Building a CLI Tool: How I Automated the Download of Kevinpowell.co Courses
 Deep Sarker
Deep Sarker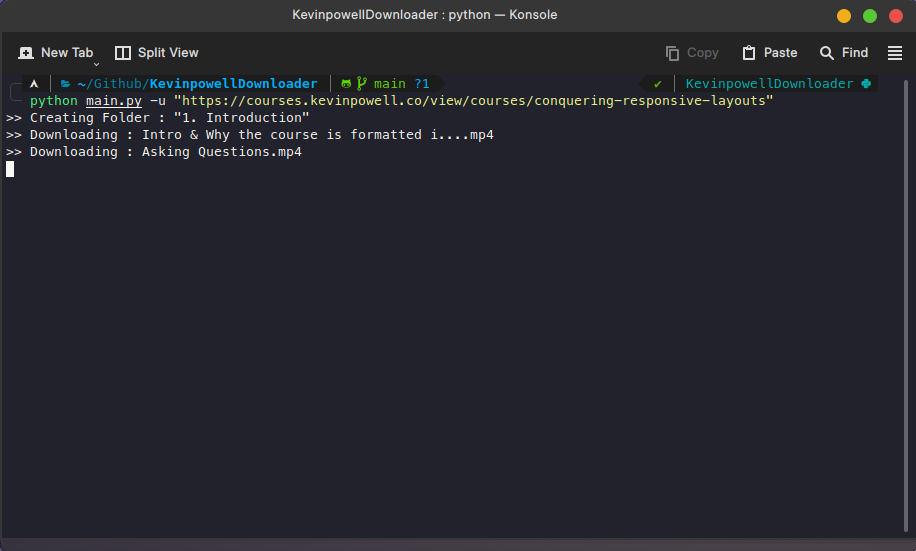
This is a CLI application to automate the download kevinpowell.co course
A few days ago, I was in search of a CSS course. A friend recommended one that emphasized responsive layout design. I began watching the tutorials and soon realized I wanted to download them for offline viewing. However, there wasn't a direct option to do so. That time I got the idea of creating a Python CLI app that would accept the course URL as input and subsequently download all the videos, organizing them by section and in the correct sequence.
To achieve this, I began intercepting network requests using Burp Suite. While it wasn't strictly necessary to use Burp Suite, I found that it simplified the process of network interception. During this phase, I identified several network requests made for the m3u8 file. I attempted to access the m3u8 files using my VLC player, and to my delight, it worked flawlessly.
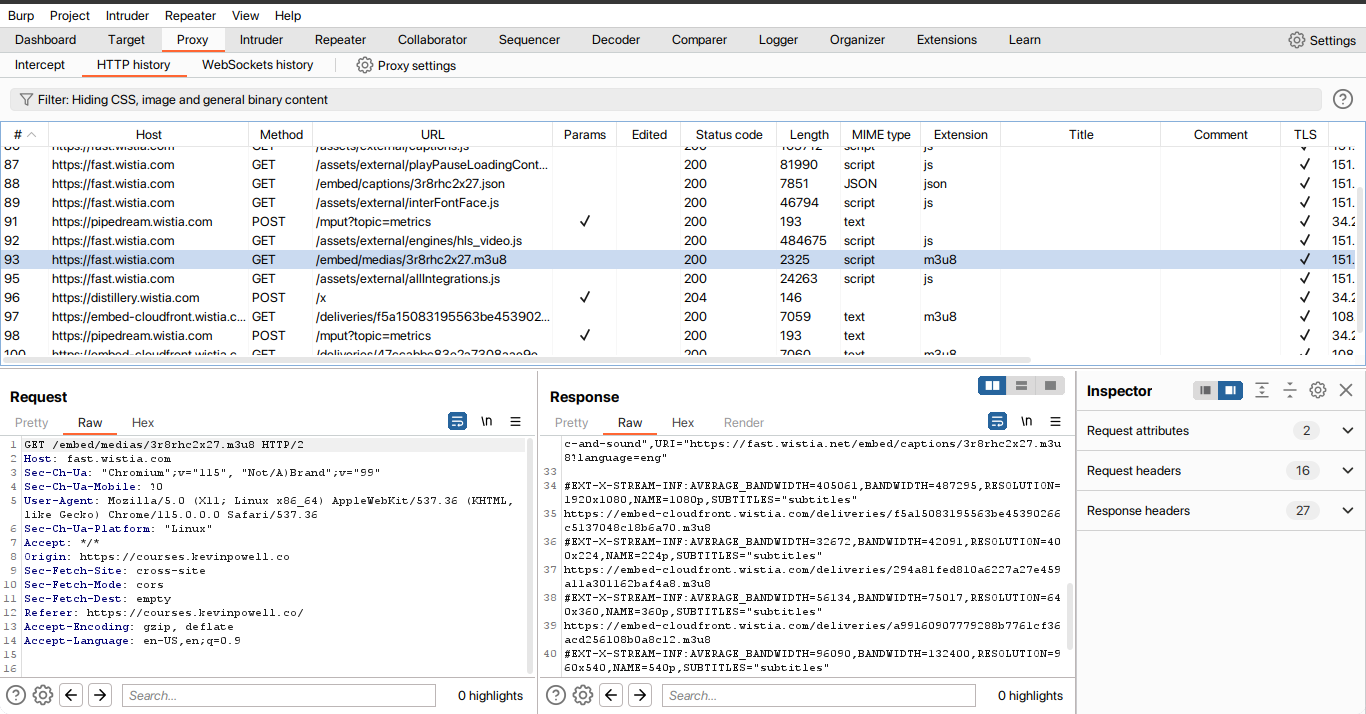
Here as you can see I found the URL with m3u8 request. This is the first m3u8 file request after loading the website. So after finding that I was looking for the source of the URL like where the URL id or something is received in the client or the DOM.
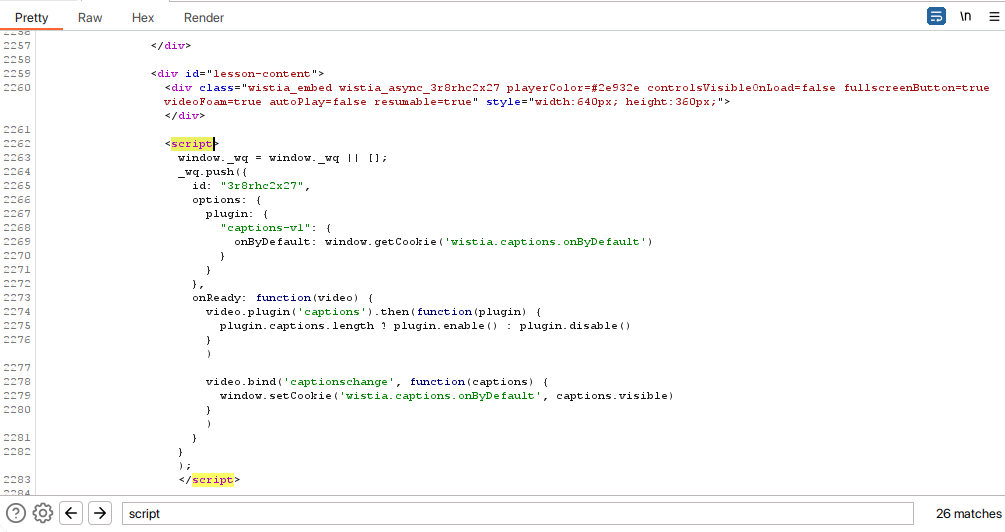
There I found something interesting. I was logged in when I was testing this and whenever I load the page initially as logged in, in the DOM there is a lot of script tag and inside one of the tags the id of the request m3u8 is there. Later I found that the script tag only loads if I am logged in. And the logged-in state is checked by a cookie value that will be discussed later
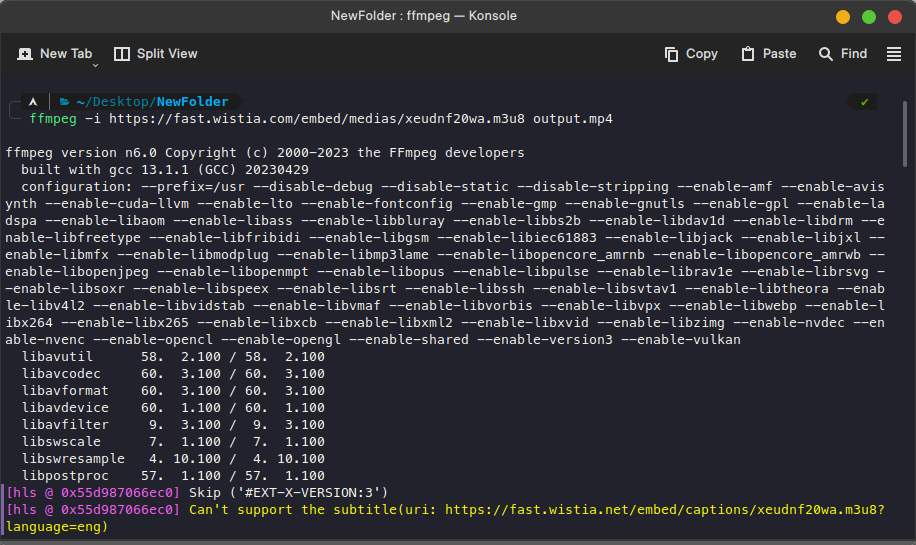
