What is Twitter’s Tweet Recommendation Algorithm?
 Mayank Sharma
Mayank SharmaTwitter is a platform that wants to show you the most relevant and up-to-date information from around the world. But with millions of tweets being posted every day, how does Twitter choose which tweets to show you? In this blog post, we will take a closer look at how Twitter’s recommendation algorithm selects Tweets for your timeline.
How do twitter choose Tweets?
At the core of Twitter’s recommendations are a set of models and features that extract latent information from Tweets, user profiles, and engagement data. These models aim to answer important questions about the Twitter network, such as predicting the probability of future user interactions or identifying trending Tweets within specific communities. By accurately answering these questions, Twitter can deliver more relevant recommendations to its users.
The recommendation pipeline consists of three main stages that utilize these core models and features:
Candidate Sourcing: In this stage, the recommendation algorithm fetches the best Tweets from different sources to create a pool of candidate Tweets.
Ranking: Once the candidate Tweets are collected, a machine learning model is used to rank each Tweet.
Heuristics and Filters: After ranking, heuristics and filters are applied to further refine the recommendations. These heuristics and filters eliminate Tweets from users you’ve blocked, filter out NSFW (Not Safe for Work) content, and remove Tweets that you’ve already seen. .
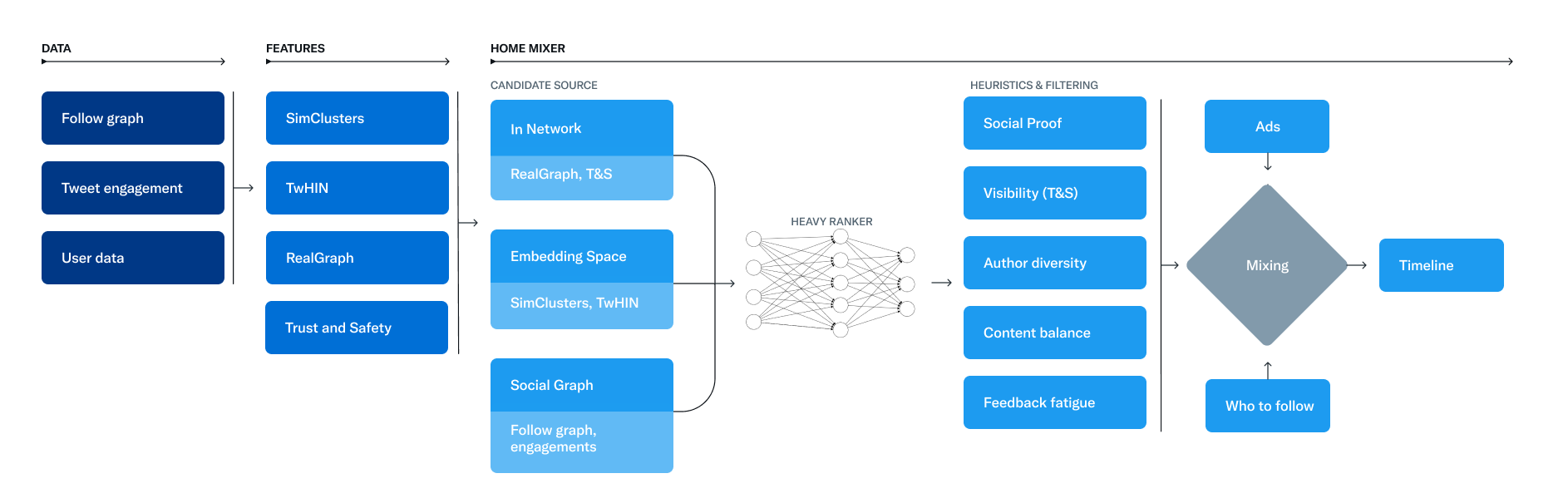
The service responsible for constructing and serving the For You timeline is called Home Mixer, which is built on Product Mixer, Twitter’s custom Scala framework. Home Mixer acts as the software backbone that connects candidate sources, scoring functions, heuristics, and filters.
