Getting Started with Redis: Unleashing Lightning-Fast Data Retrieval
 Ankush Banik
Ankush Banik
Introduction:
Redis is often touted as a game-changing technology for faster data retrieval from storage. And let me tell you, the hype is true. If you're considering learning Redis or are unsure whether it's worth your time, you've come to the right place. This blog will cover how Redis outperforms other servers, how to get started with Redis, and its pros and cons. By the end, you'll have a clear understanding of Redis and can make an informed decision about whether to pursue it.
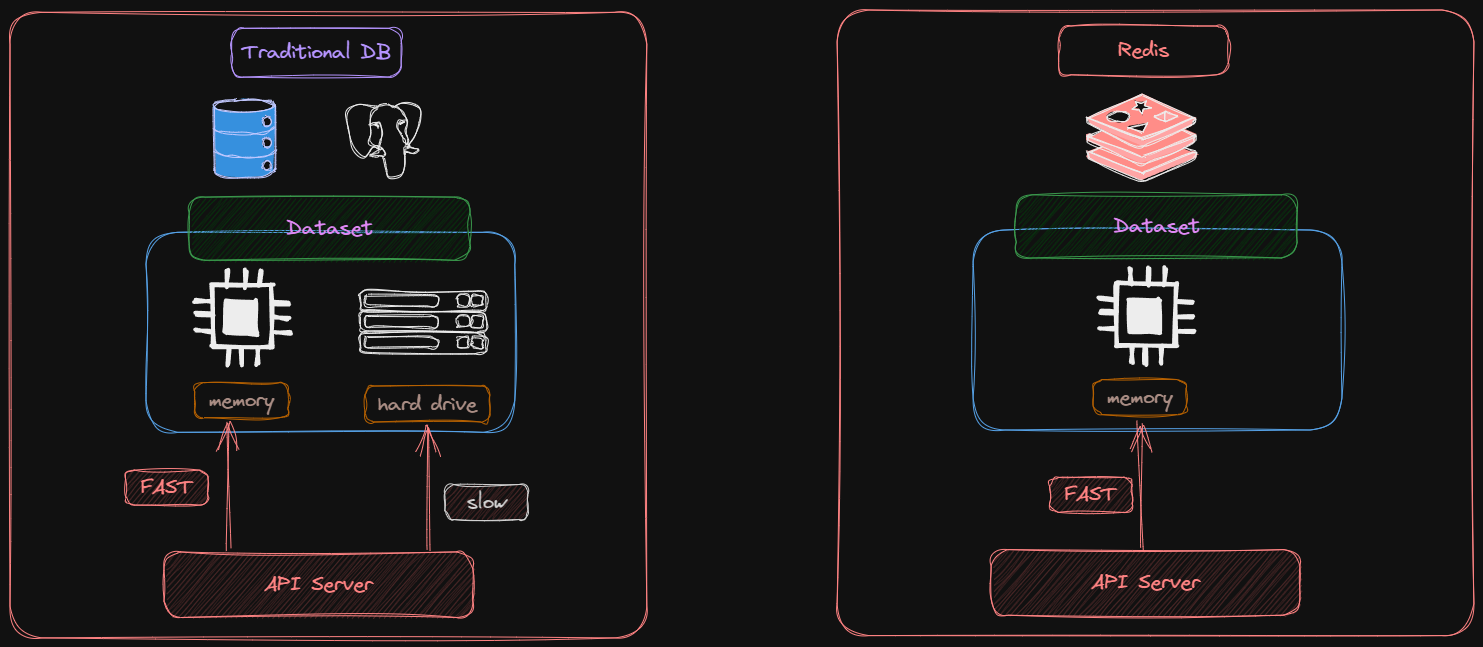
Why Redis is Fast:
According to Google, it's an "in-memory data store". But what does that mean? Unlike other data storage systems, Redis stores all of its data in memory. This may not sound important, but it actually makes a big difference. Most servers, including SQL and MySQL, store data on disk and in memory, but Redis only uses memory. Retrieving data from memory is much faster than retrieving it from disk, which can be time-consuming. Additionally, Redis uses well-known data structures like "doubly linked lists" and "sorted sets" to organize its data. This makes it more efficient than other servers that use fancy features which can negatively impact performance. Overall, Redis has a simple feature set, which ensures fast and efficient performance.
Pros of Redis:
There are several advantages to using Redis as a data storage system:
Redis is an "in-memory data store", which means it stores all data in memory. This allows for faster response times compared to other data storage methods.
