Building a Full Stack AI-Powered News Aggregator with Grafbase, NestJS, and Next.js
 Tim Lavreniuk
Tim Lavreniuk
I am thrilled to participate in a hackathon on Hashnode, where I will develop an innovative AI-powered news aggregator using Grafbase. This user-friendly platform will allow users to conveniently read news articles and watch videos, accompanied by concise summaries for a quick overview. The web app will feature a secure authentication system and a GraphQL API, ensuring an efficient and enjoyable user experience.

If you don't feel like reading the whole article, no worries! You can check out this project here:
https://grafbasenewsaggregator.vercel.app/
Why GraphQL?
GraphQL is an ideal choice for building my app because it provides a flexible and efficient method for requesting data from the server. It enables users to request only the needed data, minimizing over-fetching and optimizing performance. Moreover, GraphQL's built-in type system guarantees end-to-end type safety, making the development process more dependable and efficient.
Previously, I worked with GraphQL in various ways, such as manual API creation and automatic schema-based API generation using Amplify. Now, it's time to explore another method for creating a GraphQL API.
Why Grafbase?
I'm excited to try a graph database! After browsing the website, Graphbase appears to be a close sibling of Supabase but with a graph database. It's also fascinating to explore another GraphQL API connection feature. I can't wait to give it a try!
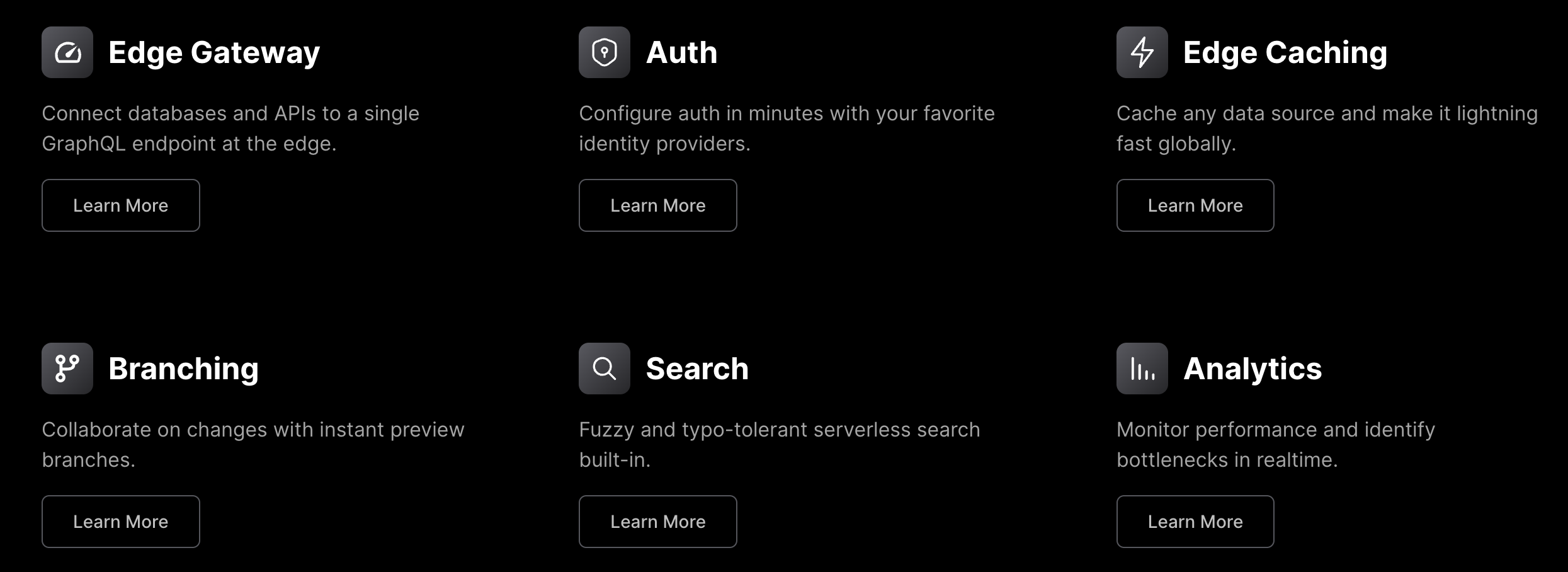
Grafbase provides a straightforward yet adaptable and scalable database that can be constructed using schemas and managed via an intuitive user interface.
It automatically generates queries for fetching data by ID, unique value, or collection, along with all essential mutations for creating, updating, deleting, linking, and unlinking data.
Alright, let's dive in and create a project! First, we need to establish a project and configure the database settings.
Project creation and setup
After registration, I tried to create a new project. It's very cool that Grafbase provides the option to create a new project from a template.
But before I connect this project with my GitHub repo,
Great! Since I want to create a news aggregator, I chose a similar template - HackerNews. Now, I need to click the deploy button.
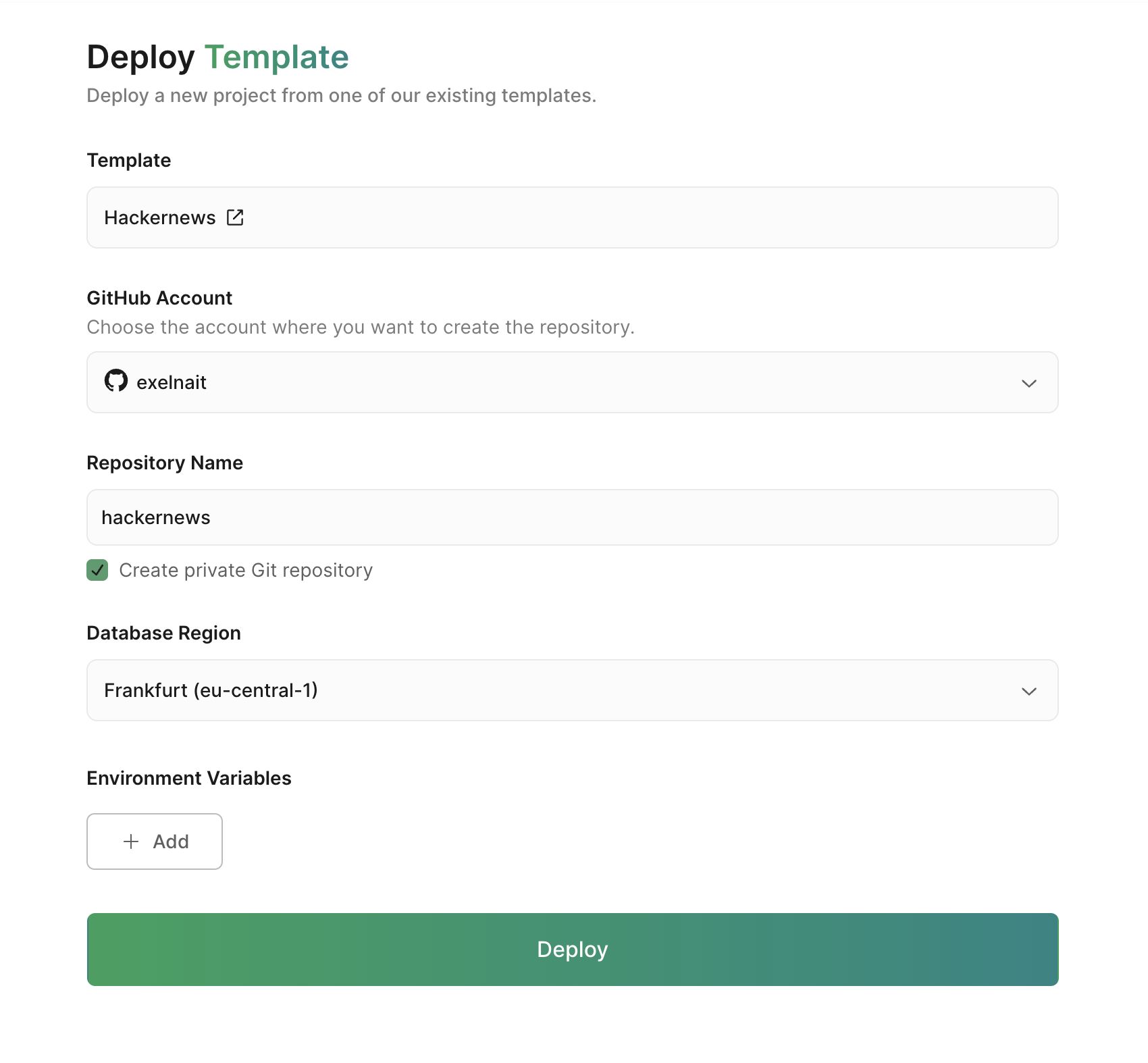
Grafbase will create this project from an existing template in my GitHub repo and deploy it. I'm excited to see how this project functions behind the scenes - awesome!
