Introduction to Substreams (blockchain data transformation layer)
 Md Amaan
Md Amaan
We are gonna learn more about substreams and substreams integrated subgraphs and it's other plus points over ordinary subgraph in indexing blockchain data
Table of content
What is Substream ?
Why is it relevant and its Pros over subgraph.
How does it work internally ?
Bursting some common myths about Substream and Subgraph.
Conclusion
Some resources to Learn more :)
What is Substreams ?
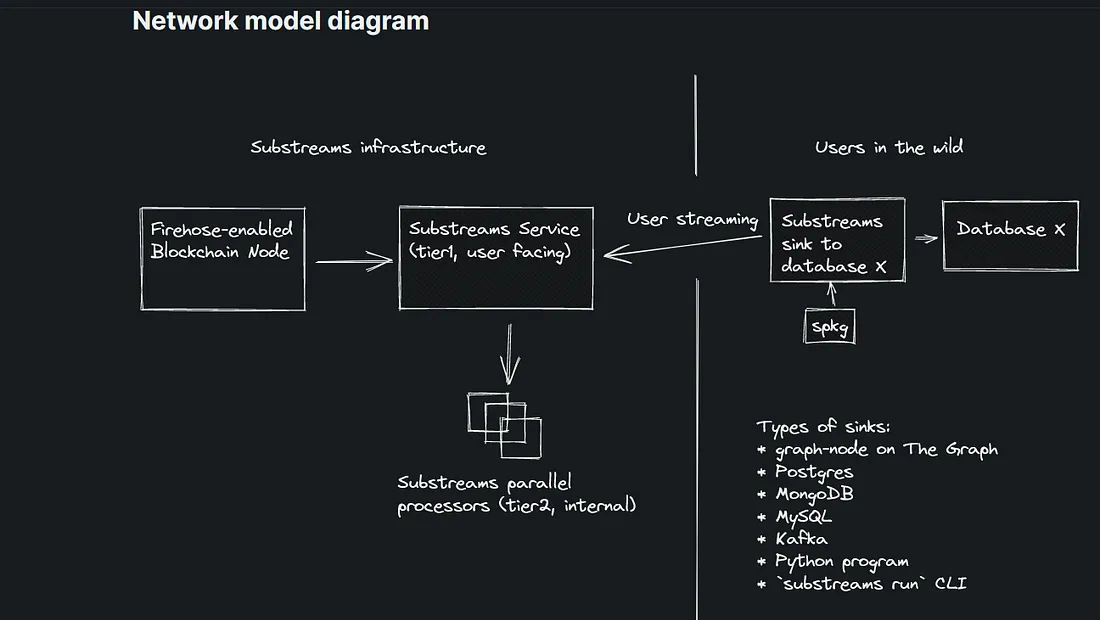
So you must be confused seeing the above diagram but let me demystify it and as always make it super juicy to digest.
let's dive in 🌊, Please be attentive from now because this is soul of this blog .
Basically when people build their application or rather decentrailised applications such as DEX or Nft marketplace,Trading app,etc.
All the transactions are done on the blockchain via smart contract so good this far but the issue is when a user does a transaction on your app its your responsibility to provide the details of that transaction on front end for better UX as well as a sense of transparency and trust.
To relate with me when you use Google pay you pay someone some money and then immediately a success comes and your balance from bank account is also deducted and the other person bank account balance also incremented and he or she can see it by checking the balance of their account within a matter of seconds and without any delay whatsoever but the issue here is to get data from blockchain can transform it into some meaningful manner and display it to your user it can take a lot of time .
As well as a lot of complexities because before substreams and firehose we used to do reading blockchain data or sending transactions to the network via JSON-RPC API and using geth Node in Ethereum and get data extracted and transported from network.
And all of this took a huge amount of time due to its linearly streaming of data from blockchain node this is the pain point that streaming fast team recognized and moved forward to solve, and they made firehose which does the extraction of data as fast as light as said Alexandre Bourget “Nothing can be faster than immediately” which is what there USP is to bring blockchain data to the client as fast as possible to do further work on that data.
It's trying to make querying as fast as google does for us no matter how old something is if it is on internet we will get that data in a matter of seconds and the above diagram is explanation of that you will understand it better later in this blog for now .