Now the problem was this the file is an m3u8 file and that file need to be streamed and encoded into an mp4 file. So I used a library FFMPEG to convert the m3u8 file into a mp4 file and it worked successfully
Now it's time to implement these things on Python code properly. The initial step is to load the course URL and fetch all the video sections and subsections to track folder and subfolders and the file and folder names. So I created the main function and there loaded the course URL and processed the HTML file with the BeautifulSoup python library. Then I iterate over the sections and extracted individual video URLs and sent the video URL to another function for future processing.
def main(url, root_folder, overwrite_file_name):
# response = requests.get("https://courses.kevinpowell.co/view/courses/conquering-responsive-layouts")
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
html_beautified = soup.find_all("li", class_="list-group list-group-menu list-group-xs mb-6")
for index, content in enumerate(html_beautified, start=1):
sub_section = content.find_all("a")
directory_info = sub_section[0]
directory = str(index) + ". " + directory_info.text.strip()
path = f"{root_folder}/{directory}/"
if not os.path.exists(path):
os.makedirs(path)
print(f'>> Creating Folder : "{directory}"')
for sub_index, sub_content in enumerate(sub_section[1:], start=1):
process_individual_video("https://courses.kevinpowell.co" + sub_content["href"], path,
str(sub_index) + ". " + sub_content.text.strip(), overwrite_file_name)
if index == 21:
break
Then I requested the individual video URL for the specific script tag. But as a non-logged user, the specific script tag doesn't load. So I had to use logged-in cookies. After doing some trial and error I found only the "**_podia_session*\"* cookie value is needed to load the m3u8 id value inside the script tag.