After this, I decided to create a new project from scratch using the command line:
npx grafbase init grafbasenewsaggregator
After that, it will prompt me to select the desired configuration format:

I chose TypeScript because it offers type safety out of the box and provides better readability.
Grafbase also supports configuring a project using the GraphQL Schema Definition Language with custom directives. All I need to do is create the file grafbase/schema.graphql instead of grafbase/grafbase.config.ts.
Database schema design
The schema file outlines the structure of your data, relationships, and settings for validation and authentication using the GraphQL schema definition language.
Working with grafbase.config.ts
In my news aggregator, the first step for a user is to add a Topic. Each topic will include publishers and news connections, working like a folder.
const topic = g.model('Topic', {
title: g.string(),
creator: g.string().search(),
publishers: g
.relation(() => publisher)
.list()
.optional(),
news: g
.relation(() => newsItem)
.list()
.optional(),
});
Publishers should also have relationships with news and sources.
const publisher = g.model('Publisher', {
title: g.string(),
creator: g.string(),
topic: g.relation(() => topic),
avatar: g.relation(() => picture).optional(),
news: g
.relation(() => newsItem)
.list()
.optional(),
sources: g.relation(() => publisherSource).list(),
});
const publisherSource = g
.model('PublisherSource', {
title: g.string(),
isHidden: g.boolean().default(false),
type: g.enumRef(sourceType),
creator: g.string(),
topic: g.relation(() => topic),
publisher: g.relation(() => publisher),
rss: g.ref(publisherSourceRSS).optional(),
youtube: g.ref(publisherSourceYouTube).optional(),
})
.search();
I love this method of creating relations - it's so simple and intuitive!
When working with the PublisherSearch model, I use the .search() method. The cool thing is that Grafbase indexes the data in its database for this model and even generates a search-based query for us. Cool 😎
Since Grafbase currently doesn't support Union type, I need to create a field for each source type: RSS and YouTube.
const publisherSourceRSS = g.type('PublisherSourceRSS', {
url: g.string(),
});
const publisherSourceYouTube = g.type('PublisherSourceYouTube', {
username: g.string().optional(),
channelID: g.string().optional(),
});
Now, I need to create the primary model type - NewsItem.
const newsItem = g
.model('NewsItem', {
type: g.enumRef(sourceType),
title: g.string().search(),
creator: g.string().search(),
description: g.string().optional(),
publishedAt: g.string(),
cover: g.relation(() => picture).optional(),
publisher: g.relation(() => publisher).optional(),
topic: g.relation(() => topic).optional(),
rss: g.ref(newsItemDataRSS).optional(),
youtube: g.ref(newsItemDataYouTube).optional(),
})
.search();
Grafbase will also index it. Additionally, there are numerous relations and enums. Creating an enum is quite simple:
const sourceType = g.enum('SourceType', ['rss', 'youtube']);
And the final element - Picture. NewsItem will have a cover while Publisher will have an avatar.
const picture = g.model('Picture', {
bucket: g.string(),
key: g.string(),
url: g
.url()
.optional()
.resolver('picture/url')
.cache({ maxAge: 60, staleWhileRevalidate: 60 }),
});
And this is where I used a resolver for the first time. Now it's time to delve deeper into resolvers.
Creating resolvers
Resolvers make the whole GraphQL API from Grafbase better, and they do their thing in separate V8 zones, I guess. But, like, there's no info on how it all works behind the scenes 🤷♂️.
They can be incorporated to expand database models with field resolvers or to extend the schema with query and mutation resolvers.
For the Picture model, I created a field resolver. This is because, before creating a picture, I need to upload it to an S3 Bucket and save its key and bucket. With the resolver, I devised a small function to provide a URL for the image through my CDN using this key and bucket.
It's great that there's a guide on creating a field resolver and connecting it to the database.
export default function Resolver(root: Partial<Picture>, args, context) {
return getResizedPictureUrl(root.bucket, root.key);
}
function getResizedPictureUrl(
bucket: string,
key: string,
width?: number,
height?: number
): string {
if (bucket == '' && key == '') {
return null;
}
const params: Record<string, any> = {
bucket,
key,
};
if (width && height) {
params.edits = {
resize: {
width,
height,
fit: 'cover',
},
};
}
const encodedParams = btoa(JSON.stringify(params));
return `${process.env.CDN_URL}/${encodedParams}`;
}
It's super cool that I can pick between JavaScript and TypeScript for resolvers! Naturally, I went with TypeScript. 😊
By the way, I received a personal email informing me about a few errors in this resolver. How considerate! 🤗
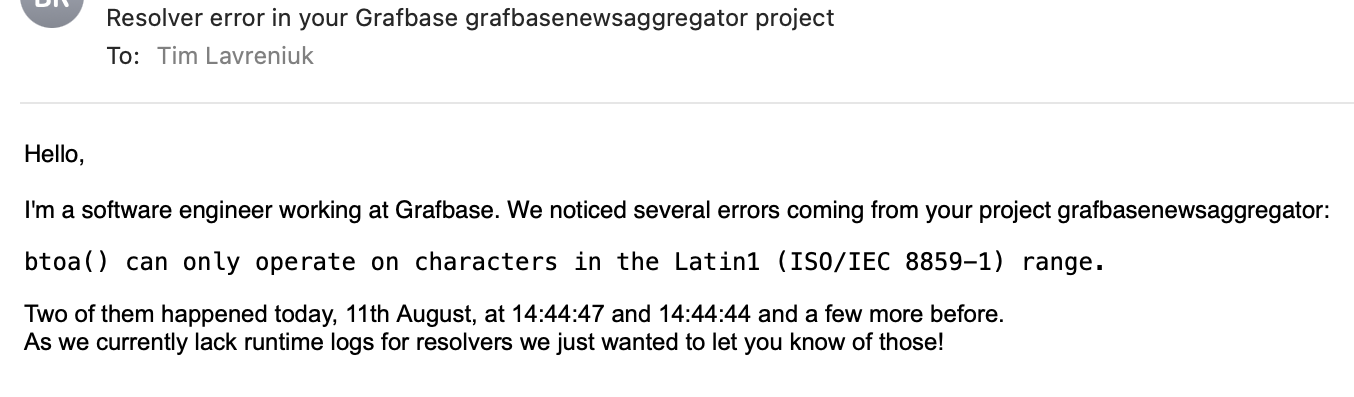
Exciting moment - I can use third-party packages, but no file exists. Grafbase will install these packages after the grafbase dev command is launched. However, sometimes it becomes laggy, and I must remove the node_modules folder and relaunch the dev server.
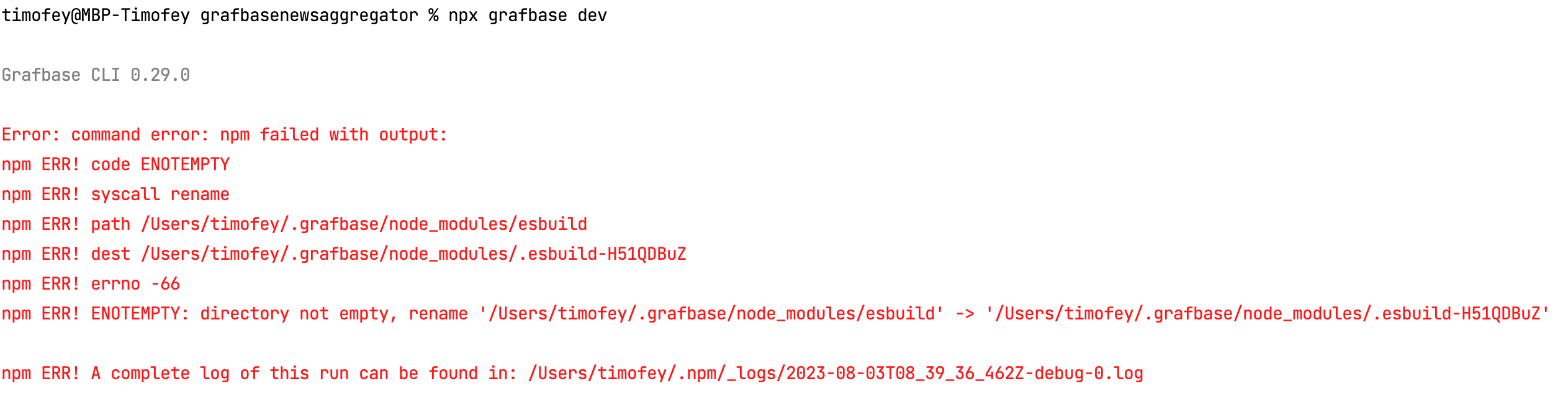
After discovering this, I realized creating a resolver for both Queries and Mutations would be great. This is because, to create a publisher, I need to make third-party fetch requests, upload pictures to an S3 Bucket, and construct a significant GraphQL mutation for my API. However, this approach isn't ideal in this particular case. Why?
