GSoC Chronicles: Coding Week Ten(10)
 Favour James
Favour James
Hi Guys!!
Welcome to my latest blog post, where I’ll be sharing the highlights of my journey in the Google Summer of Code (GSOC) program. Today, I’ll cover my progress during the tenth and eleventh weeks.
In the week 9 blog post, I mentioned my plans to develop a Python script for dataset contribution to the PyG dataset repository. Alongside this, I aimed to refine the project notebooks to ensure reproducibility by other users and eagerly prepare a research poster that I will be presenting at the Deep Learning Indaba conference.
Now let's delve into how these tasks were achieved.
My Progress in Week 10
During this week, my initial step involved transforming the Jupyter Notebook for the brca_tcga InMemoryDataset Class into a Python file. The purpose behind this conversion was to align with the format specifications of datasets found on the PyTorch Geometric GitHub repository.
With guidance from my mentors, the next focus was on ensuring the script's formatting aligns with other Python files in the PyG GitHub repository. To achieve this, I incorporated the pre-commit file from the PyG GitHub page into my repository containing the Dataset Python file for contribution. Using the pre-commit library, I ran the 'pre-commit' command multiple times in my terminal to pass all tests.
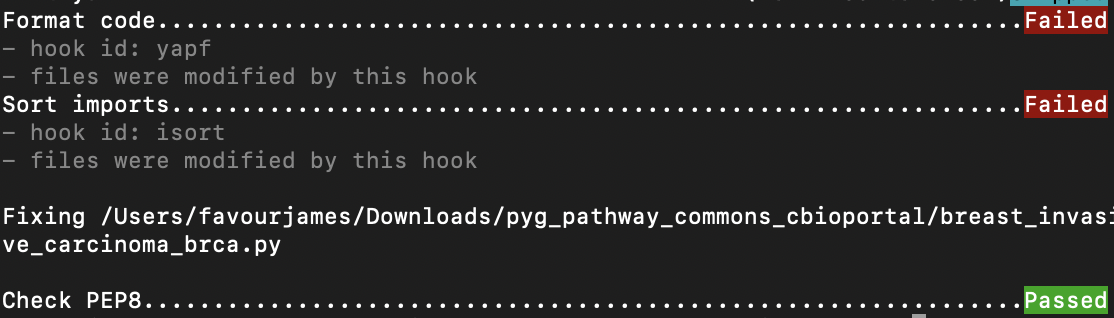
During this process, I carefully edited the scripts to ensure each line was within the 79-character limit, meeting the requirements of the pep8 test. However, I encountered challenges with the "format code" and "sort imports" tests, as shown below. While addressing these issues, I temporarily shifted my focus to the next task: editing the notebooks to enhance reproducibility for other users.
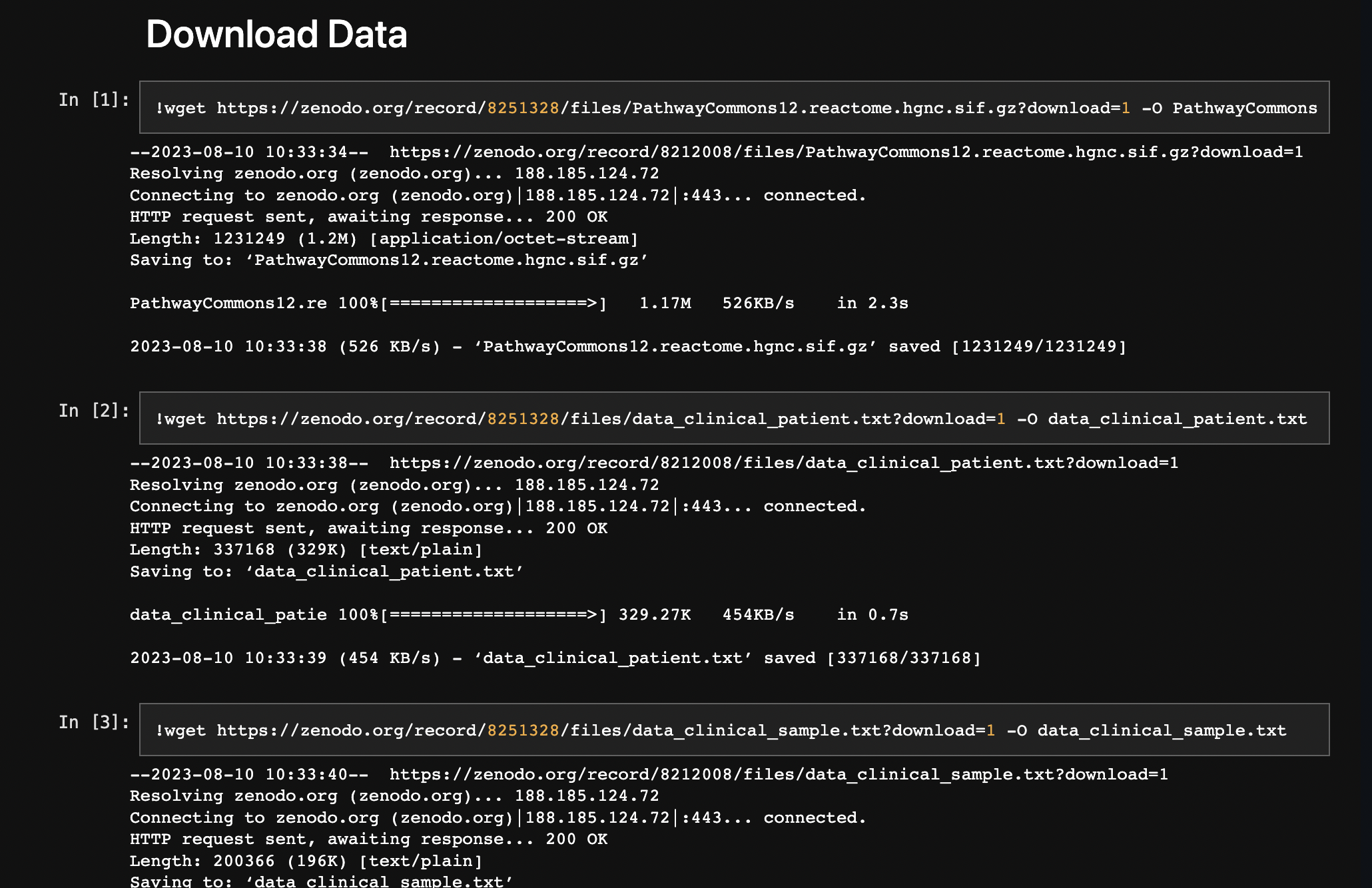
Moving forward, my attention shifted towards the notebooks detailing the dataset preprocessing and modelling procedures. It was crucial to make these notebooks accessible and functional for any user. To achieve this, a necessary step was uploading all essential data files onto the Zenodo site. This strategic move was coupled with code adjustments; now, when the notebook runs, it automatically fetches datasets from Zenodo instead of relying on my Google Drive.
This seamless integration eliminates the need for users to manually procure the preprocessed files before running the notebook. By uploading the necessary data files to Zenodo and implementing code modifications, the notebooks now facilitate automatic dataset retrieval from Zenodo upon execution. This streamlines the user experience, eliminating the need to manually obtain the requisite preprocessed files. The process ensures smooth navigation for all users, fostering greater accessibility and engagement. A simplified excerpt is showcased below:
Finally, my efforts were dedicated to collaborating with my mentors on the creation of a compelling research poster. The origins of this endeavour trace back to week 8, when I embarked on the initial stages. At the outset, my mentor equipped me with a Google Docs template, seamlessly guiding me to populate it with the requisite text and illustrative elements to be integrated into the poster. Subsequently, the transition to the official poster template provided by the Deep Learning Indaba took place on Overleaf. This migration was accompanied by a series of refinements and enhancements carried out during weeks 9 and 10. Numerous rounds of edits and constructive suggestions were exchanged to fine-tune the poster, ensuring it aligns seamlessly with the event's theme and messaging.
