Redis Cluster - Part 2
 Nitin Kalra
Nitin Kalra
Sharding is a database design technique used to horizontally partition a large dataset across multiple smaller databases or nodes, with each node handling a portion of the data.
In a sharded architecture, the data is divided into smaller subsets called shards. Each shard is a self-contained unit that holds a portion of the overall data.
Now let's consider two Redis shards, each containing half of your data. If we divide and distribute our data across two shards, which are just two Redis server instances, how will we know where to look for each key?
We need to have a way to consistently map a key to a specific shard. There are multiple ways to do this and different databases adopt different strategies. The one Redis chose is called “Algorithmic sharding”.
In order to find the shard on which a key lives we compute a numeric hash value out of the key name and modulo divide it by the total number of shards.
If we increase or decrease the number of shards, it creates an issue, as keys will now be mapped to a different shard.
Redis chose a very simple approach to solving this problem: it introduced a new, logical unit that sits between a key and a shard, called a hash slot.
One shard can contain many hash slots, and a hash slot contains many keys.
The total number of hash slots in a database is always 16384 (16K). This time, the modulo division is not done with the number of shards anymore, but instead with the number of hash slots, which stays the same even when resharding and the end result will give us the position of the hash slot where the key we’re looking for is present.
And when we do need to reshard, we simply move hash slots from one shard to another, distributing the data as required across the different redis instances.
Does it sound similar to consistent hashing? We have a ring that has values from 0 to 16384, and nodes takes some portion of these keys.
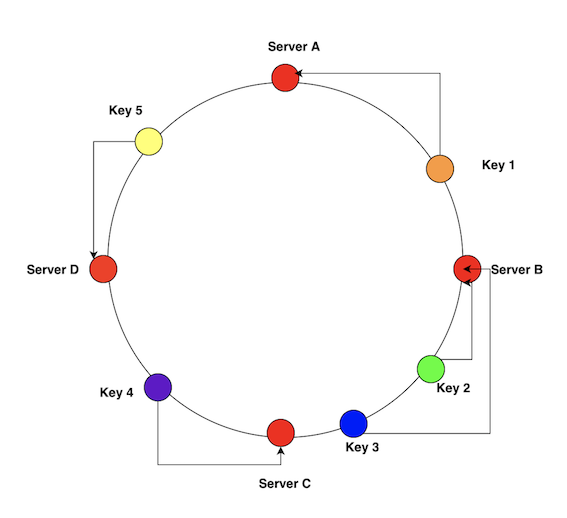
To check the hash slot of a key, Redis has a command
CLUSTER KEYSLOT
CLUSTER KEYSLOT key
Returns an integer identifying the hash slot the specified key hashes to. This command is mainly useful for debugging and testing, since it exposes via an API the underlying Redis implementation of the hashing algorithm.
We can use this command in order to check what is the hash slot, and then the associated Redis Cluster node, responsible for a given key.
CLUSTER KEYSLOT somekey
(integer) 11058
> CLUSTER KEYSLOT foo{hash_tag}
(integer) 2515
> CLUSTER KEYSLOT bar{hash_tag}
(integer) 2515
Redis Cluster can detect when a primary shard fails and promote a replica to a primary without any manual intervention from the outside. How does it do it? How does it know that a primary shard has failed, and how does it promote its replica to be the new primary shard? We need to have replication enabled. Say we have one replica for every primary shard. If all our data is divided between three Redis servers, we would need a six-member cluster, with three primary shards and three replicas.
All 6 shards are connected to each other over TCP and constantly PING each other and exchange messages using a binary protocol. These messages contain information about which shards have responded with a PONG, so are considered alive, and which haven’t.
You can connect to one of redis cluster node to get the info about the cluster and information about which slots are handled by which node
redis-cli -p 7000
127.0.0.1:7000>
127.0.0.1:7000> CLUSTER INFO
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:158484
cluster_stats_messages_pong_sent:160334
cluster_stats_messages_sent:318818
cluster_stats_messages_ping_received:160329
cluster_stats_messages_pong_received:158484
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:318818
redis-cli -c -p 7000
127.0.0.1:7000> CLUSTER SLOTS
1) 1) (integer) 5461
2) (integer) 10922
3) 1) "127.0.0.1"
2) (integer) 7001
3) "e5e03421ff2382913b128f2a285b6caa745fff25"
4) 1) "127.0.0.1"
2) (integer) 7003
3) "a3144bf0c4c005306d7ffa017de28ab0d012abd7"
2) 1) (integer) 10923
2) (integer) 16383
3) 1) "127.0.0.1"
2) (integer) 7002
3) "bb80cff60c3a96e62ef973ac21b17346abe9fc67"
4) 1) "127.0.0.1"
2) (integer) 7004
3) "affd20157282bfa2f4c92b194972f73897e75c5d"
3) 1) (integer) 0
2) (integer) 5460
3) 1) "127.0.0.1"
2) (integer) 7000
3) "08f787928fd72210e2ef6691f7bde65894c363f4"
4) 1) "127.0.0.1"
2) (integer) 7005
3) "c8618e728cfe6121b52421a2d56d86ce44dd339f"
In the above output, we can see from slots 0 to 5460 is handled by node running at port 7000 and there is a replica of this node running at 7005 port
Slot 5461 - 10922 is handled by 7001 and replica node is 7003
Slot 10923 - 16383 is handled by 7002 and replica node is 7004
Some references:
Redis cluster specification | Redis
Redis Cluster: Architecture, Replication, Sharding and Failover
If you liked this blog, you can follow me on twitter, and learn something new with me.
Subscribe to my newsletter
Read articles from Nitin Kalra directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Nitin Kalra
Nitin Kalra
Working as a Principal Software Engineer. I have experience working on Java, Spring Boot, Go, Android Framework, OS, Shell scripting, and AWS. Experienced in creating scalable and highly available systems.