2.0 Exploring Essential Correlations for Data Scientists
 Pluviophile
Pluviophile
Correlations lie at the heart of data science, serving as crucial tools to uncover relationships between variables and unveil hidden insights within complex datasets. As a data scientist, understanding different types of correlations is essential for making informed decisions, building accurate models, and deriving meaningful insights. In this comprehensive guide, we will dive deep into the fundamental types of correlations every data scientist should master. We'll explore their assumptions, applications, advantages, limitations, and provide the mathematical foundations that underpin these correlation measures.
1. Pearson Correlation Coefficient (r):
Assumptions:
Linear relationship between variables.
Continuous variables.
Applications:
Economics: Analyzing the relationship between GDP and inflation.
Finance: Studying the correlation between stock prices.
Social Sciences: Examining the correlation between education and income.
Advantages:
Widely used for linear relationships.
Easy to interpret.
Limitations:
Sensitive to outliers.
Assumes normal distribution.
Formula:
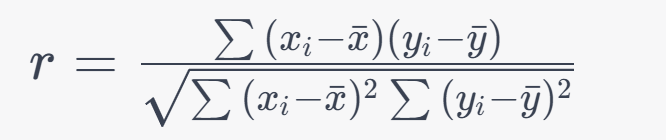
2. Spearman's Rank Correlation Coefficient (ρ or rs):
Assumptions:
Monotonic relationship between variables.
Ordinal variables.
Applications:
Psychology: Studying the correlation between survey ranks.
Biology: Analyzing the correlation between species diversity and altitude.
Advantages:
Captures monotonic relationships.
Robust to outliers.
Limitations:
- Ignores the magnitude of differences.
Formula:
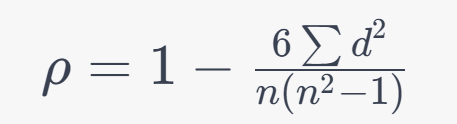
3. Kendall's Tau (τ):
Assumptions:
Monotonic relationship between variables.
Ordinal variables.
Applications:
Ecology: Analyzing the correlation between plant species abundance and altitude.
Genetics: Studying the correlation between genetic markers.
Advantages:
Focuses on ranking agreement.
Suitable for small sample sizes.
Limitations:
- Does not consider the magnitude of differences.
Formula:
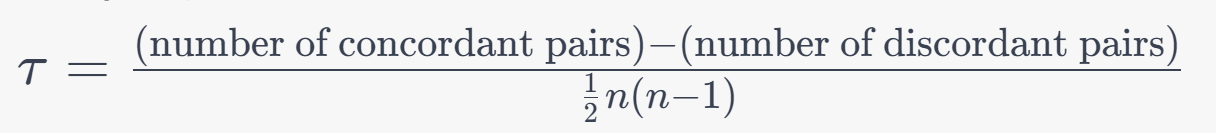
4. Point-Biserial Correlation Coefficient (rpb):
Assumptions:
Linear relationship between a binary variable and a continuous variable.
Binary and continuous variables.
Applications:
Medicine: Analyzing the correlation between a drug's efficacy and gender.
Social Sciences: Studying the correlation between income and education levels.
Advantages:
Suitable for binary and continuous variables.
Measures effect size.
Limitations:
- Assumes a normal distribution.
Formula:
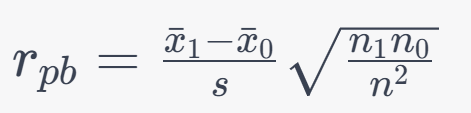
5. Cramer's V:
Assumptions:
Association between categorical variables.
Categorical variables.
Applications:
Marketing: Analyzing the relationship between customer preferences and product categories.
Social Sciences: Studying the correlation between political affiliation and voting patterns.
Advantages:
Accounts for the number of categories.
Suitable for large contingency tables.
Limitations:
Applicable only for categorical variables.
Doesn't measure strength for small samples.
Formula:
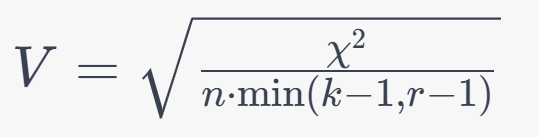
6. Phi Coefficient (φ):
Assumptions:
Association between binary variables.
Binary variables.
Applications:
Medical Research: Studying the correlation between a medical treatment and recovery.
Psychology: Analyzing the relationship between gender and a psychological trait.
Advantages:
Suitable for binary variables.
Measures strength and direction of association.
Limitations:
Limited to binary variables.
Sensitivity to cell size.
