Navigating the Depths of Splunk: From Introduction to Architecture
 Navya A
Navya A
Are you ready to unlock the potential of your data like never before? Dive into the world of Splunk, where data becomes a valuable asset for decision-making and insights. In this comprehensive blog post, we'll take you on a journey that encompasses both the fundamentals of Splunk and a detailed exploration of its architecture. By the end, you'll have a solid understanding of what Splunk is, why it's essential, how its components interact, and how to leverage its architecture to transform data into actionable intelligence.
What is Splunk?
At its core, Splunk is a robust and versatile platform designed to help organizations collect, index, search, and analyze vast amounts of data generated by machines, applications, and systems. Whether it's log files, sensor data, or metrics from IT infrastructure, Splunk provides a centralized platform to make sense of this data in real time.
![]()
Why Splunk?
Real-time Insights: Splunk enables real-time monitoring and analysis of data streams, allowing you to respond swiftly to emerging issues or trends.
Cross-Source Analysis: It can aggregate data from diverse sources, enabling you to correlate events and gain a comprehensive understanding of your environment.
Troubleshooting and Debugging: Troubleshoot problems faster by analyzing logs and identifying anomalies that might be causing issues.
Security and Compliance: Splunk can play a crucial role in monitoring security events, identifying threats, and ensuring compliance with industry standards.
Business Intelligence: Discover valuable insights hidden within your data to make informed business decisions.
Getting Started with Splunk:
Data Collection: Splunk ingests data through various sources, including log files, APIs, and direct inputs.
Indexing: Once collected, data is indexed, making it easily searchable and accessible.
Search and Analysis: Use the Splunk Search Processing Language (SPL) to query and analyze data. Build visualizations, dashboards, and reports to make data-driven decisions.
Apps and Add-ons: Extend Splunk's functionality by installing apps and add-ons from the Splunkbase marketplace.
Use Cases:
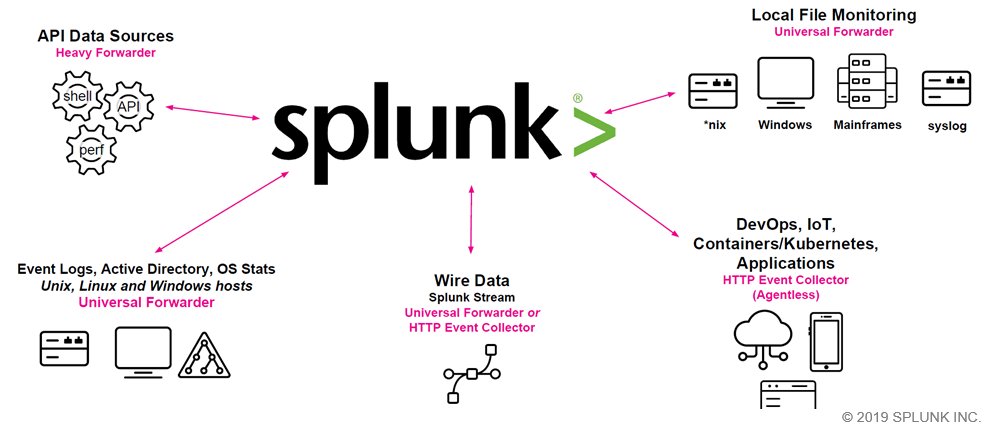
IT Operations: Monitor server performance, track application logs, and identify bottlenecks to ensure smooth operations.
Security: Detect and respond to security threats in real time, analyze historical data to uncover breaches, and maintain compliance.
Business Analytics: Gain insights into customer behavior, market trends, and operational efficiency by analyzing data across different business units.
Challenges and Considerations:
While Splunk offers numerous benefits, it's important to consider the challenges as well:
Data Volume: Managing and storing large volumes of data can be resource-intensive.
Cost: Splunk's licensing costs can escalate with increased data volume and user count.
Expertise: To fully leverage Splunk's capabilities, organizations need skilled personnel who can design effective searches and build insightful dashboards.
Splunk's architecture is the foundation upon which it transforms raw machine-generated data into actionable insights. Understanding this architecture is essential to harness the full potential of Splunk. In this blog post, we'll take a deep dive into Splunk's architecture, exploring its components and how they work together to deliver powerful data analysis and visualization capabilities.
