The Art and Science of Web Scraping
 Njeri Gitome
Njeri Gitome
In the digital era, the internet teems with a wealth of information that when harnessed and utilized well has proven to be invaluable. Like a virtual archaeologist, equipped with digital tools, we take delve into the webspace, sifting through intricate threads of data to reveal hidden treasure through web scraping.
What is Web Scraping?
Web scraping (or data scraping) is the process of extracting data from websites.
Web scraping allows one to collect various types of data. The common data types collected include images, text, video, links and URLs, metadata, job listings, products and pricing data.
Web scraping is used for a wide range of applications across various industry domains such as analytics, data mining, content aggregation, market research and content marketing.
Web scraping requires two parts, namely the crawler and the scraper. The crawler is an Artificial Intelligence (AI) algorithm that browses the web systematically and methodically. Its main purpose is to collect information from web pages and store it for indexing or further processing. The scraper, on the other hand, is a program or script that automates the process of extracting data from websites.
How do web scrapers work?
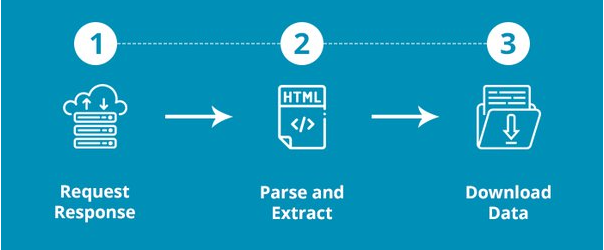
Firstly, a web scraping bot simulates the act of human browsing the website. With the target URL entered, it sends a request to the server. This is known as making an HTTP request to a server.
Once the request is approved the site gives the scraper access, and the bot can reach the node where the target data lies and parse the data as it is commanded in the scraping code. This can be summarized as extracting and parsing the website's code.
Lastly, (based on how the scraping bot is configured) the cluster of scraped data will be cleaned, structurally stored, and ready for download or transference to a database.
What tools can be used for scraping the web?
There is an array of tools and libraries available for web scraping. The choice of tools depends on the complexity of the task, the programming language and the requirements for the scraping project.
Here are some common tools:
BeautifulSoup
This is a Python library for scraping structured data. It provides convenient methods for parsing HTML and XML documents and navigating parsed data.
Scrapy
It is an open-source web-crawling framework for Python. It is used to crawl websites and extract structured data from their pages.
Selenium
Selenium is a Python library and web automation tool. It is particularly useful for scraping websites with dynamic content generated through JavaScript.
The process of web scraping
First, identify the Target Data that is to be extracted. The data format could be textual content, structured data, images and multimedia, links and URLs, Medatdata etc.
Then, identify the desired website, that contains the desired data. For example, if one wants to retrieve job posting data, one can choose a website such as LinkedIn as their desired webpage.
The next step involves studying the structure of the website. This will involve reviewing the source code of the webpage and study of the HTML elements. There are build tools in modern web browsers that enable users to easily interact with the backend of the webpage.
After carefully studying the webpage, then Locate data and HTML element tree. This in simple terms is identifying the location of the data one wishes to retrieve.
Finally, using a web scraping tool one can extract the data and store it in their desired location.
An Alternative to Web Scraping: APIs
Some websites offer Application Programming Interfaces (APIs) as a scraping option. APIs are a powerful alternative to traditional web scraping. They provide a standardized interface for interacting with external systems, enabling one to obtain data without the need to parse HTML or navigate websites.
APIs use advanced techniques such as proxy rotation, JavaScript rendering, Captcha Avoidance and text blocking to extract data from websites.
While scraping APIs are a convenient and structured alternative to web scraping, the choice between the two depends on various factors such as the nature of data required, the provider's API availability, project requirements and legal and ethical considerations. In some cases, a synergy of both web scraping usage and API may offer the most comprehensive data acquisition strategy.
Ethical Considerations in Web Scraping
Ethics in web scraping is a crucial aspect that must be carefully considered and adhered to. Here are some key ethical considerations:
Websites terms of service
Review and adhere to the website's terms of service(ToS). Some websites explicitly prohibit web scraping, while others may have some specific rules to follow.
Check for Robots.txt
The robots.txt file on a website provides instructions for web crawlers and web scrapers. It is imperative to obey the specified rules.
Data protection protocols
Just because data is available, does not mean one is allowed to scrape it. One is to be careful about laws in different jurisdictions and follow each region's data protection protocols.