Grafbase doesn't run this in the NodeJS engine but more like Cloudflare Workers. Their docs don't mention how resolvers work behind the scenes 🥲. But hey, at least the errors give some hints 😁:
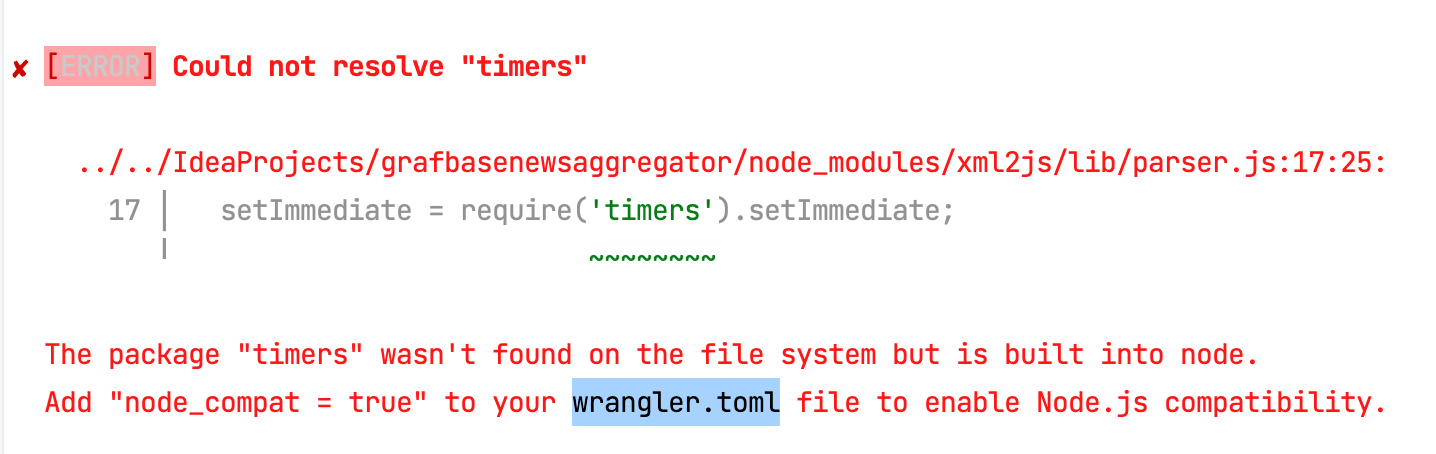
So, I need to use some packages that depend on the NodeJS API, native modules, etc., but that's not my situation. In conclusion, a resolver is a simple, lightweight function containing some business logic.
But how can I resolve this issue? How can I create complex business logic? I made a custom GraphQL API and merged it with Graphbase API.
Custom GraphQL API Integration
The Graphbase Edge Gateway enables you to consolidate data at the edge by seamlessly integrating GraphQL and non-GraphQL services.
I can combine existing APIs to extend remote types. Fortunately, Graphbase provides a guide on how to accomplish this.
For my API, I chose the NestJS framework. It provides an easy way to create a GraphQL API. NestJS offers two methods for building GraphQL applications: code-first and schema-first. I should choose the one that works best for me. I opted for the code-first approach. So, first, I created a mutation for publisher creation.
@Resolver(() => Publisher)
export class PublisherResolver {
constructor(
private readonly publisherService: PublisherService,
private readonly aggregationService: AggregationService,
private readonly newsService: NewsService
) {}
@Mutation(() => Publisher)
async createPublisher(
@Args('input') input: CreatePublisherInput
): Promise<Publisher> {
// Create sources
// Upload avatar
// Create a publisher in grafbase
// Aggregate all news from sources
}
})
From this annotation, NestJS will generate a mutation. It's a standalone Node.js application so I can use any Node.js module. Cool.
Also, I need to describe the input type model:
import { InputType, Field, ID } from '@nestjs/graphql';
@InputType()
class CreatePublisherSourceRSSInput {
@Field()
url: string;
}
@InputType()
class CreatePublisherSourceYoutubeInput {
@Field({ nullable: true })
username?: string;
@Field({ nullable: true })
channelID?: string;
@Field({ nullable: true })
url?: string;
}
@InputType()
class CreatePublisherSourceTwitterInput {
@Field()
username: string;
}
@InputType()
class CreatePublisherSourceCustomInput {
@Field((type) => String)
type: 'rss' | 'youtube';
@Field((type) => CreatePublisherSourceRSSInput, { nullable: true })
rss?: CreatePublisherSourceRSSInput;
@Field((type) => CreatePublisherSourceYoutubeInput, { nullable: true })
youtube?: CreatePublisherSourceYoutubeInput;
@Field((type) => CreatePublisherSourceRSSInput, { nullable: true })
itunes?: CreatePublisherSourceRSSInput;
}
@InputType()
export class CreatePublisherInput {
@Field()
title: string;
@Field({ nullable: true })
avatarUrl?: string;
@Field((type) => ID)
topicID: string;
@Field()
creatorID: string;
@Field({ nullable: true })
websiteUrl?: string;
@Field((type) => [CreatePublisherSourceCustomInput])
sources: CreatePublisherSourceCustomInput[];
}
The strangest thing about this is how I made a Grafbase API request from my API. Because there is no SDK to call GraphQL API mutations directly, I had to create a regular fetch request with a plain text GraphQL mutation inside. There's a lot of peculiar code, and it isn't easy to debug, but it works. 🙃
async createNewsItems(input: NewsItemCreateInput[]): Promise<NewsItem[]> {
const data = await fetch(process.env.API_URL, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-key': process.env.GRAFBASE_API_KEY,
},
body: JSON.stringify({
operationName: 'CreateNewsItem',
query: `
mutation CreateNewsItem($input: [NewsItemCreateManyInput!]!) {
newsItemCreateMany(input: $input) {
newsItemCollection {
id
}
}
}
`,
variables: {
input: input.map((item) => ({
input: item,
})),
},
}),
});
const response = await data.json();
if (response.errors?.length > 0) {
throw new Error(response.errors[0].message);
}
const news: NewsItem[] =
response.data.newsItemCreateMany.newsItemCollection;
return news;
}
Alright, the API is ready and deployed to AWS. Now, I need to connect it to the Graphbase configuration. First, I'll place my custom API URL inside the environment variables. After that, all I need to do is create a connector.
const graphqlAPI = connector.GraphQL({
url: g.env('GRAPHQL_API_URL'),
});
g.datasource(graphqlAPI, { namespace: 'custom' });
Now, I can call my mutation from the Graphbase API endpoint 🎉.
Caching
I just wanted to mention that Graphbase provides a caching feature for the database API and connected APIs.
Edge caching is a performance optimization strategy implemented in your GraphQL API to cache responses near the end users. This technique significantly cuts down overall latency, enhancing data delivery speed.
It's crucial for GraphQL APIs, particularly when creating your API. Now, I can effortlessly set up entities with a field cache.
Since my news aggregator is AI-based, caching third-party API responses is essential for an improved user experience and cost optimization.
const newsItemDataRSS = g.type('NewsItemDataRSS', {
url: g.string(),
categories: g.string().list().optional(),
author: g.string().optional(),
// Will available after normalization
contentHtml: g.string().optional().cache({ maxAge: 30, staleWhileRevalidate: 60 }),
contentJson: g.string().optional(),
coverUrl: g.string().optional(),
// Will available after summarization
summary: g
.string()
.optional()
.cache({ maxAge: 60, staleWhileRevalidate: 60 }),
});
Making API requests
To make an API request to Graphbase, I can use a playground. Locally or after deployment, I can open a Graphbase API playground and perform some queries or mutations. Sadly, there is no access to the database. Because I need to work a lot with data locally, especially removing corrupted data entities.
I can open data.sqlite it inside the .graphbase folder. However, it is not the best development experience.