Let’s dive deeper into the key components of this system, following the order in which they are called during a single timeline request:
Candidate Sources
Twitter utilizes several candidate sources to retrieve recent and relevant Tweets for each user. These sources include in-network and out-of-network sources. The in-network source primarily focuses on delivering the most relevant Tweets from users you follow. It ranks these Tweets based on their relevance using a logistic regression model. The selection of in-network Tweets is heavily influenced by a model called Real Graph, which predicts the likelihood of engagement between two users.
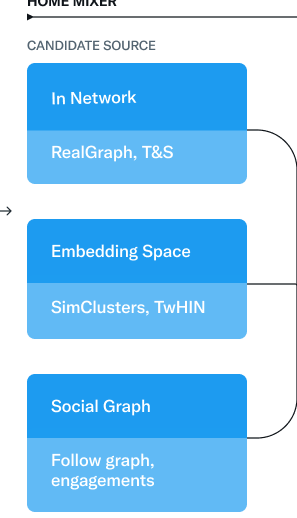
The out-of-network sources, on the other hand, tackle the challenge of finding relevant Tweets from users you don’t follow. Twitter uses two approaches to address this issue: Social Graph and Embedding Spaces.
Social Graph: By analyzing the engagements of the people you follow and those with similar interests, Twitter estimates what you would find relevant. It traverses the graph of engagements and follows to determine which Tweets the people you follow have recently engaged with and what similar Tweets they have liked. These insights help generate candidate Tweets, which are then ranked using a logistic regression model.
Embedding Spaces: Embedding space approaches aim to understand content similarity. Twitter generates numerical representations (embeddings) of users’ interests and Tweets’ content, allowing them to calculate the similarity between users, Tweets, or user-Tweet pairs. By leveraging embedding spaces like SimClusters, Twitter can identify similar Tweets and users based on their interests. SimClusters are communities anchored by a cluster of influential users, generated using a custom matrix factorization algorithm.
Ranking
The goal of the ranking stage is to determine the relevance and engagement potential of each candidate Tweet. Twitter utilizes a neural network with approximately 48 million parameters to continuously train its ranking model. This neural network takes into account thousands of features and interactions, optimizing for positive engagement metrics such as Likes, Retweets, and Replies. Each candidate Tweet is assigned a score based on these predictions, and the Tweets are subsequently ranked.
Heuristics, Filters, and Product Features
After ranking, heuristics, filters, and various product features are applied to enhance the user experience. Some examples of these features include:
Visibility Filtering: Filtering out Tweets based on their content and user preferences, including filtering Tweets from blocked or muted accounts.
Author Diversity: Ensuring a balanced mix of Tweets from different authors to avoid an overwhelming number of consecutive Tweets from a single author.
Content Balance: Striving to deliver a fair balance of in-network and out-of-network Tweets to provide a diverse feed.
Feedback-based Fatigue: Adjusting the score of certain Tweets based on negative feedback received.
Social Proof: Including out-of-network Tweets in the feed only if they have a second-degree connection to the Tweet (e.g., someone you follow has engaged with the Tweet or follows the Tweet’s author).
Conversations: Threading replies together with the original Tweet to provide more context.
Edited Tweets: Detecting stale Tweets on a user’s device and replacing them with edited versions.
Mixing and Serving
As the final step in the process, Home Mixer blends the selected Tweets with other non-Tweet content like Ads, Follow Recommendations, and Onboarding prompts. The resulting mix is then sent back to the user’s device for display.
The entire pipeline described above runs approximately 5 billion times per day and completes in under 1.5 seconds on average. Each execution requires 220 seconds of CPU time, which is nearly 150 times the latency perceived by users on the app.
Subscribe to my newsletter
Read articles from Mayank Sharma directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by