def process_individual_video(video_url, folder_path, file_name, overwrite_file):
if os.path.exists(folder_path + file_name + ".mp4") and overwrite_file != file_name + ".mp4":
return
headers = {
"Cookie": COOKIE
}
r = requests.get(video_url, headers=headers)
individual_video_html_soup = BeautifulSoup(r.text, "html.parser")
scripts = individual_video_html_soup.find_all("script")
script_with_video_id = scripts[-1].text
regex_course_id = r"id:.*?,"
video_id = re.finditer(regex_course_id, script_with_video_id, re.MULTILINE)
for match_of_video_id in video_id:
download_video_from_m3u8_file(
"https://fast.wistia.com/embed/medias/" + match_of_video_id.group().split(":")[-1].strip()[1:-2] + ".m3u8",
folder_path, file_name)
After getting the m3u8 file id i completed the url string for the m3u8 file in static way because all m3u8 file share the same domain. Then i sent the m3u8 file url to a different function that will download the file and encode it into mp4 file
def download_video_from_m3u8_file(m3u8_url, folder_path, file_name):
output_string = folder_path + file_name + ".mp4"
regex_file_name = r"\d."
matches_of_extras_in_filename = re.finditer(regex_file_name, file_name, re.MULTILINE)
processed_output_string_file_name = file_name
for match_in_filename in matches_of_extras_in_filename:
processed_output_string_file_name = file_name[match_in_filename.end():].lstrip()
break
print(f">> Downloading : {processed_output_string_file_name}.mp4")
subprocess.run(["ffmpeg", "-y", "-loglevel", "0", "-nostats", "-i", m3u8_url, output_string])
To enable the CLI functionality, Before the main function, i used arv functions to get the command that will be inserted in the terminal and process the application according to it.