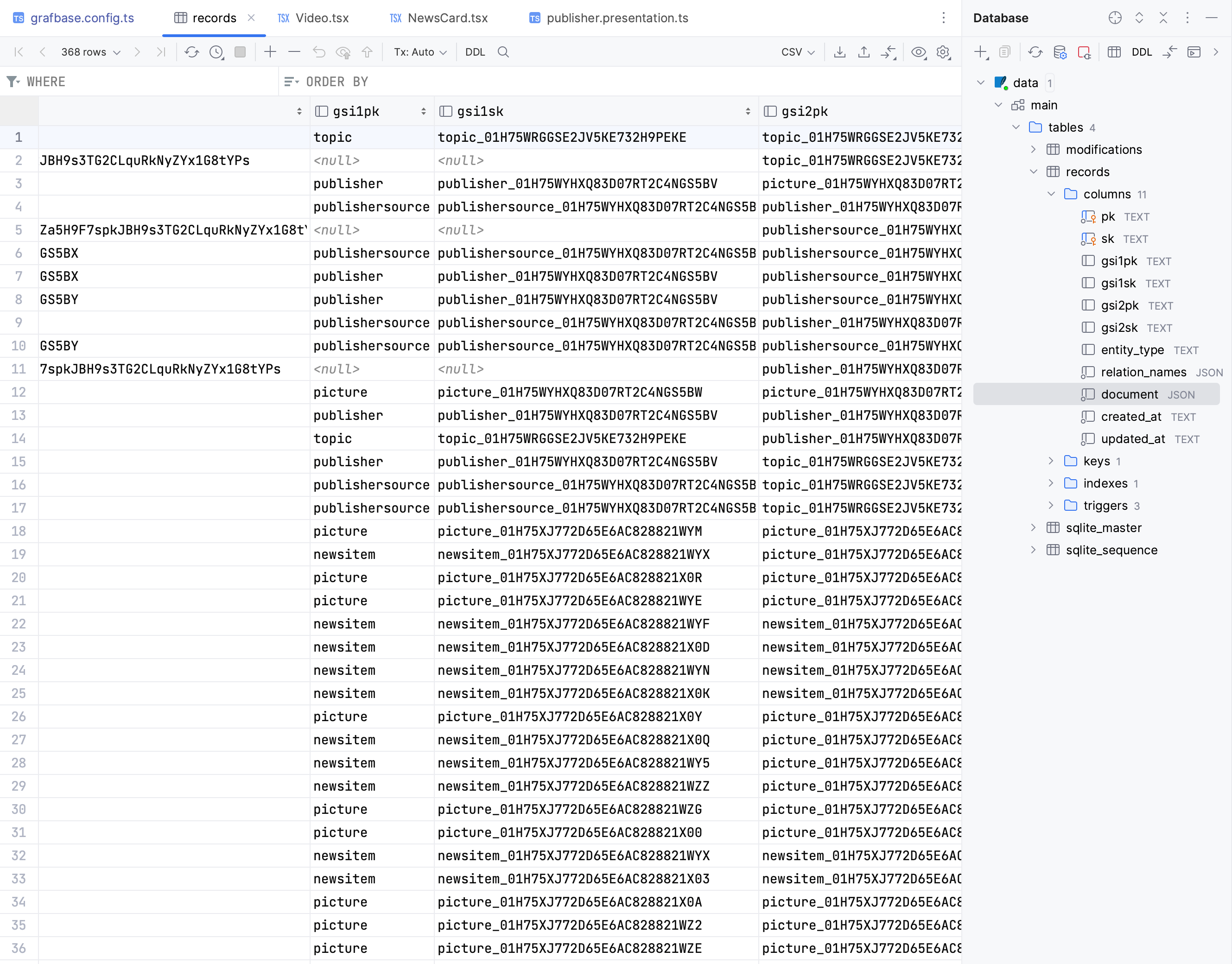
API Playground
The Playground UI appears straightforward. I can easily select queries, fields, and arguments.
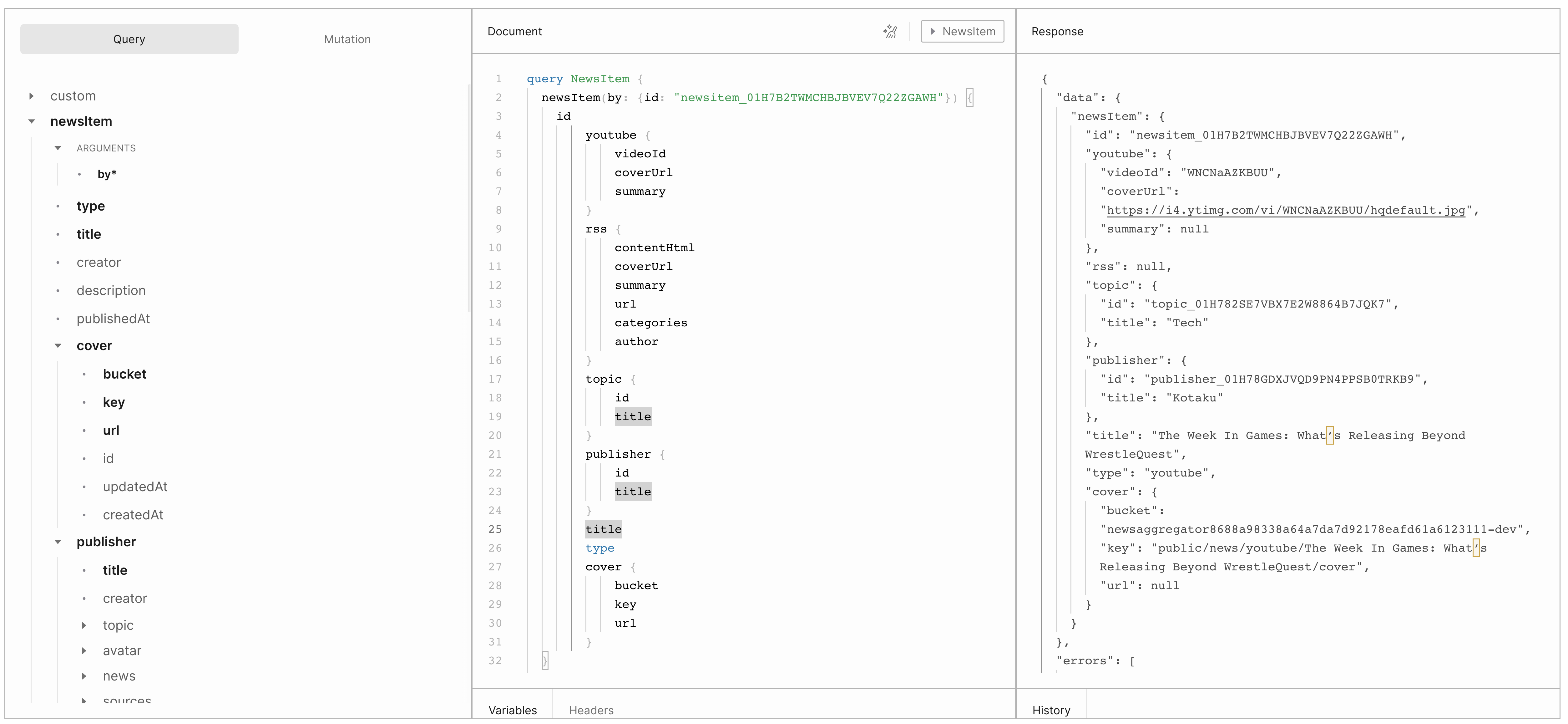
The only downside to this playground is the lack of hints for arguments in the left sidebar. Intellisense works but doesn't correctly indicate whether an array or an object should be used as input.
Authentication setup
Grafbase works seamlessly with popular authentication strategies, including OpenID Connect and JWT. I need to choose which auth service I want to use. I chose Clerk because Grafbase has two guides about it 🙃.

For me, authentication is the most mysterious part. On the one hand, it's easy to connect it, thanks to Grafbase tutorials.
const provider = auth.OpenIDConnect({
issuer: g.env('CLERK_ISSUER_URL'),
});
export default config({
schema: g,
auth: {
providers: [provider],
rules: (rules) => {
rules.private();
},
},
});
But what happens afterward? What occurs once a user signs up? There are so many unanswered questions.
I cannot utilize permissions in my app since specific data, such as news and publishers, are generated through my custom API (using an API key). Consequently, there is only one method for associating my authenticated user with Grafbase database entities: creating a userId string type field and simply inserting the ID obtained from Clerk.
Deploying grafbase
Before deploying the Grafbase API, I must connect the Grafbase configuration with my Grafbase account.