Do not overload servers
It is important to be mindful of the number of requests made to a website, so as not to strain the server's resources, leading to poor website performance or even crashing it completely. Frequent and aggressive scraping should be at all costs be avoided.
Navigating Complex Websites: Overcoming Challenges in Web Scraping
As websites become more dynamic and sophisticated, web scraping can be difficult and requires significant technical knowledge and understanding.
Let's take a look at some of the hurdles in web scraping and explore strategies on how to overcome them.
Dynamic content and JavaScript Rendering
Many modern websites heavily rely on JavaScript to load content dynamically. The use of headless browsers like Puppeteer and Selenium can be explored to render JavaScript content and extract information effectively.
In addition, web scraping APIs or browser automation can be used to interact with web pages to extract data.
Handling AJAX requests
Asynchronous JavaScript and XML (AJAX) refers to a way of updating a webpage without reloading the whole page. This can prove to be an uphill task for web scrapers because AJAX requests can be hard to understand and pull.
The Headless Browsing technique can be used to overcome this setback.
Captcha and Anti-Scraping measures
Some websites implement security measures such as captures and anti-scraping mechanisms to prevent automated web scraping.
Some strategies can bypass or handle captures programmatically while maintaining ethical scraping practices. These methods focus on mimicking human behavior and avoiding harmful or aggressive practices. These include:
User Interaction Simulation - the use of headless browsers like Puppeteer and Selenium to simulate human interactions with the website.
Captcha Solving Services - using third-party Captcha solving services that employ human operators to solve captchas. These services provide APIs that can be integrated into one's code to handle captchas automatically.
Alternate Data Sources - in some cases one may encounter websites with very strict anti-scraping measures or unsolvable Captchas. It is important to consider alternative sources that do not impose such challenges.
It is crucial to note that Captcha bypassing should be done ethically and responsibly. Always check the website's terms of service and ensure that the scraping activity is legal and compliant with the website's guidelines.
Nested and Complex HTML structures
Such structures often involve multiple levels of nested elements and can be difficult to navigate. Some strategies to resolve this include:
XPath and CSS Selectors: Utilize XPath or CSS selectors to target specific elements within the HTML document. These powerful querying languages allow you to specify complex paths to reach the desired elements accurately.
Combination of Parsing Techniques: Combine different parsing techniques like BeautifulSoup and regular expressions to handle different levels of complexity within the HTML.
Using Large Language Models for Web Scraping
With the advent of Large Language Models (LLMs), a new frontier for web scraping has emerged. LLMs such as Open AI's GPT-3.5, and Google's Bard have opened up exciting possibilities for advanced web scraping.
- Use LLMs to generate web scraping code
GPT-3.5 and other similar models are trained on open-source code, this means that they can generate code in different programming languages, explain it, emulate a terminal or generate API code.
This capability of LLMs can be used to generate code to scrape websites using natural language to make a web scraper.
- Name Entity Recognition and Linking
LLMs are adept at recognizing and extracting named entities from text. By combining web scraping with LLMs, one can perform accurate Name Entity Recognition (NER) tasks, identifying entities and linking them to relevant knowledge basis.
LLMs have a promising future in the web scraping landscape. Embracing the transformative potential of LLMs in web scraping will unlock a new realm of data-driven insights.
Future Trends in Web Scraping
The future of web scraping is expected to be shaped by various emerging technological trends. Here are some future trends:
- AI-powered web scraping
Artificial Intelligence and Machine Learning will become an integral part of web scraping, enabling automation, pattern recognition and adaptive scraping techniques that enhance efficiency and accuracy.
- Human-AI collaboration
The synergy between human expertise and AI algorithms will become more pronounced. Human-AI collaboration will lead to improved data quality, reduced errors and faster insight generation.
- Growth in structured data extraction expertise
The focus on extracting structured data from unstructured sources is bound to grow as Natural Language Processing (NLP) and Computer Vision techniques improve data extraction accuracy from text, images and multimedia content.
Conclusion
Web scraping has emerged as a game-changing technique, revolutionizing data collection and analysis across industries. By harnessing the power of web scraping responsibly, one can unlock valuable insights, drive innovation, and make data-driven decisions that shape the world we live in.
Subscribe to my newsletter
Read articles from Njeri Gitome directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Njeri Gitome
Njeri Gitome
Data Scientist