Prerequisites before moving further
What is ETL Pipeline ?
ETL stands for Extract,Transform and Load which means before even starting to work on data coming from other sources you need to Extract raw data from there and Transform it compatible to your database and Load it to your database such as Postgres,MongoDb etc.
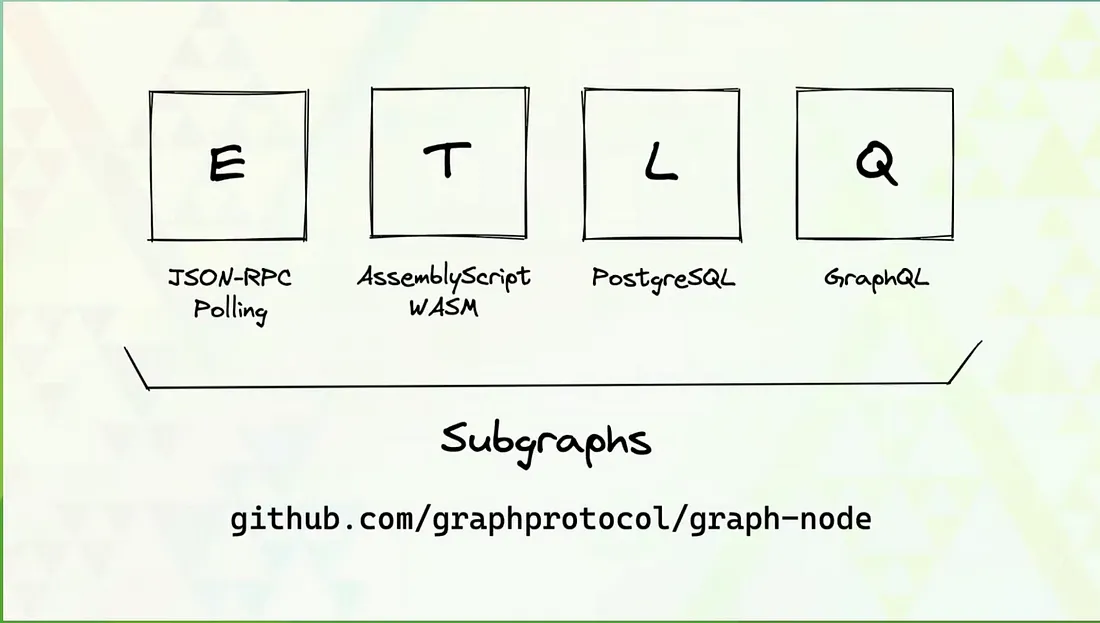
Now that you know a little about ETL Pipeline you must have got a hint that same thing most Dapps have to do with blockchain data extract data from blockchain Node and then transform it and sink it to corresponding database.
In this blog will focus on its one use case that is getting Data from blockchain to a subgraph for Indexing.
Why was Substream invented ?
Before knowing what substreams do and its inner functioning, let's discuss why it was invented and we needed it instead of standard subgraph development.
- Did you know Subgraphs had a linear indexing model using Wasm modules for processing blockchain data (i.e. they process events one at a time, in order), They used to do so via polling API calls to Ethereum clients ?

Well API calls takes a lot of time to push the data to the subgraph as it is doing it linearly, but Firehose comes into the picture 😎 and replaced it with its faster speed of syncing and indexing data into subgraph using its push model but still this alone was not enough until StreamingFast created a prototype called Sparkle, which helped decrease sync time on that subgraph from weeks to around six hours. Now, StreamingFast has evolved Sparkle’s capabilities and created substreams that can scale across all subgraphs on all chains, which is a huge achievement in itself for the team.
The Graph Foundation Awards $60 Million Grant to StreamingFast to Join The Graph as a Core Developer Team
Now the question is what does it do and why it matters so much to subgraph developers

Well it makes life of a subgraph developer really simple and seamless by syncing latest block when ever user interacts with the smart contract and its update need to immediately displayed on the front end for better UX which is why it’s needs to be super quick and scalable.
