The Heart of User Interaction: Exploring the TCP/IP Application Layer
 Samiksha Kute
Samiksha KuteTable of contents

TCP / IP Model
The TCP/IP Model, also called the Internet Protocol Suite, was created by ARPA (Advanced Research Projects Agency).
It’s similar to the OSI model but combines the Application, Presentation, and Session layers into one, resulting in these five layers:
Application Layer
Transport Layer
Network Layer
Data Link Layer
Physical Layer
In this blog, we will take a deep dive into the Application layer.
Application Layer
This is where users interact with the network through apps like WhatsApp, browsers, and more on their devices.
1. Client Server Architecture
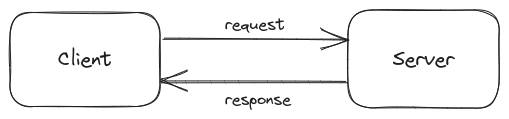
In client-server architecture:
Server: Hosts websites and handles user requests. To host a server, you need a reliable IP address and high reliability to prevent downtime.
Client: People or systems using resources, like making a request to Google.
Servers often form data centers to handle many users. Data centers have static IP addresses, fast internet, and high upload speeds.
Example: Use the below command to check the round-trip time (ping time) between your system and Google’s server:
ping google.com
Can ping time be reduced? Not really, as signals already travel at the speed of light.
2. P2P Architecture
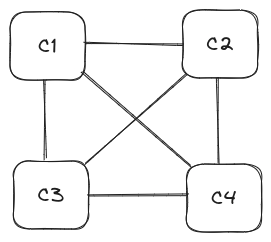
This decentralized setup connects computers directly.
Each computer acts as both a client and a server, making scaling easy. Example: BitTorrent.
3. Protocols
Web protocols include:
TCP/IP
HTTP (Hypertext Transfer Protocol): Browsing websites.
DHCP (Dynamic Host Configuration Protocol)
FTP (File Transfer Protocol): File transfers.
SMTP (Simple Mail Transfer Protocol) - used to send emails
POP3 & IMAP (used to receive email): Receiving emails.
SSH (Secure Shell): Secure remote access.
VNC (Virtual Network Computing)
Telnet (Terminal Emulation) - enables a user to connect to a remote host/device using the Telnet client on Port 23. So, "telnet hostname" would connect a user to the specified hostname, allowing users to manage an account or a device remotely.
UDP - A stateless connection. It is a connection less session, where data may be lost.
4. How do applications talk to each other?
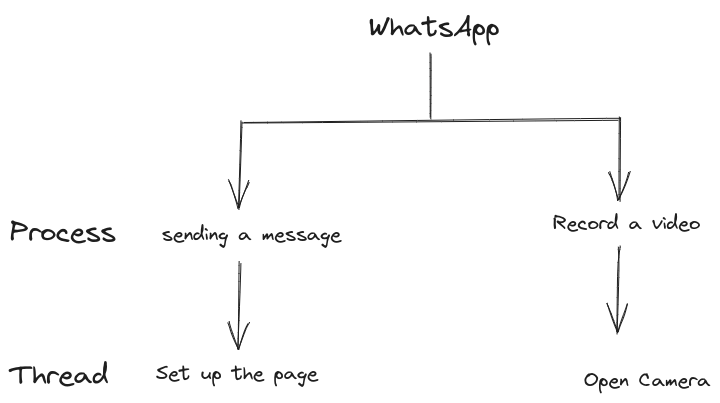
Process: A running instance of a program. One program can have many processes running at once.
Thread: A smaller unit within a process. One process can have multiple running threads.
Communication uses IP addresses to identify devices and ports to identify specific applications.
5. Sockets
- A socket is the interface between a process and the internet, used to send messages between systems.
6. Ports
An IP address tells which device we are working with, and ports tell us which application we are working with.
Now, there may be a possibility that many processes are running on one application, e.g., there may be many Chrome windows open. So, we know that the data that is requested needs to go to Google Chrome, but which instance of Google Chrome? Which process of Google Chrome? To determine this, there are Ephemeral Ports.
Basically, the idea is that if multiple application instances are running, the application will internally work with ephemeral ports.
Once the application is no longer using it, the port will be freed.
These ports can exist on the client side, but on the server side, you have to know the port number. So, servers should have a well-defined port number because clients need to know about it.
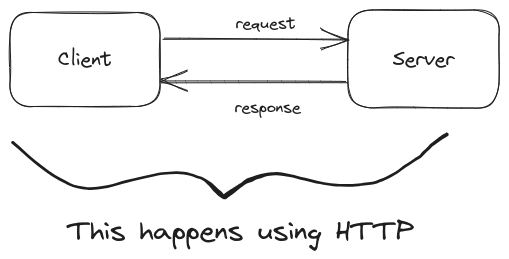
7. HTTP
HTTP is a client-server protocol that tells us how to request data from the server and how the server will send back this data to the client.
