Understanding how Babel Works
 Phakorn Kiong
Phakorn Kiong
One of the more interesting I’ve done recently is learning how to modify JavaScript code programmatically using Babel. Babel is a JavaScript transpiler, best known for transpiling ES5+ code into a backwards-compatible version of JavaScript that can run in any browser.
What is a transpiler?
Transpilers are also known as source-to-source compilers. They are tools that read source code written in one programming language and produce equivalent code in another language. Transpilers enables languages like TypeScript and CoffeeScript to exists, which is the syntactic sugar of JavaScript. There are basically three main steps for a transpiler to be able to do what seems like a magical feature.
Lexical Analysis (Tokenization) — Source Code to Token
Syntax Analysis (Parsing) — Token to Abstract Syntax Tree
Code Generation — Abstract Syntax Tree to Source Code
Lexical Analysis (Tokenization)
During this step, the lexical analyzer (let’s call it a tokenizer) converts code in the form of strings into an array of tokens using defined rules. Tokenizer will scan the code, character by character, and when it encounters a symbol or whitespace, it decides whether a word is completed and finally give it a type and value. However, resulting tokens does not explain how things fit together. It represents merely the components of the input.
Babel does not export its tokenizer as part of the package (Its functionality is grouped with @babel/parser, however ESPRIMA provide a simple to use tokenizer that can be used to visualize the result of tokenization. The resulting information is helpful for syntax analysis.
Syntax Analysis (Parsing)
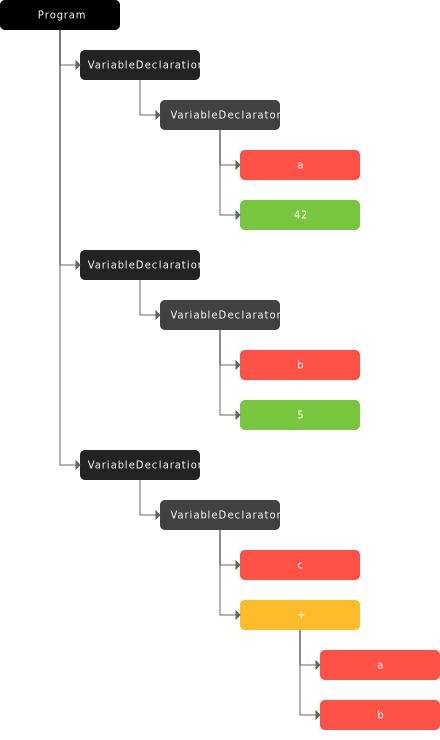
In this step, the tokens produced will be converted into an Abstract Syntax Tree (AST).
AST is a tree representation of the abstract syntactic structure of source code written in a programming language. Each node of the tree denotes a construct occurring in the source code.
AST is useful in representing abstract structure (does not represent every detail appearing in real syntax) of source code. AST can be used to compile code to different languages, transpile code (what babel does), perform static analysis of code, generate source code and more.
The code above will generate the following AST. There are many parsers available to generate AST, which will have some minor differences in taste. You may try the AST viewer here.
Code Generation
During this step, the modified AST will be used to generate the final code to be used. In the context of Babel, this is provided via @babel/generator
Babel
Putting the three steps together, we’re able to manipulate code with confidence by modifying the AST using Babel.
In the following example, we’re looking to change the variable keyword n into x, the flow of the transformation is as follow:
@babel/parserprovides aparsemethod that converts source code into an AST.@babel/traverseprovide us with a way to get to thenodethat we're interested in using a pattern known asvisitor. We're defining an object literal which implements avisitorproperty that consists of an object of methods named to match the node it should process (typing is based on@babel/types). In this example, we're looking forIdentifiernode, and the function will visit bothIdentifieronce (nandy). However, in real-world code where multiplevisitorandpluginsare used, there are chances that anodemight get visited more than once (although rare, it happens). So there should be some checks done to skip the transformation.@babel/generatorturns the modified AST back into code.
All in all, we can see that Babel had taken care of all the three steps for us so we can focus on transforming AST according to our requirements. For the common use-cases of Babel, we can easily mix and match the published plugins to get what we want.
Traversing the AST with Babel
To traverse AST, we simply define an object literal with methods defined for accepting particular node types in a tree (typing is based on @babel/types). For example:
The code above is a simple visitor that during traversal, will call the Identifier() method for every Identifier visited. We can also use aliases as visitor nodes (for example Function is an alias for FunctionDeclaration, FunctionExpression, ArrowFunctionExpression, ObjectMethod and ClassMethod)
While traversing an AST to transform the source code, you should be aware of the traversal sequence. You may run the following code and compare the output with AST Explorer to visualize the flow.
The path we get during traversal is an object representation of the link between nodes. Imagine the following code:
We know that the code above has FunctionDeclaration and Identifier node. If we choose to represent Identifier as a path, we will get something like the snippet below.
Babel does provide additional metadata and methods to make AST transformation easier. In summary, paths are a reactive representation of a node position in the tree, with additional information appended. Whenever you call a method that modifies the tree, Babel manages everything and update the information. Babel makes working with AST very straightforward.
State
We need to be extremely careful about state during AST transformation. Let's take the following code:
Assuming we want to rename foo into baz inside the add function, we could do a hacky transformation like this:
The above transformation should work. We’re changing the param inside FunctionDeclaration and the name inside Identifier. The transformed source code we get is actually like this:
But why? This is because we’re modifying every Identifier with the same name as foo. This is due to the state of AST, and it is likely to happen if you're working with a big codebase.
How could we avoid the above? We could do a recursive traverse inside the FunctionDeclaration to eliminate polluting the global state
The solution above is a very naïve example, actual transformation logic in real-world cases should have more checks to ensure transformation only occurs on the node that you’re interested in.
Scope
Note that JavaScript implements lexical scoping. We can imagine this like a tree structure where every nested node has its scope. Code within a deeper scope can use a reference from a higher scope and create a reference of the same name without modifying it.
When transforming a complex AST, we should be wary of the scope to avoid breaking existing code. Let’s look at the next example and identify the issue with the transformation.
Assume we would like to transform the first param of add function from foo to x. We could easily reuse the logic from the previous example to do the transformation. However, we would end up with the following:
At first, it seems that the transformation is correct. However, the add function refers to x and y from the global scope. Based on the current transformation, the variable x no longer refers to the one in the global scope. In a large codebase, we wouldn't even notice this error as it is almost impossible to keep track of closure and scoping.
Nonetheless, let’s try to solve the example above.
Although the code above is not perfect, it shows how complex and difficult it is to deal with scope during transformation. We have to keep track of all the binding and reference while figuring out if there is a conflict in the identifier name. We're in luck as Babel provide many useful methods that we could use inside path.scope (You may refer to here).
With the power of Babel, we could simplify it down to the following:
The next natural question would be, what are the use cases of Babel. Following is some example that you might be interested in:
Create custom syntax using Babel syntax plugins — Great tutorial by Tan Li Hau
Transform source code across the entire application (let's say transforming all old-fashioned antonymous function with arrow functions)
Create custom linter using Babel transform plugins
At last, have fun with Babel!
Useful Reference
Babel Plugin Handbook by Jamie Kyle
Subscribe to my newsletter
Read articles from Phakorn Kiong directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by