Substreams uses Firehose (developed by streaming fast) to extract data and also does parallel data streaming with firehose, which makes it horizontally scalable i.e. we can increase its efficiency with increase in machine power and no of firehoses running parallelly for storing and loading data making its indexing performance go as high as needed sky is the limit.
Now Subgraph have to use ETL data pipelining (Extract Transform and load) on blockchain data and index it to the consumer.
Which is why they need a better and faster ETL and now they are leveraging the power of substreams to do the task for them.
Its logs-based architecture through Firehose allows developers to send custom code for streaming and ad hoc querying of the available data.
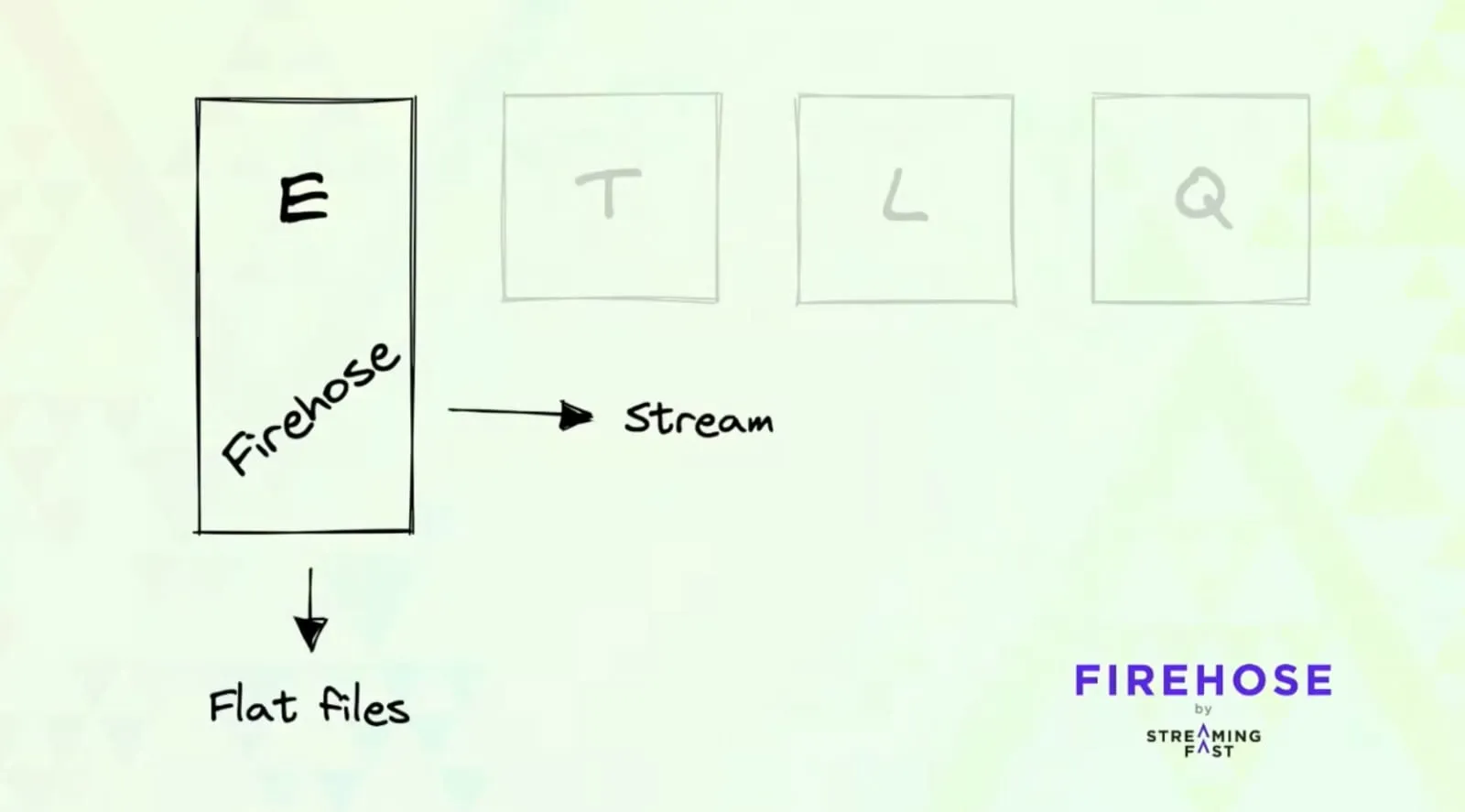
With Substreams, the data pipeline can be broken down into four stages:
Extract (via Firehose)
Transform (via Substreams and Subgraphs)
Load (to the Postgres database)
Query (serving queries to users)
Databases and flat files are standard storage types, however you can pipe Substreams data into other locations required by a new or existing application or architecture.