When a client makes a request to the server, that is known as an HTTP request, and when the server sends back the response to the client (e.g., sending the requested webpage), that is known as an HTTP response.
HTTP is an application layer protocol and has methods like GET and POST. If we want to get something, we use a GET request. if we want to post something, we use a POST request.
For example, if we want to fetch the latest news articles from a news website we would send a GET request to the server, and it will respond with the relevant articles.
On the other hand, if you need to submit a form on a website, you would use a POST request. For example, when filling out a registration form on an online platform, the data you enter, such as your name, email, and password, will be sent to the server using a POST request to complete the registration process.
Some of the transport layer protocols are: TCP and UDP.
HTTP uses TCP inside it because TCP ensures that all the data is received and everything is reliable.
HTTP does not store states. It is a stateless protocol, which means the server will not store any information about the client by default.
For example, if a client makes requests repeatedly, the server will not treat it as one single client. TCP is connection-oriented, meaning we do not have to lose any of the data that we are sending.
That's why a connection has to be made with the server, and once the connection has been established, we can exchange data. So, we know that the World Wide Web (www) is a collection of web pages. On web pages, we see text, links, documents, videos, images, objects, etc. All of these things have their own specific URLs within the World Wide Web (www).

8. What is a method?
A method is like a command that the client sends to the server, instructing it on what action to perform. For example:
When you use the GET method, it means you are asking the server to give you something, like a webpage, YouTube video, etc.
The POST method is similar to you, as a client, giving something to the server, like submitting a web form with details such as username, password, etc.
With the PUT method, you can place or update data at a specific location on the server.
And finally, the DELETE method is used when you want to remove data from the server, and you do this by sending a DELETE request.
9. Status code
When we send a request to the server, we need some way to know whether the request was successful or it failed, etc. For this purpose, there exist status codes. Following are some of the common status codes:
200: The request was successful.
404: The server couldn't find what we were looking for.
400: There was something wrong with the request we sent (bad request).
500: The server faced an internal error while processing our request.
These codes are grouped into different classes:
1XX: Informational category
2XX: Success codes
3XX: Redirection purpose
4XX: Client errors
5XX: Server errors
10. Cookies
So, we know that HTTP is a stateless protocol. However, whenever we visit a website or log in to, let's say, Amazon, and then close the window and open it again, it miraculously retains our session (saving the items in the cart and keeping us logged in).
So, how does this happen? This is made possible through the use of cookies.
Here's how it works:
When you visit a website for the first time, it sets a cookie in your browser. From then on, every time you make a new request to that website, the cookie is sent along with the request in the request's header.
The server receives the cookie and knows which user the request is coming from. It then checks its database and finds the corresponding state (like your saved items and login information) associated with that user.
There are also third-party cookies, which are cookies set by websites that we haven't directly visited. These cookies might be set by advertisers or other services that are present on the websites we visit. They also collect some information about us for various purposes.
11. How does Email work?
Email operates using different protocols to send and receive messages.
The primary application layer protocol for sending email is SMTP (Simple Mail Transfer Protocol). To receive emails, we can use POP3 (Post Office Protocol 3).
The transport layer protocol involved is TCP (Transmission Control Protocol).
When both the sender and receiver are on the same email service provider (e.g., both are using gmail.com), there is a direct transfer of emails without any intermediate connections.
This can be confirmed using the command:
nslookup -type=mx gmail.com
This command helps find the name and IP address of the SMTP servers for various domains.
POP (Post - Office Protocol)
For downloading emails, we can use POP3.
To do this, we establish a connection to the POP server using TCP on port 110. The server authorizes the client, and then the client requests all the unread or specified emails.
Note: When using POP3, other folders like sent items and drafts are not synchronized.
We have two options after downloading emails:
We can download the emails and delete them from the server.
Alternatively, we can download the emails and keep them on the server as well.
If we download the emails and delete them on the POP server, then the emails will be only available on that particular client. It will not be available on any new device we use.
IMAP (Internet Message Access Protocol) IMAP enables us to view our emails on multiple devices. In this case, the emails will be available on various devices, and we can sync all our folders.
12. DNS(Domain Name System)
We use domain names because it's difficult to remember IP addresses.
Domain names are mapped to IP addresses.
When we enter a domain name like google.com, DNS is used to find the IP address of Google's server. Subsequently, the connection is made to that server.
DNS serves as a directory/database service. When we enter a domain name like google.com, the HTTP protocol takes that domain name, uses DNS to convert it into the corresponding IP address, and then connects to the server.
Since there are countless URLs in the world, having a single database for DNS is impractical and it may lead to data trafficking issues.
