Creating a dashboard for restaurant with sentiment analysis using tf-idf and data analytics
 Harsh Joshi
Harsh JoshiTable of contents

The project GitHub link is Restaurant-Sentiment, Do visit and if you like it give it a star, If you want to use it then clone the repo, create a .env file in api folder and add the database URL.
Part 1- Creation of sentiment analysis model
Step 1: Understanding and defining business case and needs
Introduction: Hey there, fellow foodies and tech enthusiasts! Ever wondered what lies beneath the culinary curtain, beyond the sizzling sounds and tantalizing aromas? Well, gear up because we're about to unveil the secrets! 🍔📊
Imagine a dashboard that serves as the restaurant industry's tell-all confidant. It's where sentiments and scores blend to form a symphony of customer experiences.
Dishing Out Insights: Prepare your taste buds for an exciting journey! At the core of our endeavour is a sentiment-infused scorecard that paints a comprehensive picture of restaurants. We're talking about a digital magic wand that assesses restaurants on various fronts – food quality, ambience allure, cleanliness standards, service swiftness, and, of course, the candid words in customer reviews
Tech Stack: Our ensemble cast includes tech luminaries such as Git, orchestrating seamless code collaboration. Picture Docker as our reliable courier, ensuring the app's safe arrival in any digital realm. Now, let's introduce the star performer – Flask, conjuring APIs that transform data into interactive experiences, just like a maestro leading an orchestra.
But the star of our tech opera? Machine learning and NLP! Imagine them as culinary virtuosos, dissecting reviews to uncover the emotional spectrum – from elation to neutrality, and even the rare pinch of discontent. 🌟🔍
A Three-Course Adventure: Hungry for the nitty-gritty? Our voyage is divided into three delectable parts. Part 1, our current destination, is all about crafting a sentiment analysis model with a finesse akin to a gourmet chef. Part 2? That's where the backstage comes alive – sturdy backend architecture, APIs that hum with efficiency, and a connection to an intelligent database. Lastly, Part 3 dishes out the pièce de résistance – a user-friendly dashboard, that presents insights like culinary masterpieces.
Get Ready to Savor: Let's embark on a journey where technology meets the art of dining. This fusion promises to be as exhilarating as a culinary masterpiece. Join us as we stir together data and the gastronomic experience in a whirlwind of technological excitement! 🚀🍽️
Step 2: Gathering the Goods – Acquiring User Data 📊
Embarking on Data Quest: Greetings, fellow data enthusiasts! It's time to don our virtual explorer hats and set out on a data adventure like no other. We've just located our treasure trove – the foundation of our sentiment analysis journey.
Links 1:https://github.com/harsh0506/RestaurantSentiment/blob/main/data/Restaurant%20reviews.csv
2:https://github.com/harsh0506/RestaurantSentiment/blob/main/data/Yelp%20Restaurant%20Reviews.csv
3:https://github.com/harsh0506/RestaurantSentiment/blob/main/data/Restaurant_Reviews.tsv
These datasets are like gold mines of customer reviews. They're packed with insights, complaints, praises, and everything in between. So, let's roll up our sleeves and get ready to turn this data into our secret sauce for a mouthwatering dashboard! 🍽️📈
Step 3 Creating Python environment and installing libraries
The file structure is given below:
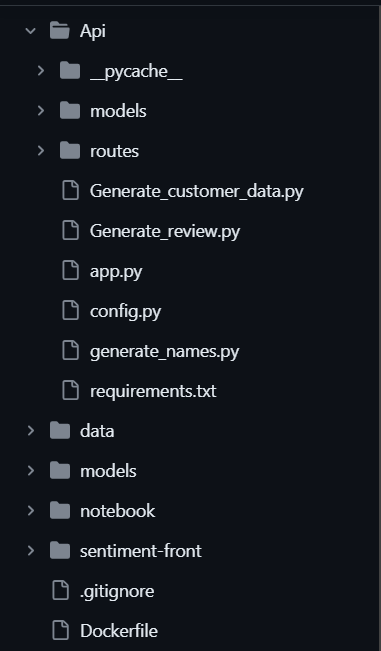
# Create main project directory
mkdir YourProjectName
cd YourProjectName
# Create Api directory and its subdirectories
mkdir -p Api/models