if __name__ == '__main__':
argv = sys.argv[1:]
is_help_command_inserted = False
try:
help_command_index = argv.index("-h")
print(""" -u -> Course URL
-p -> Set Folder Path To Save Files [Optional]
-o -> Overwrite Any Existing File With File Name [Optional]
""")
is_help_command_inserted = True
except ValueError:
is_help_command_inserted = False
new_folder = "New Folder"
try:
url_command_index = argv.index("-u")
url_string = argv[url_command_index + 1]
regex = r"\/courses\/.*"
matches = re.finditer(regex, url_string, re.MULTILINE)
for match in matches:
new_folder = match.group().split("/courses/")[1].rstrip("/")
break
except (ValueError, IndexError):
url_string = ""
if not is_help_command_inserted:
print(">> Course URL Not Found !!")
print("!! Run 'python main.py -h' To See Available Commands !!")
url_command_index = -1
try:
root_folder_path_command_index = argv.index("-p")
root_folder_path = argv[root_folder_path_command_index + 1]
root_folder_path = os.path.join(root_folder_path, new_folder)
except (ValueError, IndexError):
root_folder_path = f"./{new_folder}"
try:
overwrite_command_index = argv.index("-o")
overwrite_file = argv[overwrite_command_index + 1]
except (ValueError, IndexError):
overwrite_file = ""
if url_command_index != -1:
main(url_string, root_folder_path, overwrite_file)
The usage of command lines is shown below ->
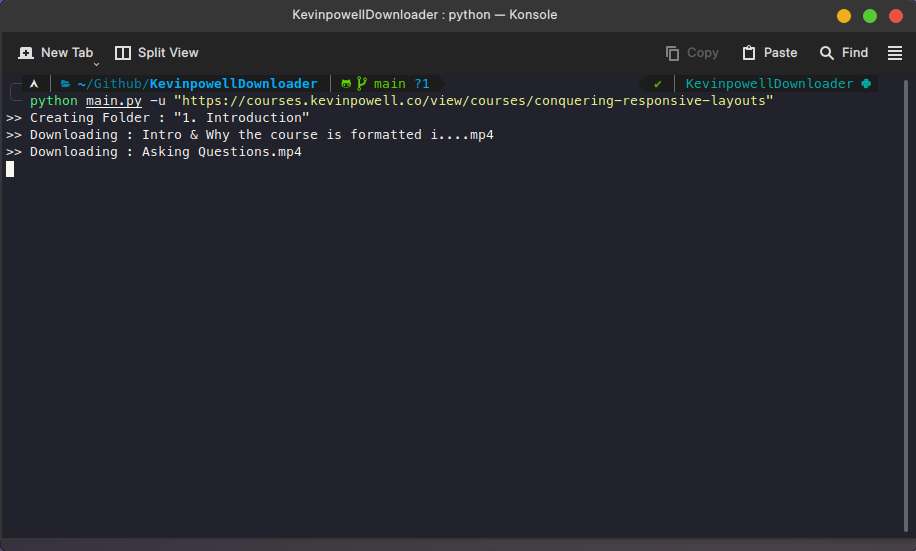
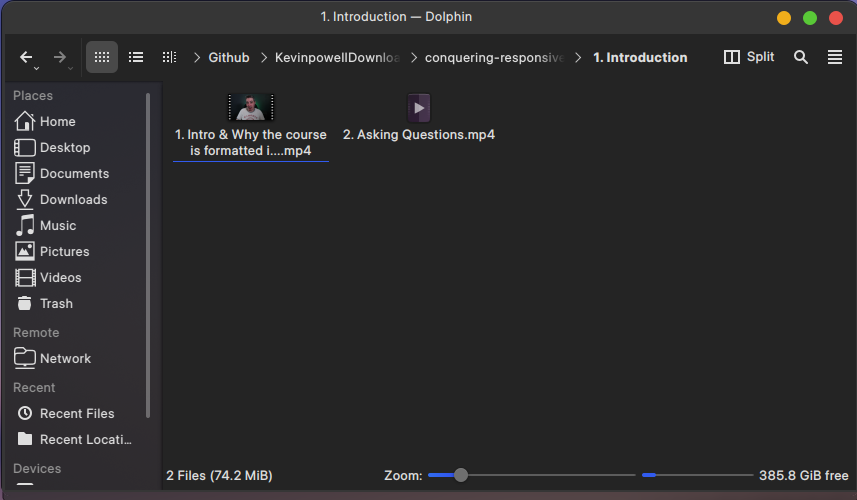
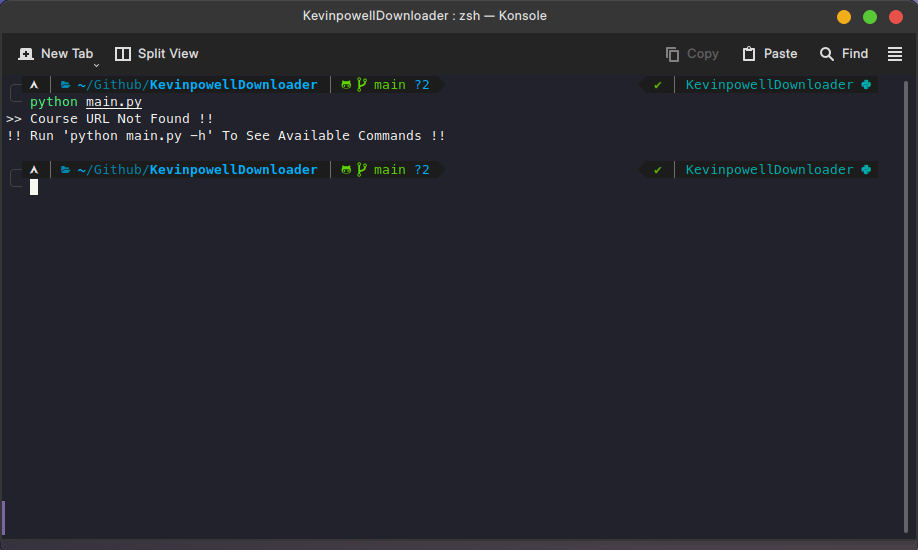
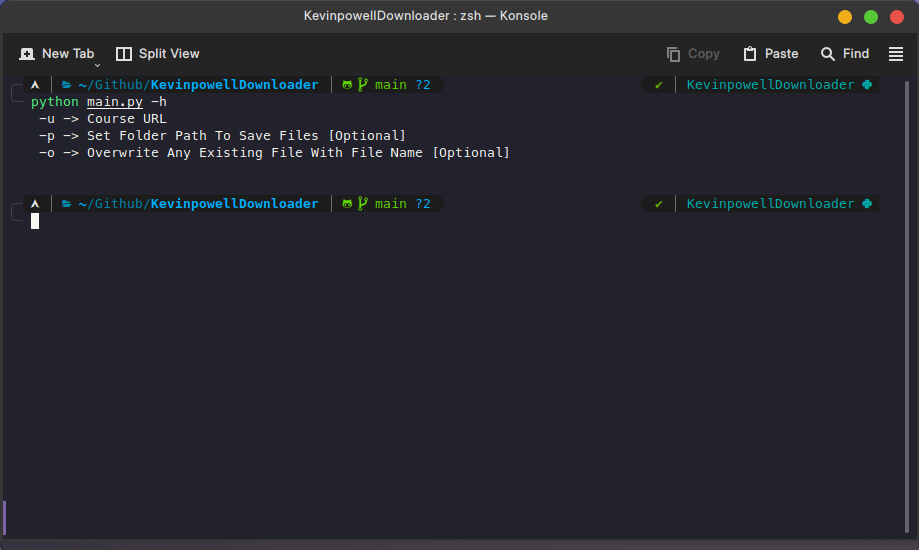
Github URL Of The Project : https://github.com/DeepProgram/KevinpowellDownloader
Subscribe to my newsletter
Read articles from Deep Sarker directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Deep Sarker
Deep Sarker
Passionate Python Backend Engineer with over 2 years of experience in backend development. I help companies optimize their web applications for superior performance and scalability, enabling them to achieve measurable results.