Formula:
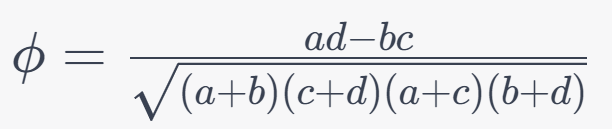
7. Biserial and Polyserial Correlation Coefficients:
Assumptions:
Linear relationship between a binary variable and a continuous/ordinal variable.
Binary and continuous/ordinal variables.
Applications:
Education: Analyzing the correlation between study hours and exam scores.
Sociology: Studying the relationship between income and social class.
Advantages:
Bridge gap between binary and continuous/ordinal variables.
Measure effect size.
Limitations:
- Assumes normal distribution.
Formulas:
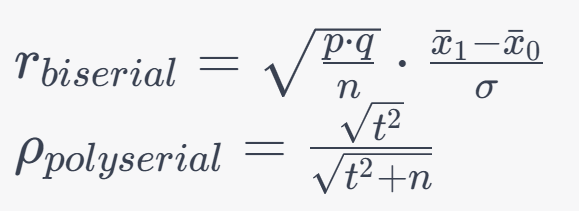
8. Eta (η):
Assumptions:
Association between nominal variables.
Nominal variables.
Applications:
Market Research: Analyzing the relationship between customer demographics and product preferences.
Demographics: Studying the correlation between ethnicity and language spoken.
Advantages:
Measures strength of association.
Suitable for nominal variables.
Limitations:
Limited to nominal variables.
Sensitivity to sample size.
Formula:
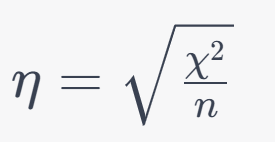
9. Partial Correlation Coefficient:
Assumptions:
Linear relationship between variables.
Controlling for additional variables.
Applications:
Epidemiology: Analyzing the correlation between diet and disease, controlling for age and gender.
Social Sciences: Studying the relationship between income and education, controlling for socioeconomic status.
Advantages:
Removes confounding variables.
Focuses on core relationship.
Limitations:
Requires knowledge of potential confounders.
Assumes linear relationships.
Formula:
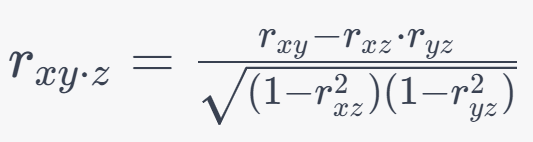
10. Intraclass Correlation Coefficient (ICC):
Assumptions:
Reliability analysis between raters/measurements.
Continuous variables.
Applications:
Medical Studies: Analyzing the reliability of different doctors' diagnoses.
Psychology: Studying the agreement between different raters' evaluations.
Advantages:
Measures interrater reliability.
Useful in test-retest studies.
Limitations:
Assumes homogeneity of variance.
Affected by sample size.
Formula:
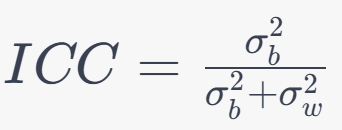
11. Distance Correlation:
Assumptions:
Dependence between variables in higher dimensions.
Multivariate continuous variables.
Applications:
Bioinformatics: Analyzing relationships between genes in gene expression data.
Pattern Recognition: Studying dependencies between features in image recognition.
Advantages:
Detects both linear and nonlinear relationships.
Does not rely on parametric assumptions.
Limitations:
Computationally intensive.
Requires larger sample sizes.
Formula:
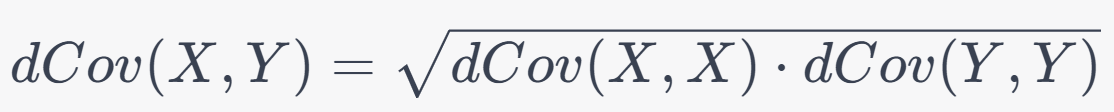
By mastering these essential correlation techniques, data scientists gain the ability to uncover insights, validate hypotheses, and make data-driven decisions across a wide range of disciplines. Understanding the assumptions, applications, advantages, and limitations of each correlation empowers data scientists to navigate complex datasets and derive meaningful insights with confidence.
Subscribe to my newsletter
Read articles from Pluviophile directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Pluviophile
Pluviophile
A Mechanical Engineer, with acquired skills(in Python, Machine Learning & Data Science), an insatiable intellectual curiosity, and the ability to leverage a heavy dose of Mathematics and Applied Statistics with visualization and a healthy sense of exploration. Passionate about Machine Learning with a problem-solving attitude and keen to develop deeper expertise and gain exposure in the ML, DL and NLP space.