The culmination of these collaborative efforts led to the finalization of the poster, which was successfully submitted. As the Deep Learning Indaba 2023 conference approaches, I eagerly anticipate sharing updates about the presentation and eventually revealing the complete poster.
Summary of Progress Made
Python Script Development: I worked on creating a Python script for the InMemoryDataset class of the breast cancer dataset, which is intended for contribution to PyTorch Geometric.
Refining for Reproducibility: To ensure a seamless experience for fellow users, I delved into refining the project notebooks. This endeavour was aimed at bolstering reproducibility, making it easier for others to follow in the project's footsteps.
Completing the Research Poster: A significant milestone was achieved as I finalized the research poster, a task I had been diligently working on. This poster, a culmination of a collaborative effort with my mentors, underwent thorough editing and review before being confidently submitted.
Challenges Faced
Amidst these accomplishments, I encountered a couple of challenges. The foremost was navigating the process of getting the Python script to successfully pass the mandated tests on the PyTorch Geometric GitHub repository. While I'm still in the process of resolving this, I remain optimistic and determined to overcome this hurdle. Additionally, the task of correctly zipping the datasets for upload on Zenodo presented an unexpected obstacle. Grateful for my mentors' guidance, we efficiently tackled this challenge during our weekly meeting, equipping me with valuable knowledge for similar situations in the future.
My Plans for Week 11
Test Success for the Python Script: I'm committed to resolving the issue inhibiting the successful passage of the Python script through the required tests, striving for a robust and error-free outcome.
Graph Attention Networks Model Development: My journey into model development continues, with a specific focus on Graph Attention Networks (GAT). This exploration is poised to offer new insights and contribute to the overarching project goals.
As I look ahead to the upcoming week, I'm energized by the progress achieved and the promise that each new challenge brings.
I'm excited to bring you up to speed on my recent progress, and I welcome you to join me on my upcoming blog post. In my next update, I'll provide insights into the conclusive steps of readying the dataset for its PyTorch Geometric submission. Your continued readership is greatly appreciated! Thank you for staying engaged until the end.
(P.S. If you are interested in knowing more about my project, feel free to check it out on GitHub. https://github.com/cannin/gsoc_2023_pytorch_pathway_commons)
Subscribe to my newsletter
Read articles from Favour James directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Favour James
Favour James
I am an elect/elect student and a data scientist. I love AI and all you can do with it and want to apply it in my course of study. I would also like to see more of data science and AI applications in the health sector.