Redis uses well-known data structures such as "doubly linked lists" and "sorted sets" to organize its data, which makes it easier to work with.
Unlike other data storage systems, Redis does not have complicated features, making it simple and user-friendly.
Redis is compatible with other data storage systems such as SQL and NoSQL, making it a versatile option for data storage needs.
Cons of Redis:
There are several downsides to using Redis as a data storage system.
Firstly, Redis is an "In-memory data storage" which means that all data is stored in memory. This can be problematic because memory has limited storage capacity compared to a disk. Therefore, if you have 10GB of data and only 8GB of memory, you won't be able to store all the data in Redis.
Secondly, due to its limited storage capacity, Redis requires careful consideration before implementation. You cannot simply throw everything into memory without thinking about the consequences.
Thirdly, Redis lacks key features that other services have. For example, it does not enforce data schema, foreign key constraints, uniqueness of arbitrary properties or transaction rollback.
Lastly, Redis is an expensive option. While it uses a cache to store data in memory, which is faster than the primary data store, this comes at a cost. So, there is a trade-off between price and speed when using Redis.
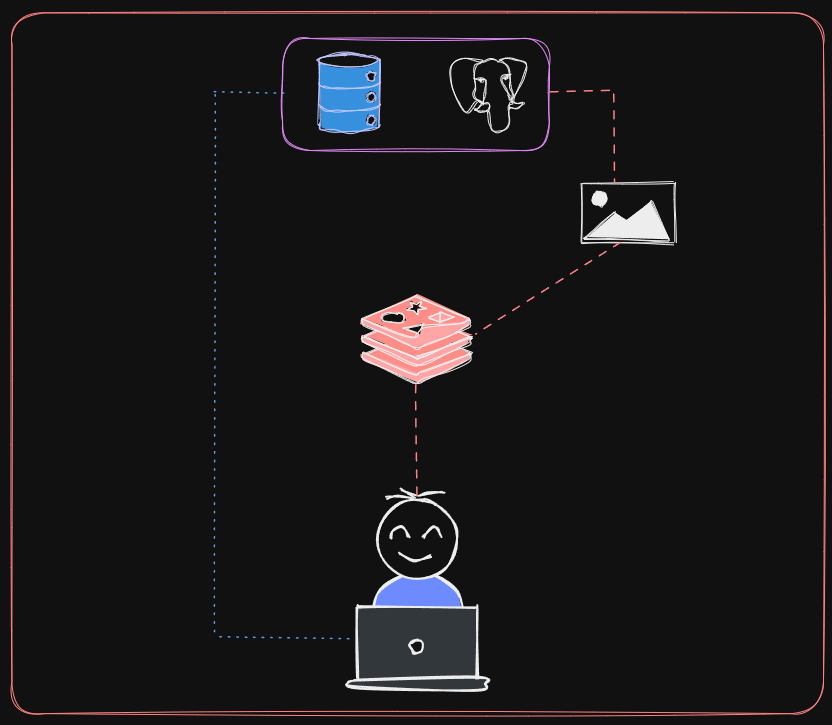
How to use it effectively:
As Redis is a well-known database that uses various data structures to store data in memory, including Set, Hash, sorted set & Hyper log log, it's important to know how to use it effectively. For example, Hash stores data in a key -> (field -> value) format. To illustrate, let's consider a JSON data set and explore how to store it in Redis using Hash.
The JSON data looks like this:
{
Name: “Ankush Banik”,
Age: 22,
Height: 5.7
Company: “Netflix”,
Status: “Full-Stack Dev”
}
While it's possible to store this data as is in MongoDB or any database and retrieve it later, Redis works differently. Instead of retrieving data from a database, Redis pulls a copy of the data from its cache. Therefore, the cache data is created when the JSON data is pushed into MongoDB.
To store data in Redis using Hash, there are two approaches.