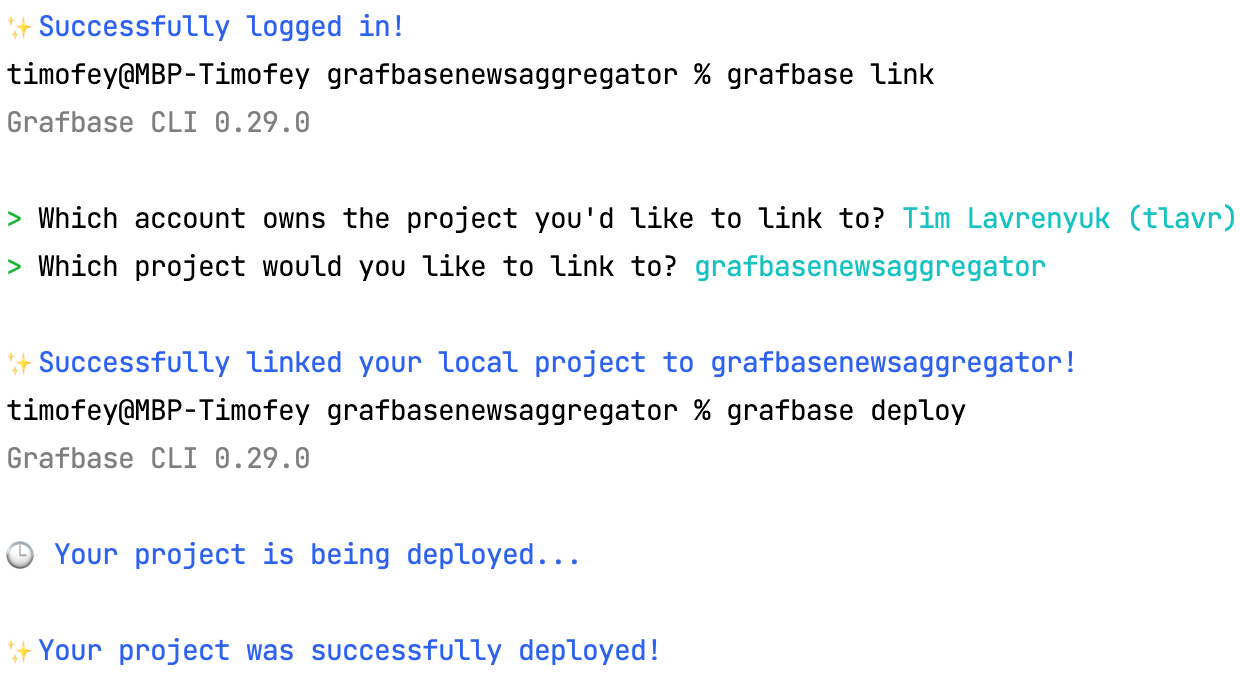
Afterward, I need to use the command grafbase deploy , and the project will be deployed. Alternatively, I can commit it and view all the changes I made to my API in the Grafbase UI.
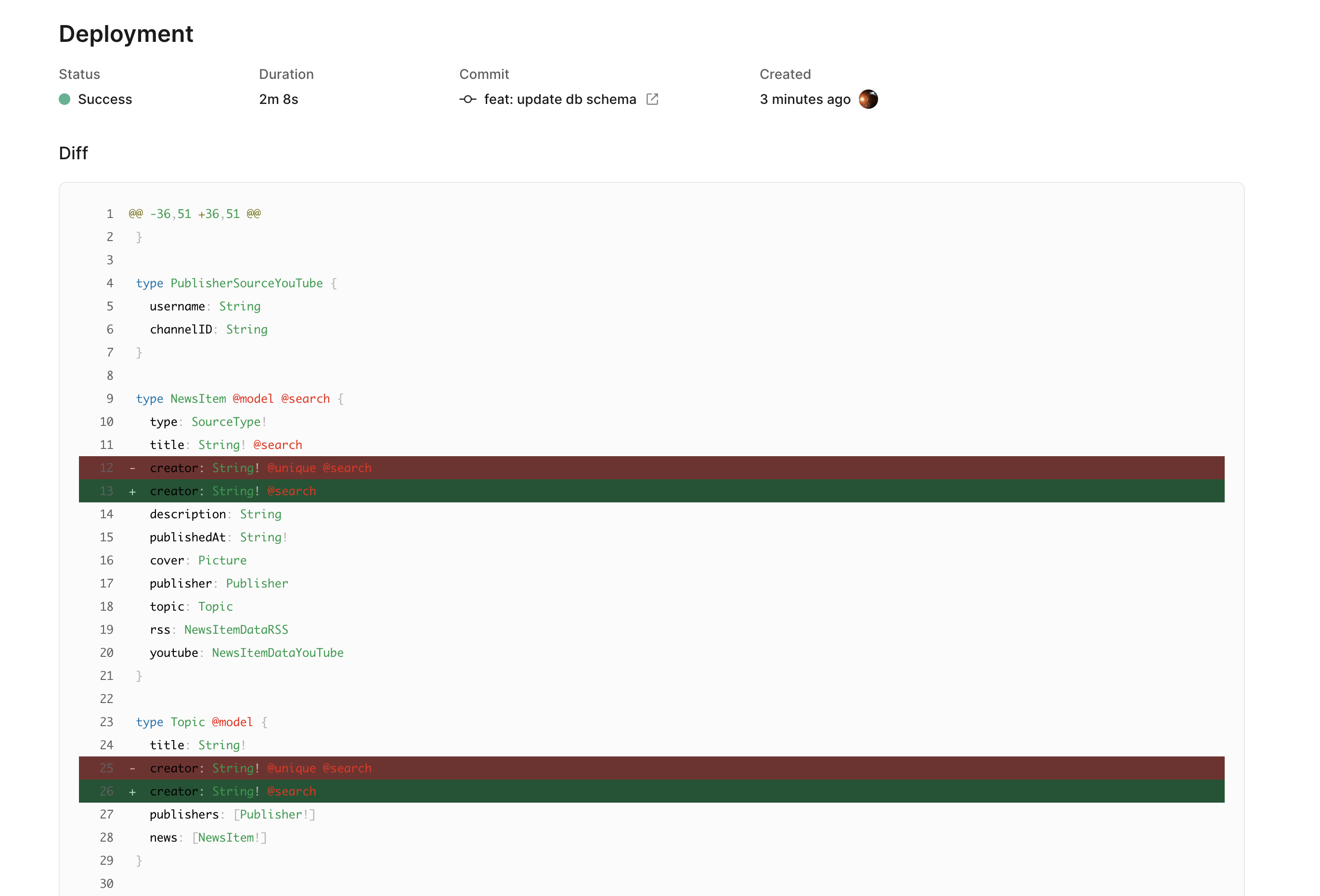
Usually, deploying takes 3-5 minutes.
Creating a Web App
After successfully deploying the Grafbase API and connecting the Grafbase configuration with my Grafbase account, the majority of the work for this project has been completed on the backend. It is time to shift our focus toward creating a user-friendly web application.
Choosing API client
Now it's time to create an app to harness the full power of my newly created API. Thankfully, Grafbase provides guides for each popular GraphQL client. I chose Apollo and followed the instructions provided in the guide.
Working with GraphQL schema
One of the most significant benefits of GraphQL is the built-in type system. These types can then be used when building your front end to ensure end-to-end type safety.
But how will Apollo know what TypeScript types my Grafbase API has? Instead of writing TypeScript types manually to match your Grafbase GraphQL API, we can use GraphQL Code Generator to generate everything we need automatically. Additionally, Grafbase provides another guide for this.
I set up a codegen configuration for both the front and back ends.
import { CodegenConfig } from '@graphql-codegen/cli';
import * as process from 'process';
const config: CodegenConfig = {
schema: {
[process.env.GRAFBASE_API_URL]: {
headers: {
'x-api-key': process.env.GRAFBASE_API_KEY,
},
},
},
generates: {
'./graphql/schema.graphql': {
plugins: ['schema-ast'],
},
'./packages/web-app/graphql/schema.ts': {
plugins: [
'typescript',
'typescript-operations',
'typescript-react-apollo',
],
config: {
withHooks: true,
},
},
'./graphql/generated/': {
preset: 'client',
plugins: [],
},
},
ignoreNoDocuments: true,
documents: [
'packages/web-app/data/**/*.graphql',
'packages/graphql-api/src/**/*.graphql',
],
};
export default config;
Now, I can use my GraphQL API schema type in my custom NestJS-based GraphQL API.
Making GraphQL API requests
First, I am requesting user topics along with their publishers to display them on the left sidebar. Here, I am utilizing a search request to find topics and publishers related to the user.
query ListUserPublishers($creatorID: String!) {
topicSearch(first: 10, filter: {creator: {eq: $creatorID}}) {
edges {
node {
...BaseTopic
publishers(first: 10) {
edges {
node {
...PublisherInfo
}
}
}
}
}
}
}
To create a topic or publisher, I use my own custom GraphQL API connected to Graphbase via an API connector.
mutation CreateTopic($input: TopicCreateInput!) {
topicCreate(input: $input) {
topic {
...BaseTopic
}
}
}
mutation CreatePublisher($input: CustomCreatePublisherInput!) {
custom {
createPublisher(input: $input) {
id
}
}
}
In parallel, I want to request a personalized user newsfeed. Grafbase is not the ideal choice, and in the future, I plan to implement it using a NoSQL database.
