAMP is well-suited for hosting websites and web applications. Apache serves as a robust web server, while PHP enables powerful server-side scripting for dynamic content.
Database Support: MySQL, an open-source relational database management system, complements the LAMP stack, allowing efficient data storage and management.
Development Environment: EC2 with LAMP provides an excellent environment for web application development and testing, allowing us to work with a cloud-based infrastructure before deploying to production.
Further, there was a task to replace the current MySQL server with Dynamo DB as the MySQL database server can't handle the high traffic, and customers are facing errors when trying to access the website.
Here's what I learned in terms of choosing between databases:
Dynamo DB will work over MySQL:
High-performance: DynamoDB offers fast data access, making it great for applications that need quick responses. It works well for applications with high read-and-write activity.
NoSQL flexibility: DynamoDB allows you to work with flexible data structures, which is useful when dealing with data that doesn't fit into a fixed pattern, like in traditional relational databases.
Fully managed service: DynamoDB is fully managed by AWS, meaning you don't have to worry about handling database servers, backups, or scaling. AWS takes care of all that for you.
Global replication: DynamoDB supports global tables, which replicate data across different AWS regions. This ensures data can be accessed with low latency from anywhere in the world and improves fault tolerance.
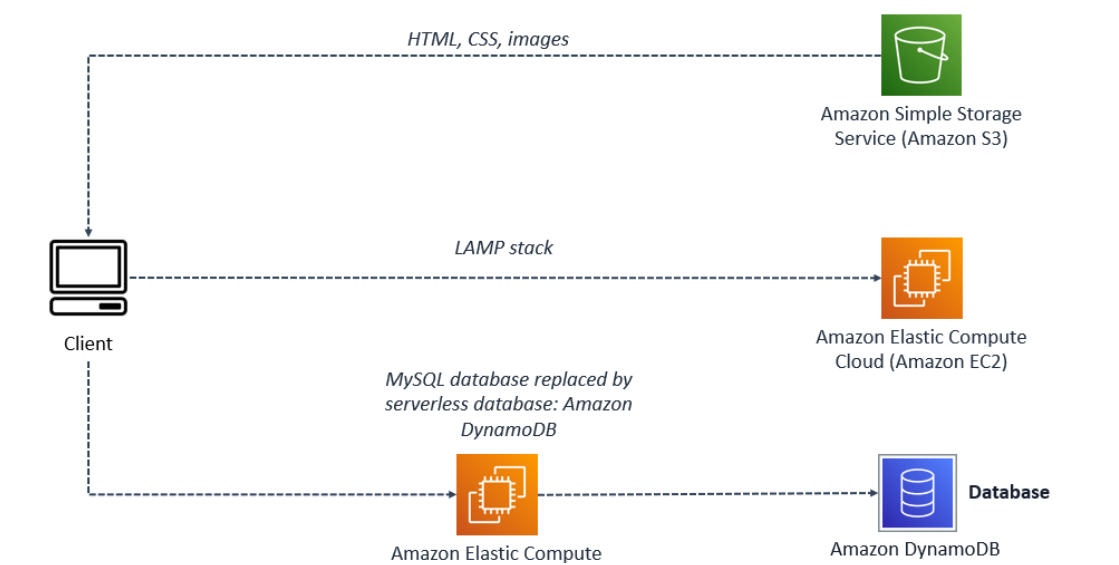
Lab 2: Serverless Architectures with Amazon DynamoDB and Amazon Kinesis Streams with AWS Lambda
Part 1:
In this lab, I delved into event-driven programming with Kinesis and Lambda.
The first step involved configuring a Data Stream via Amazon Kinesis, a platform that enables real-time processing of massive-scale streaming data.
Amazon Kinesis can collect and process hundreds of terabytes of data per hour from hundreds of thousands of sources.
Using Amazon Kinesis applications, data can be easily sent to other services like Amazon S3, Amazon DynamoDB, Amazon Lambda, or Amazon Redshift.
During the configuration process, I encountered the concept of "Shards," which serve as the base throughput unit of a Kinesis data stream.
A shard supports 1 MB/second and 1,000 records per second for writes and 2 MB/second for reads.
After setting up the Data Stream, the next step was to configure a Lambda function that gets triggered by incoming data streams.
This involved using blueprints to create the function and assign an existing role to the service.