The sink reads the specific protobuf-based data being sent out of Substreams and performs the processing for it. Every sink performs differently regarding the data received, most perform some kind of storage.
Protobufs are designed to use for transferring data out of Substreams into the data sink. Protobufs aren’t tied to any particular technology stack or language, enabling you to capture, further process, use and store data provided by Substreams in different capacities.
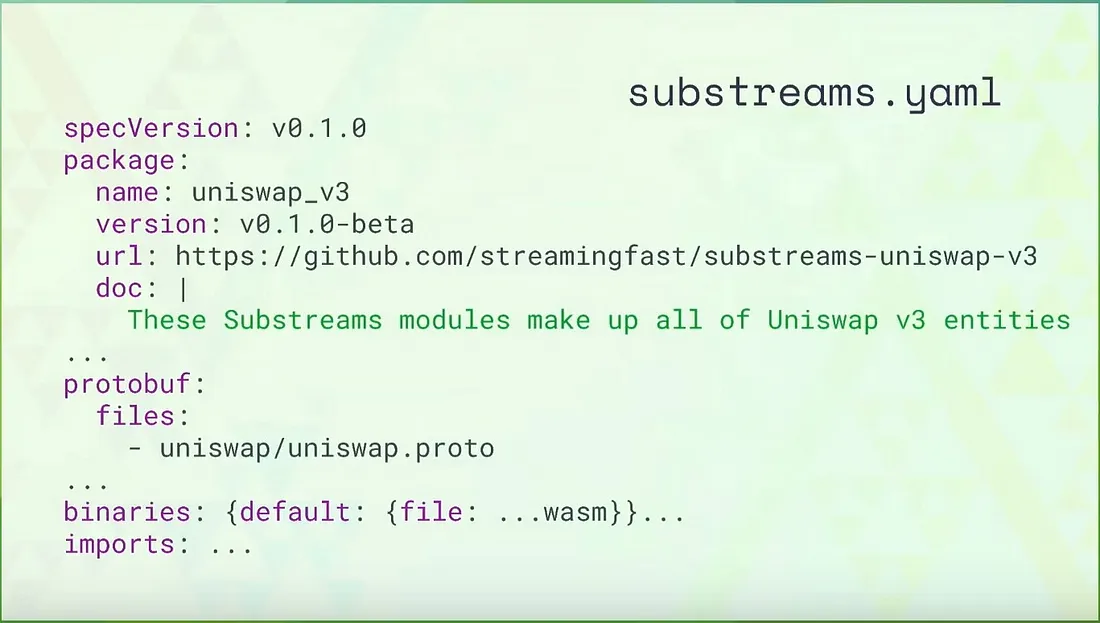
Existing modules can be leveraged, which developers can adapt, allowing end users to take advantage of composability without paying a performance penalty for indexing.
As you can see, above diagram imports … you can import any existing package out there or customize the whole file or mix of both.
Developers can iterate upon existing modules, reuse the most efficient processes without needing to rebuild a new subgraph.