For publishers' newsfeeds, the Graph database works just fine! 😄
query GetNewsFeed($userId: String!) {
newsItemSearch(filter: {creator: {eq: $userId}, }first: 100) {
edges {
node {
...BaseNewsItem
}
}
}
}
query GetPublisherNewsFeed($id: ID!) {
publisher(by: {id: $id}) {
...PublisherInfo
news(first: 100) {
edges {
node {
...BaseNewsItem
}
}
}
}
}
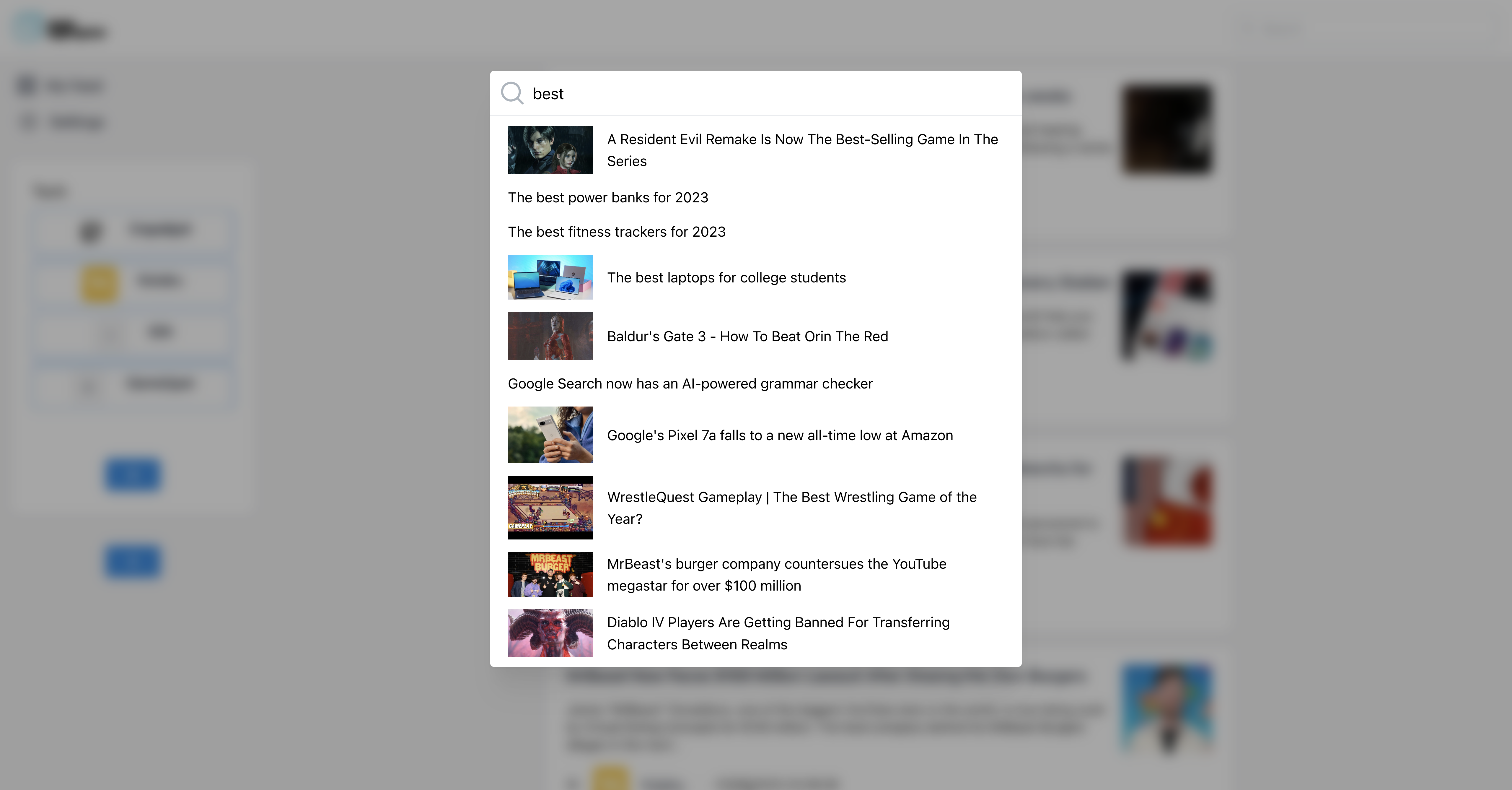
And what I adore - search. It works really well, even when users make a slight error in their search query. That's because Grafbase employs the Levenshtein distance to graciously accommodate typos of one character for words with a length of 4 or more. It even allows for typos of two characters in words with a length of 8 or more.
query SearchNews($userId: String!, $query: String!) {
newsItemSearch(query: $query, filter: {creator: {eq: $userId}}, first: 10) {
edges {
node {
...BaseNewsItem
}
}
}
}
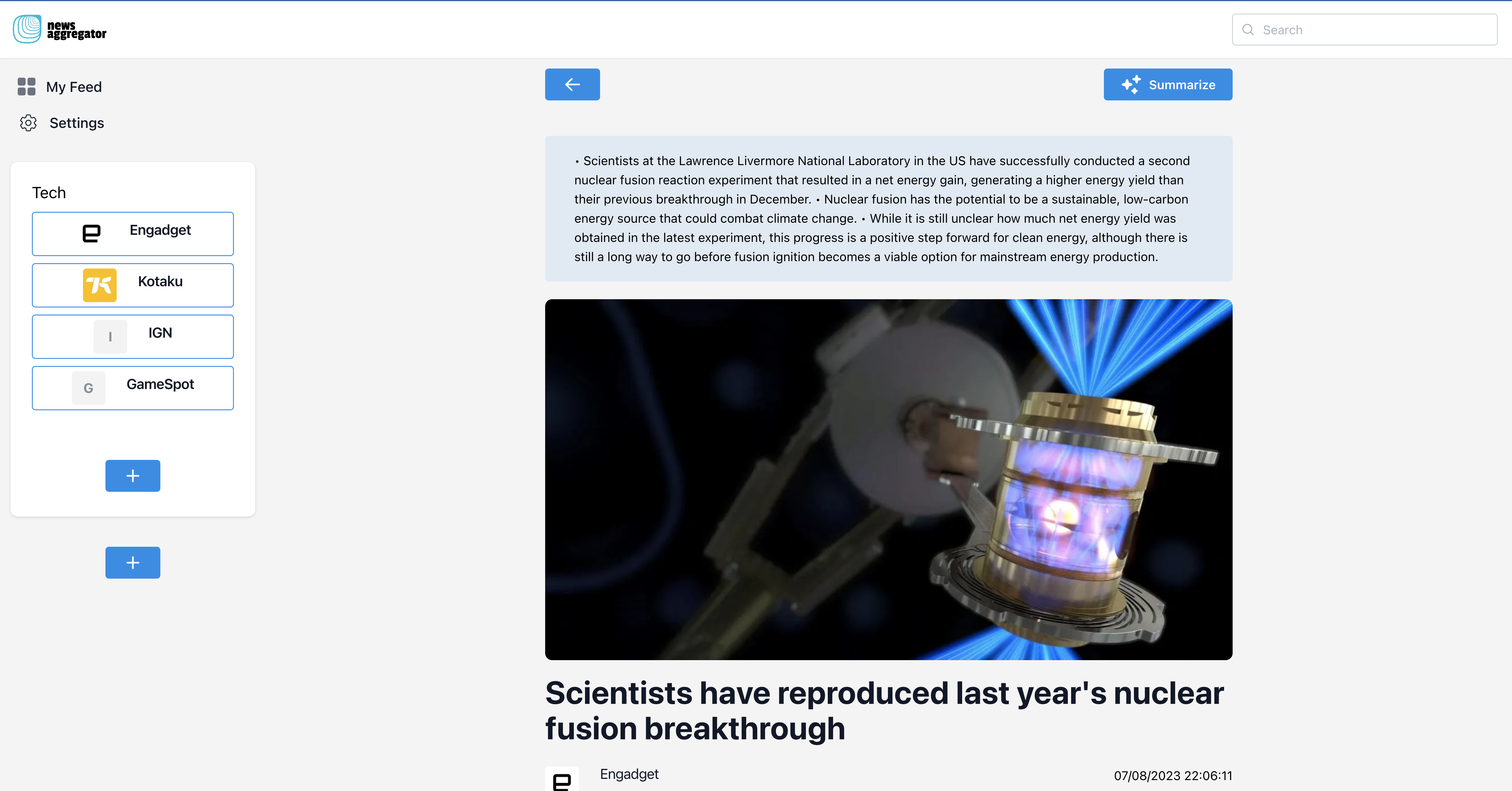
After opening a news article or video, I must request its full content, excluding AI-related information. However, when the user clicks the "Summarize" button, I want to request AI-related content from my custom API.
query GetNewsItem($id: ID!) {
newsItem(by: { id: $id }) {
...BaseNewsItem
}
}
query GetNewsItemWithSummary($id: String!) {
custom {
getNewsItem(id: $id) {
id
rss {
summary
contentHtml
}
youtube {
summary
}
}
}
}
Deploying web app
Upon completing the development of my web application, I proceeded to deploy it on the Vercel platform. With the deployment successfully executed, the project is now readily accessible and available for use by anyone interested in exploring its features and functionalities.