Blueprints provide sample code and function configuration presets for Node.js and Python runtimes.
The Lambda function efficiently loops through each received record, decodes the data (encoded in base64), and prints the data along with debug logs.
This comprehensive approach to event-driven programming has broadened my horizons and unlocked exciting possibilities for real-time data processing.
Part 2:
In part two of the lab, we explored Event-Driven Programming with Amazon DynamoDB and AWS Lambda. The goal was to create two tables in DynamoDB to store game scores for users and set corresponding partition keys for each table.
Here's a breakdown of the steps involved:
Create Tables: We created two tables in DynamoDB according to the instructions. Each table is designed to store game scores for a user. The essential aspect here is to set the appropriate partition key for each table.
- Partition Key: The partition key serves as a simple primary key for DynamoDB. It is a crucial element because DynamoDB uses the partition key's value as an input to an internal hash function. The output of this hash function determines the partition in which the item (i.e., game score entry) will be stored. Essentially, the location of each item is determined by the hash value of its partition key.
Activate DynamoDB Streams: After creating the first table, we activated DynamoDB Streams on it. By enabling DynamoDB Streams, the table starts generating streaming data whenever there is any change to the table, such as an item being inserted, updated, or deleted.
Create Lambda Function: With DynamoDB Streams now active, we created a Lambda function. The purpose of this function is to update the score table whenever an event occurs in the first DynamoDB table. The function is designed to respond to streaming data generated by changes in the first table.
Configure Event Trigger: To ensure that the Lambda function can be triggered by the events from DynamoDB Streams, we needed to configure the event. This configuration establishes the connection between the DynamoDB table's stream and the Lambda function. As a result, the Lambda function will be automatically invoked whenever there is a relevant change in the first DynamoDB table.
In summary, by following these steps, we set up a powerful event-driven system using Amazon DynamoDB and AWS Lambda. This architecture allows us to seamlessly capture and process changes to game scores in real-time, ensuring an up-to-date and responsive user experience.
Lab 3: Frontend is for Everyone
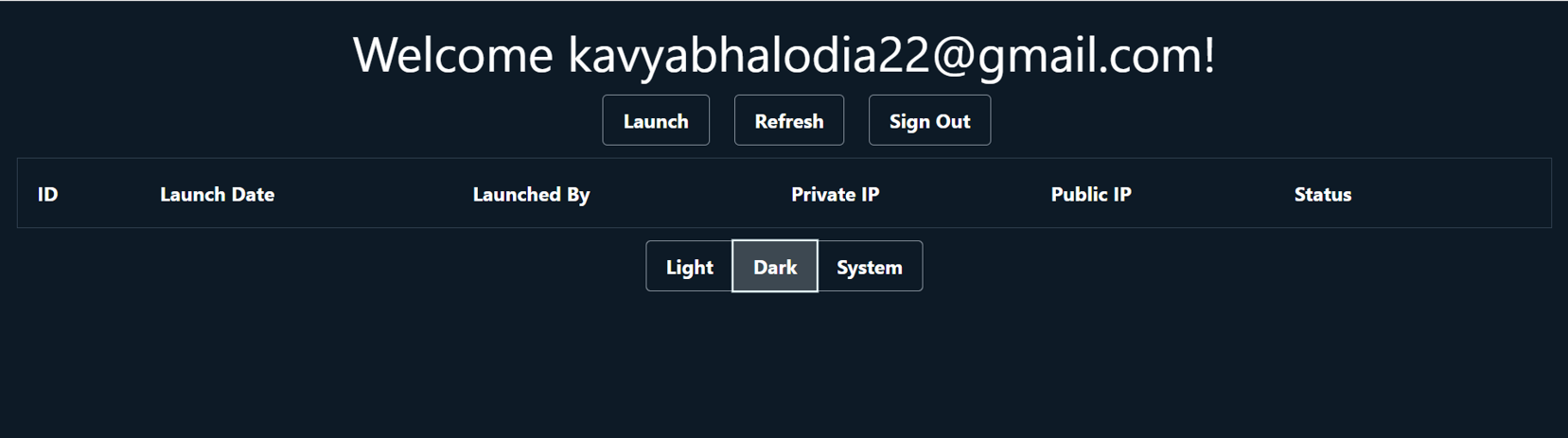
The objective of the lab is to build a Vendor App on ec2 using Amazon Amplify. The App after signing in helps to launch and terminate instances using buttons.