To manage domain names effectively and instead of storing everything in a single database, they are divided into various classes, and there are multiple databases for these categories.
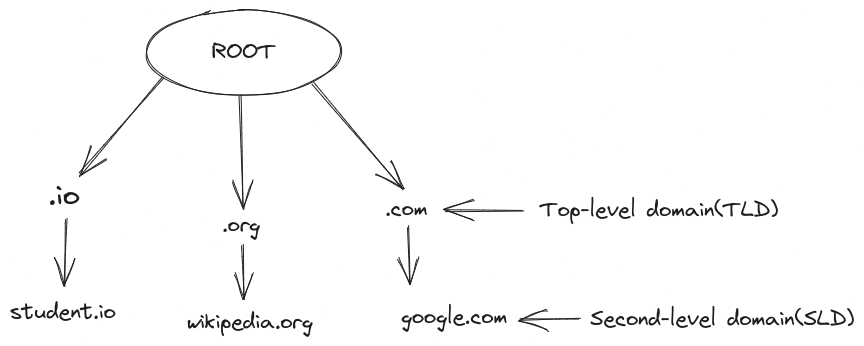
ROOT DNS Server
The highest level is the ROOT DNS Server, and you can find the list of these servers on the website below:
Top-level domains, such as .com, .edu, .uk, .in, are specific to organizations or countries and are managed by ICANN (Internet Corporation for Assigned Names and Numbers), the organization responsible for registering and maintaining top-level domains.
13. What Happens when we enter Google.com?
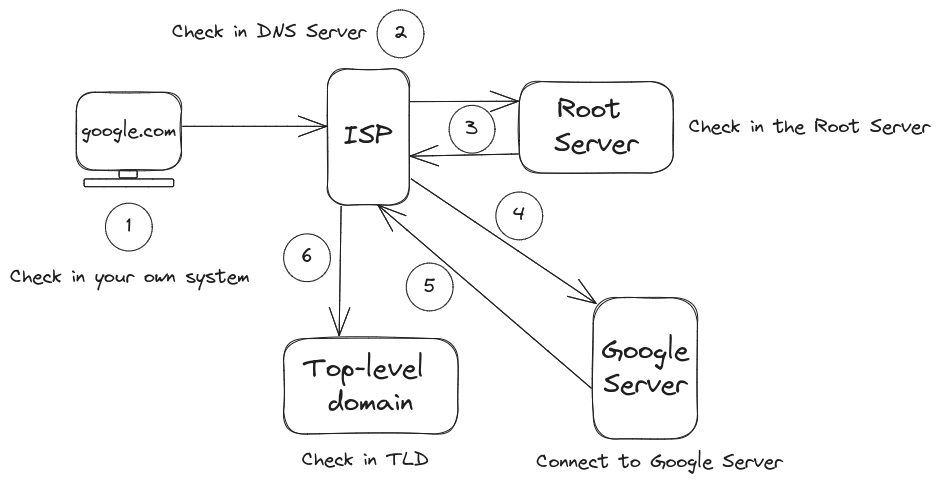
When we enter Google.com in our web browser for the first time, the system stores its IP address in a local cache or local database.
This is done so that we don't have to search for Google.com's IP address repeatedly whenever we visit the site. Even if we visit Google.com multiple times, we don't want to search for its IP address globally each time.
It's important to note that our Internet Service Provider (ISP) has all the information about the websites we visit. Whether we use incognito mode or not, if any illegal activity occurs, the ISP is obligated to inform the authorities.
The first point of contact in this process is the Local DNS Server. If the IP address of Google.com is not found in the local DNS Server, it will then check the Root Server.
If the Root Server also doesn't have the IP address, the Local DNS Server will proceed to check the Top-level domain (TLD) server, which in this case is the .com TLD since we are visiting Google.com.
Once the IP address is found in the TLD server, it will respond to the Root Server with the IP address, and finally, our system can connect to the Google Server using that IP address.
Note: When it comes to domain names, we can't buy them directly; we can only rent them for a certain period. For example, if we rent a domain name from godaddy.com, GoDaddy pays a fee to the organization responsible for managing domain names (ICANN), and we pay an amount to GoDaddy.
Additionally, if we want to see the messages received by the DNS Server, we can use the command below to inspect the DNS-related information for the Google.com domain:
dig google.com
Conclusion
Understanding the TCP/IP Application Layer helps us grasp how different applications work together on the Internet. From sending emails to browsing websites, this layer forms the essential bridge between users and the digital world.
Thank you for reading the blog. For additional topics, check out the complete Computer Networking Series.
Feel free to connect with me on:
Subscribe to my newsletter
Read articles from Samiksha Kute directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Samiksha Kute
Samiksha Kute
Passionate Learner!