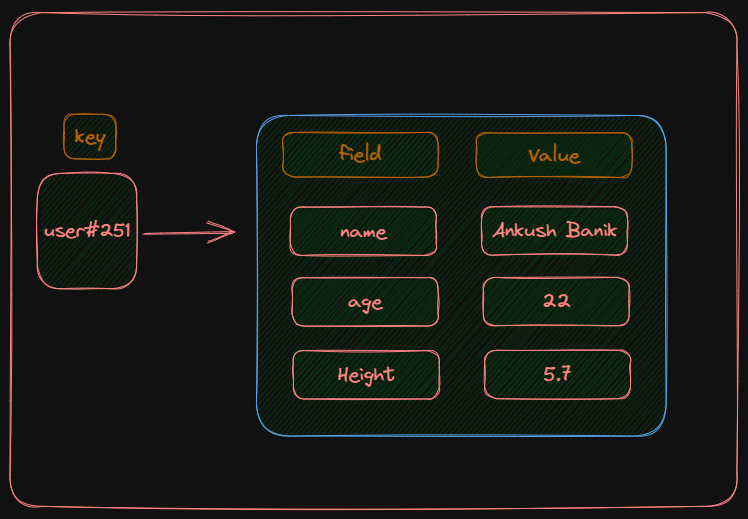
- The first is to create a user key that looks like this: “user#{_id}”. Here, id refers to the user's ID. Then, JSON keys are used as fields and JSON values as values in Redis Hash. The end result is “user#{id}” as a key and Name, Age, Height, Company and Status as fields, and “Ankush Banik”, 22, 5.7, “Netflix”, “Full-Stack dev” as values. However, this approach is not suitable for big and complex JSON data but works well for smaller data sets.
One of my favourite approaches is what I call the "Snapshot" method. Although this is not an official name, it is a term I use to refer to this method. Let me explain how this method works.
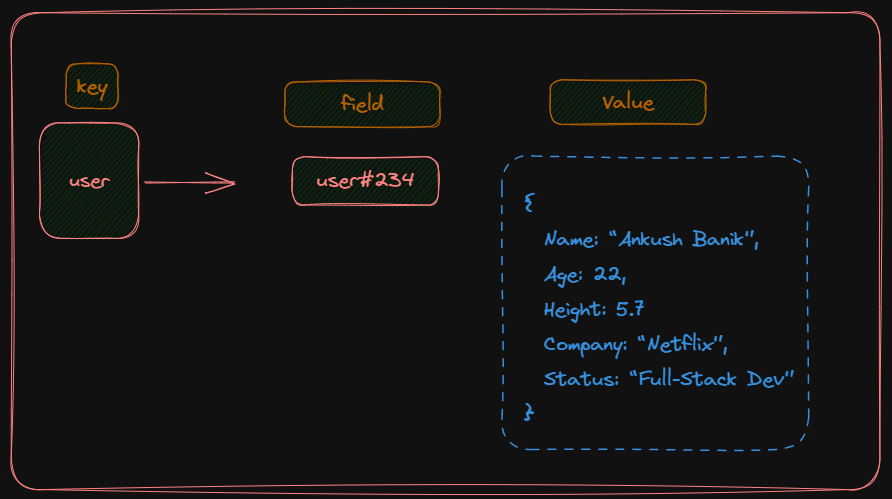
First, we have JSON data that needs to be uploaded to a Redis Hash. Instead of using traditional key, field, and value, we group the data into different categories or groups. For example, an e-commerce site may have groups like "user", "product", and "brand". In this example, we can use the "user" group as a key in Redis Hash.
For the field, we can use the user ID and format it as "user{_id}". Finally, for the value, we can use the entire JSON data. In JavaScript, we can easily convert an object into a string using JSON.stringify() function. This string can then be added to the Redis Hash. When we need to retrieve the data, we can use the JSON.parse() method to convert the string back into an object.
The advantage of using this method is that we don't need to write all the JSON keys as field values in Redis Hash. This saves time and reduces the complexity of the data.
But there are also some disadvantages. Redis doesn't provide any function to update its values, so when we need to update the JSON data, we have to delete the old cache and create a new one. This means that if a user updates a portion of the data, we need to take a new snapshot of the data and present it to the user.
Despite this drawback, the Snapshot method is very useful for scaling complex data and retrieving all the data at once. Compared to pulling a set of massive data from MongoDB, which can take 5-7 seconds, pulling the same amount of data from Redis takes only 200-500 milliseconds.
Conclusion:
In conclusion, Redis offers an efficient solution for retrieving data at lightning speed despite the various drawbacks and disadvantages it presents. The benefits of Redis are clear and evident, and if you envision yourself pursuing a career as a back-end engineer, learning Redis is a must. Numerous companies rely on Redis as a cache database to obtain faster and more efficient data. Therefore, I strongly believe that Redis is worth learning.
Subscribe to my newsletter
Read articles from Ankush Banik directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ankush Banik
Ankush Banik
Hello there!👋 I am Ankush, a Full-Stack developer🥑 and Open Source contributor🚀. Nice to meet you!