Final project structure
Alright, I've built the database, API, and web app. Let's take a look at how these projects are organized and how I made it easier to work with them.
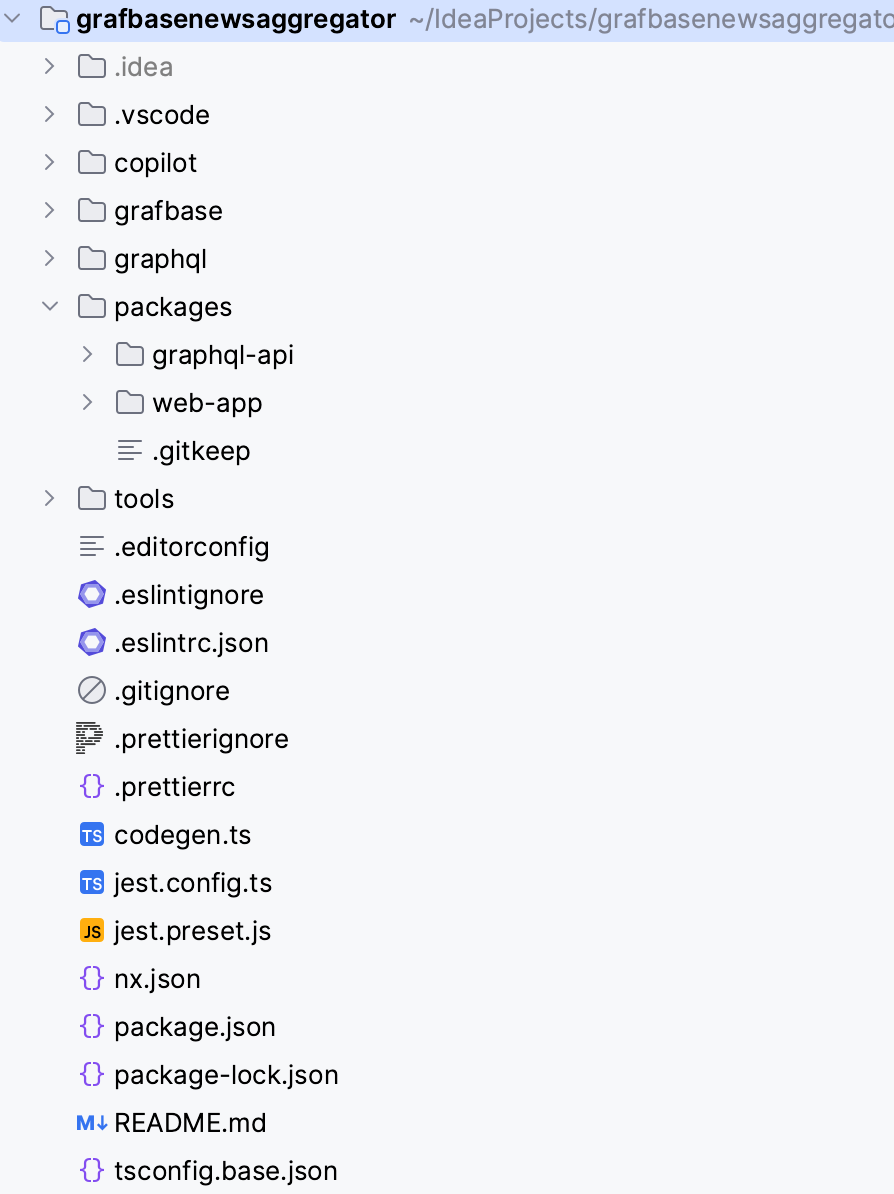
The Grafbase folder is in the root folder. It contains Grafbase configurations: db, auth, API connector, and resolvers.
The GraphQL folder contains GraphQL types for both the Grafbase API and my custom API. I used these types inside my custom API to work more easily with the Grafbase API. Additionally, in the web app, I used them to work with both the Grafbase API and my custom API connected to Grafbase.
I utilized the NX monorepo tool to manage application development. That's why the packages folder contains both the custom GraphQL API and the web app.
It's now time to celebrate the fruitful outcome of two weeks of dedicated effort and immense learning!
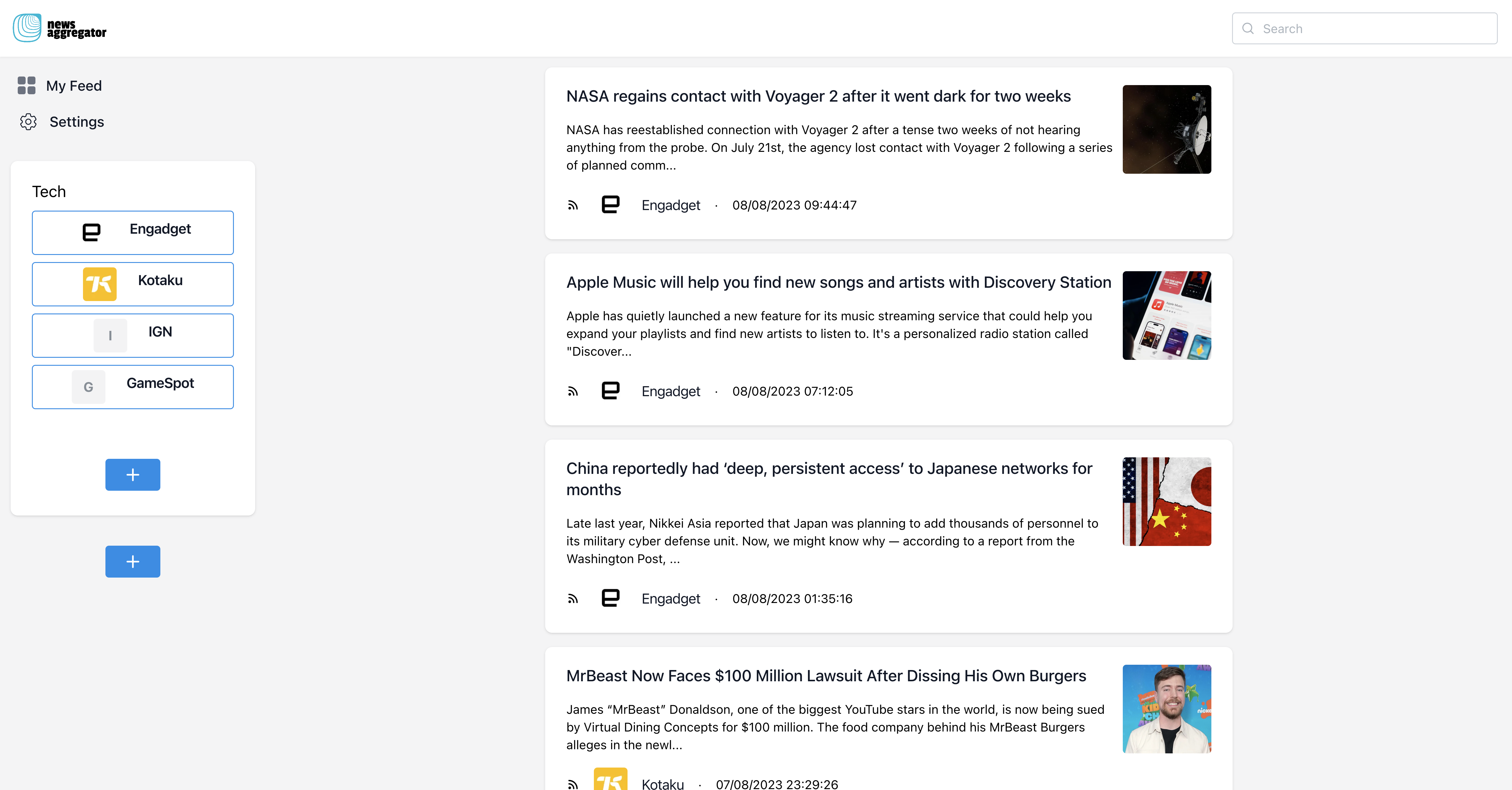
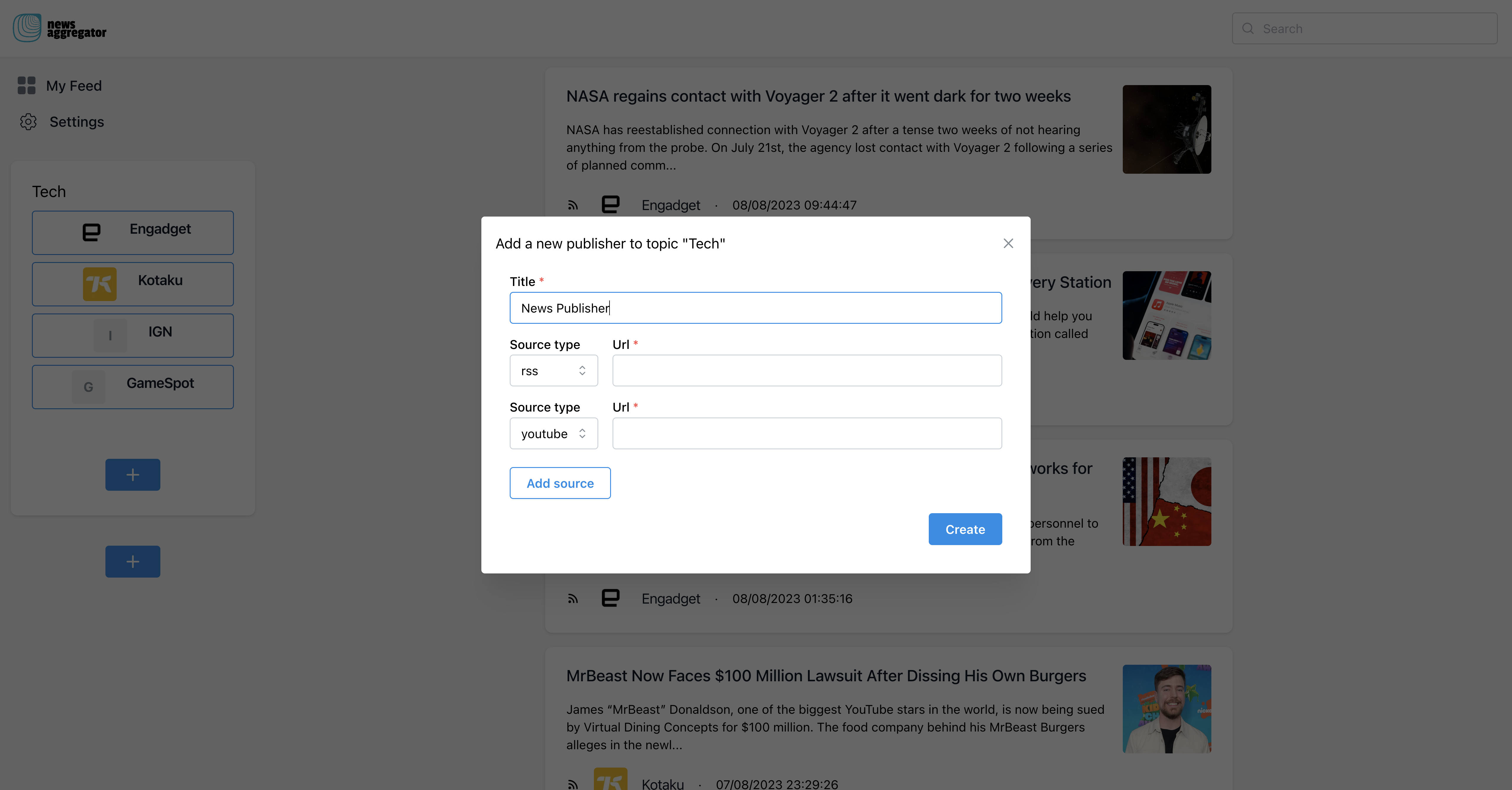
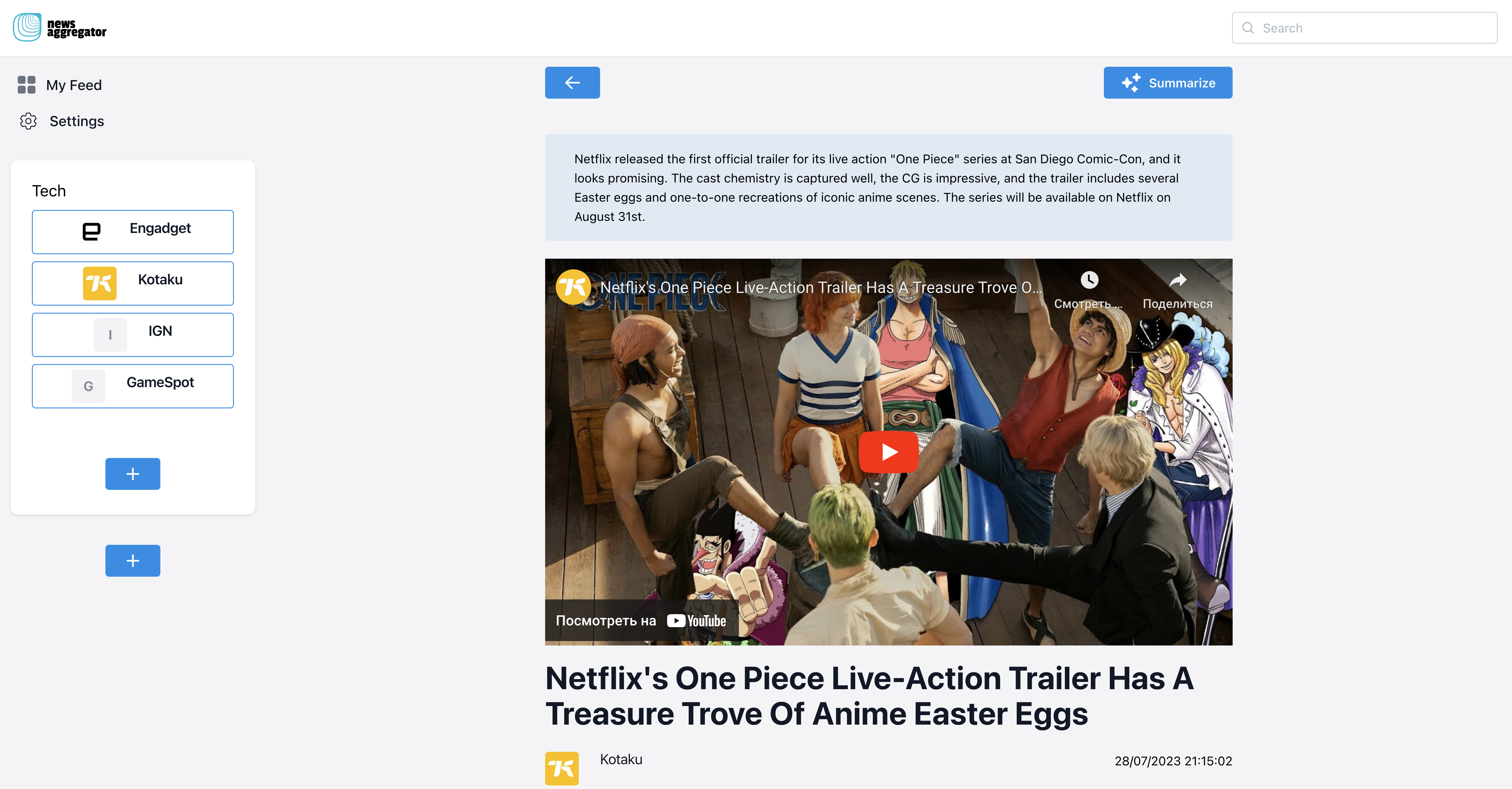
Final result
You can start using the news aggregator at this address: https://grafbasenewsaggregator.vercel.app/
Conclusion
Using Grafbase for this project during the hackathon proved to be a fantastic experience. The platform's intuitive interface and powerful features allow for the efficient development of an AI-powered news aggregator.
Exploring Graph Database with GraphQL API, custom resolvers, and connection to third-party GraphQL APIs provided a unique opportunity to delve into cutting-edge technologies and acquire new skills.
However, there were a few challenges and areas for improvement. Grafbase could benefit from better documentation, especially regarding resolvers and authentication. Addressing these issues would enhance the overall development experience and make the platform more powerful and user-friendly.
Despite these challenges, the overall experience with Grafbase during the hackathon was positive. The platform's capabilities and ease of use enabled rapid development and deployment of a feature-rich web application. With continued improvements and refinements, Grafbase has the potential to become an even more valuable tool for developers in the future.
Subscribe to my newsletter
Read articles from Tim Lavreniuk directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Tim Lavreniuk
Tim Lavreniuk
Full Stack Developer. AWS Certified Solutions Architect