Created a react app using CRA(Command line React App)
Used Amplify UI, a component library, instead of HTML elements to build App
Installed the Amplify CLI, created an Amplify app with an AWS IAM permissions boundary, and added authentication services using Amazon Cognito
Then used AWS Amplify to create a Node.js Lambda function. This Lambda function will serve as an API endpoint to interact with the EC2 service using the AWS SDK.
setting up a system that allows users to query Amazon Machine Images (AMIs) from the frontend of your application.
Final result may look similar to this: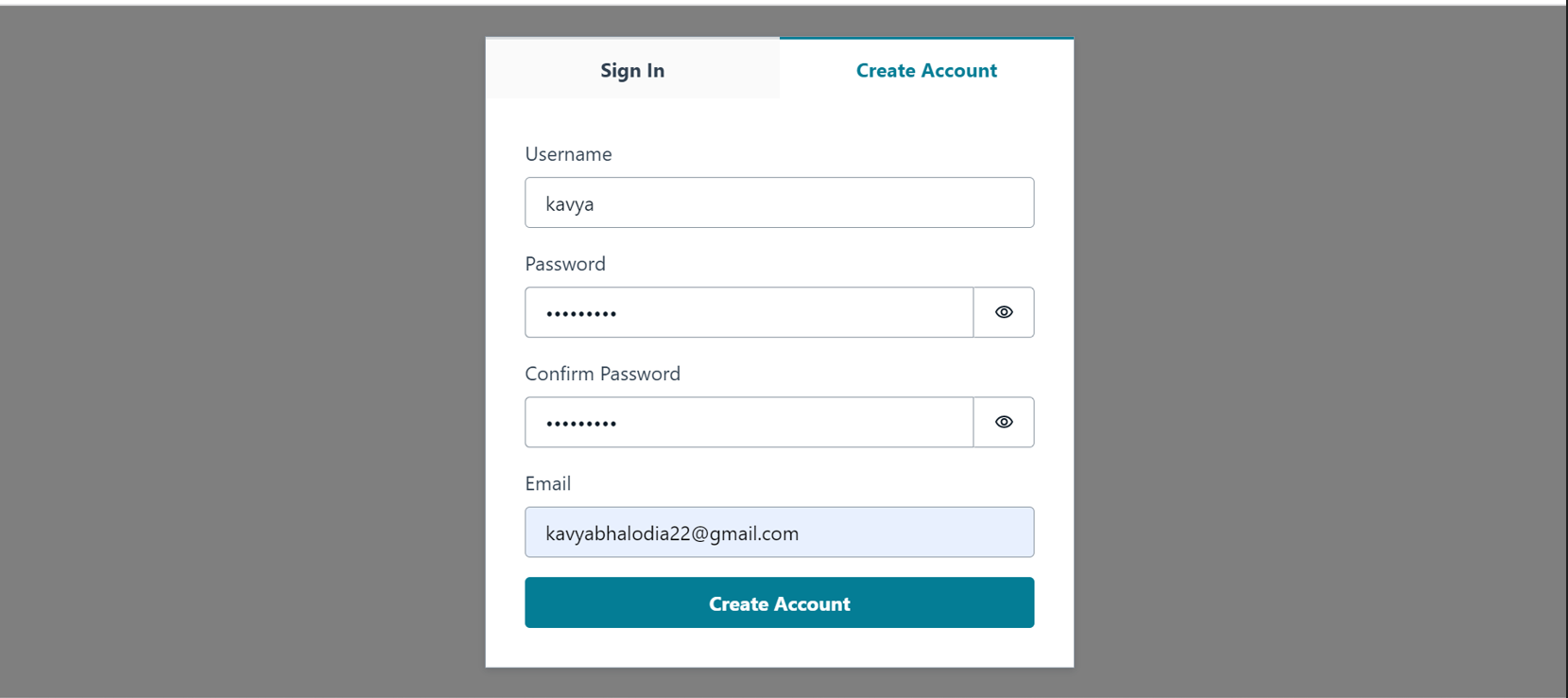
Subscribe to my newsletter
Read articles from Kavya Bhalodia directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by