High indexing Power
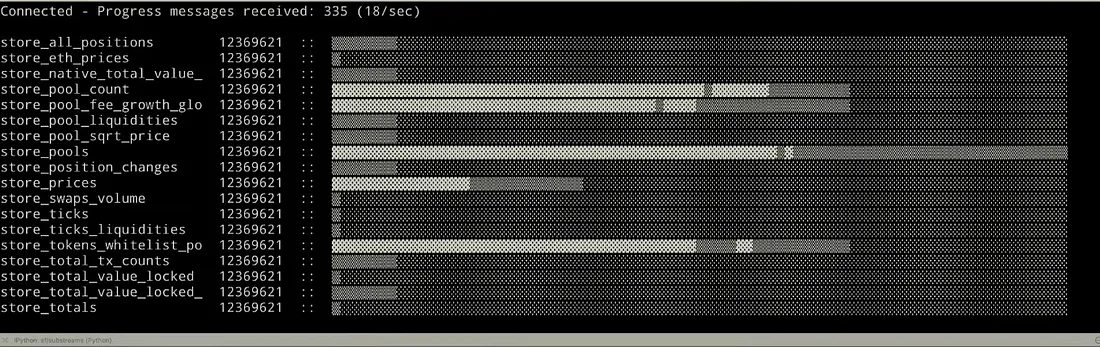
Orders of magnitude faster indexing through large-scale cluster of parallel operations (think BigQuery)
Customizable
Use code to customize extraction, do transformation-time aggregations, and model your output for multiple sinks.
Sink anywhere

You can sync data from Substreams to anywhere you want: PostgreSQL, MongoDB, Kafka, Subgraphs, flat files, or even Google Sheets. And do later mining over that and get analytics of the data and other tasks.
Programmable

You can sync data from Substreams to anywhere you want: PostgreSQL, MongoDB, Kafka, Subgraphs, flat files, or even Google Sheets. And do later mining over that and get analytics of the data and other tasks.
How does it work internally ?
The process to use Substreams includes choosing a blockchain to capture and process data from identifying interesting smart contract addresses (like DEXs or interesting wallet addresses).
Identify the data and defining and creating protobufs.
Find already-built Substreams modules and consume their streams
Write Rust Substreams module handler functions.
Update the Substreams manifest to reference the protobufs and module handlers.
Use the
substreamsCLI to send commands and view results from substreams.
Different parts of Substream architecture
1. The Substreams engine
2. Substreams module communication
3. Substreams DAG
4. Protobufs for Substreams
5. Substreams Rust modules
Myths about Substreams and Subgraphs
Subgraph and Substreams are same !
— > One cannot take a Subgraph’s code and run it on Substreams engine, they are incompatible. You write your Substreams in Rust while Subgraph are written in Assembly Script.
Other differences between Substreams and Subgraphs
Substreams are “stateless” request through gRPC while Subgraphs are persistent deployment
Substreams offers you the chain’s specific full block while in Subgraph, you define “triggers” that will invoke your code.
Substreams are consumed through a gRPC connection where you control the actual output message, while Subgraphs are consumed through GraphQL.
Substreams have no long-term storage nor database (it has transient storage) while Subgraph stores data persistently in Postgres.
Substreams can be consumed in real-time with a fork aware model, while Subgraph can only be consumed through GraphQL and polling for “real-time”.
Substreams offer quite a different model when compared to Subgraph, just Rust alone is a big shift for someone used to write Subgraphs in Assembly Script. Substreams is working a lot also with Protobuf models also.
One of the benefits of Substreams is that the persistent storage solution is not part of the technology directly, so you are free to use the database of your choice which enable a lot of analytics use cases that were not possible (or harder to implement) today using Subgraphs like persistent your transformed data to BigQuery or Clickhouse, Kafka, etc. Also, the live-streaming feature of Substreams enables further use cases and super quick reactivity that will benefit a lot of user.
Conclusion
Substreams are basically making our process of transformation of raw data into flat files or some other forms really fast and act as a caching memory for querying seamlessly from the blockchain node with its awesome paralllel streaming of data through firehose and then composable and programmable modules and packages makes it super customizable and fetch deterministic data into your app database making it cheaper and reliable for you and better UX for the customer or the consumer.
Use Cases of Substreams
It mainly focuses on blockchains Like Ethereum, Solana, Flow, Polkadot, Cosmos, Polygon, Binance Smart Chain, Optimism, Arbitrum, and other high throughput blockchains. The team is led by investors such as Multicoin Capital, Intel Capital, Diagram Ventures, White Star Capital, Panache Ventures, and BoxOne, with a growing community in Asia and North America.
Docs of StreamingFast for further deep dive go ahead.
My Socials :
Thnks for reading hope it was good learning experience for you :)
Follow for more ❣️😎
— — — — — — — — — — — — — — LinkedIn | Twitter — — — — — — — — — —
Subscribe to my newsletter
Read articles from Md Amaan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by