Splunk Architecture:
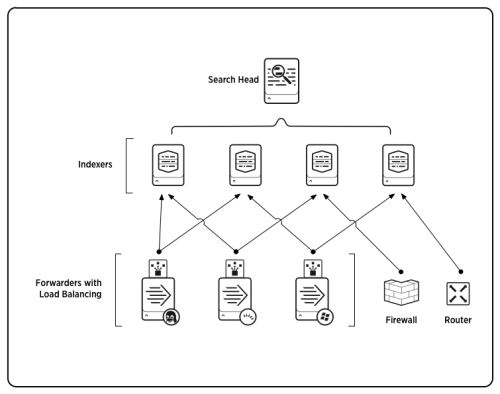
Components of Splunk Architecture:
Data Collection:
Forwarders: These lightweight agents are responsible for collecting data from various sources and forwarding it to the Splunk indexer. They can be installed on servers, endpoints, and devices to ensure data ingestion.
Universal Forwarders: These are optimized for collecting and forwarding data with minimal overhead, ideal for high-volume data sources.
Indexer:
Data Reception: The indexer receives incoming data from forwarders. It breaks down the data into events and assigns them timestamps and metadata.
Indexing and Storage: Data is then indexed and stored in compressed and optimized data structures, making it searchable and accessible.
Search Head Clusters: For high availability and load distribution, multiple search heads can be grouped in clusters.
Search Head:
User Interface: The search head is the user interface where users interact with Splunk. They run searches, build dashboards, and visualize data.
Search Processing: Search heads process search queries, distribute them to indexers, and aggregate the results for display.
Indexer Clusters:
Replication and Sharding: Data can be replicated across multiple indexers for redundancy and distributed storage. Indexers use sharding to manage the workload efficiently.
High Availability: Indexers in a cluster work together to provide failover and load balancing, ensuring uninterrupted service.
Deployment Server:
Configuration Management: The deployment server centralizes the management of configurations, apps, and add-ons across multiple Splunk instances.
Consistency: It ensures that configurations are consistent across various components, reducing the risk of inconsistencies.
Forwarder Management:
- Deployment Server and Monitoring Console: These tools help manage and monitor forwarders in the environment. The deployment server distributes configurations to forwarders, while the monitoring console provides insights into their health and performance.
Data Lifecycle in Splunk:
Ingestion: Data is collected by forwarders, which then send it to indexers for processing.
Indexing: Indexers break down data into events, apply timestamps, and store them in optimized data structures.
Searching: Users interact with the search head to create queries. The search head processes the queries and sends them to indexers for execution.
Indexer Processing: Indexers search through indexed data and return results to the search head, which aggregates and presents them to users.
Visualization: Users build visualizations, dashboards, and reports using the search head's user interface.
Conclusion:
Splunk empowers organizations to extract valuable insights from the vast amount of data they generate daily. Whether it's for IT operations, security, or business analytics, Splunk's real-time data analysis capabilities can revolutionize the way you make decisions and respond to challenges. By understanding the basics of Splunk and its potential, you're poised to unlock a new realm of possibilities in the world of data.
Subscribe to my newsletter
Read articles from Navya A directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Navya A
Navya A
👋 Welcome to my Hashnode profile! I'm a passionate technologist with expertise in AWS, DevOps, Kubernetes, Terraform, Datree, and various cloud technologies. Here's a glimpse into what I bring to the table: 🌟 Cloud Aficionado: I thrive in the world of cloud technologies, particularly AWS. From architecting scalable infrastructure to optimizing cost efficiency, I love diving deep into the AWS ecosystem and crafting robust solutions. 🚀 DevOps Champion: As a DevOps enthusiast, I embrace the culture of collaboration and continuous improvement. I specialize in streamlining development workflows, implementing CI/CD pipelines, and automating infrastructure deployment using modern tools like Kubernetes. ⛵ Kubernetes Navigator: Navigating the seas of containerization is my forte. With a solid grasp on Kubernetes, I orchestrate containerized applications, manage deployments, and ensure seamless scalability while maximizing resource utilization. 🏗️ Terraform Magician: Building infrastructure as code is where I excel. With Terraform, I conjure up infrastructure blueprints, define infrastructure-as-code, and provision resources across multiple cloud platforms, ensuring consistent and reproducible deployments. 🌳 Datree Guardian: In my quest for secure and compliant code, I leverage Datree to enforce best practices and prevent misconfigurations. I'm passionate about maintaining code quality, security, and reliability in every project I undertake. 🌐 Cloud Explorer: The ever-evolving cloud landscape fascinates me, and I'm constantly exploring new technologies and trends. From serverless architectures to big data analytics, I'm eager to stay ahead of the curve and help you harness the full potential of the cloud. Whether you need assistance in designing scalable architectures, optimizing your infrastructure, or enhancing your DevOps practices, I'm here to collaborate and share my knowledge. Let's embark on a journey together, where we leverage cutting-edge technologies to build robust and efficient solutions in the cloud! 🚀💻