mkdir -p Api/routes
# Create data directory
mkdir data
# Create models directory
mkdir models
# Create notebook directory and its subdirectories
mkdir -p notebook/.ipynb_checkpoints
# Create sentiment-front directory
mkdir sentiment-front
# Inside the Api directory
cd Api
# Create app.py, config.py, Generate_customer_data.py, Generate_review.py, generate_names.py
touch app.py config.py Generate_customer_data.py Generate_review.py generate_names.py
# Inside the models directory
cd models
# Create init.py, customer_model.py, restaurant_model.py, review_model.py
touch init.py customer_model.py restaurant_model.py review_model.py
# Inside the routes directory
cd ../routes
# Create init.py, cust_route.py, res_route.py, review_route.py
touch init.py cust_route.py res_route.py review_route.py
# Return to the main project directory
cd ../../
# Create sentiment-front/.gitignore, Dockerfile, PreProcessExample.py, README.md
cd sentiment-front
touch .gitignore Dockerfile PreProcessExample.py README.md
# Return to the main project directory
cd ..
# Create .gitignore, Dockerfile, PreProcessExample.py, README.md
touch .gitignore Dockerfile PreProcessExample.py README.md
Run commands for creating and activating the anaconda environment
# Create a Conda environment (replace 'myenv' with your desired environment name)
conda create -n myenv python=3.8
# Activate the Conda environment
conda activate myenv
# Install the required libraries
conda install flask gunicorn flask-cors pandas nltk python-dotenv psycopg2 aiohttp flask-sqlalchemy scikit-learn=1.3.0 -c conda-forge
# Install async support for Flask (Flask[async])
pip install "Flask[async]"
Step 4: Unveiling the Data – Let's Get Curious! 🕵️♂️
Alright, data explorers, it's time to put on our detective hats and unravel the story hidden within the numbers. Get ready to dive into the world of data with us!
Firing Up the Notebook: We're kicking things off in our trusty Jupyter Notebook. This is where the magic happens – data exploration, visualisation, and more!
Python -m notebook
# Importing the essentials
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import FunctionTransformer
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
from sklearn.metrics import roc_auc_score
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import TweetTokenizer
from nltk.corpus import stopwords
from nltk.tag import pos_tag
import pandas as pd
import numpy as np
import chardet
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
from plotly import graph_objs as go
import plotly.express as px
import plotly.figure_factory as ff
Meet the Datasets: Let's bring our stars onto the stage – the datasets we'll be working with. They're a blend of reviews from various sources, ready for us to uncover their secrets!
# Importing the datasets
RDF1 = pd.read_csv('../data/Restaurant reviews.csv')
RDF2 = pd.read_csv('../data/Restaurant_Reviews.tsv', delimiter='\t')
RDF3 = pd.read_csv('../data/Yelp Restaurant Reviews.csv')
Step 5: Data pre-processing
Creating Balanced and Unified Grounds for Analysis!
Alright, data balancers, let's whip up some magic to ensure our analysis is rock-solid and ready for action! 🪄🤝
Choosing the Right Columns:
First things first – let's narrow our focus to the essentials. We're looking at you, "Review Text" and "Rating." You're the stars of our show! 🌟
# Selecting the key columns
RDF1 = RDF1[["Review", "Rating"]]
RDF3 = RDF3[["Review Text", "Rating"]]
Balancing Dataset: Now, it's time to ensure fairness in our dataset. We're all about balance, right? Our trusty function steps in to balance the ratings distribution.
# Defining our balancing function
def balance_dataset(df, column_name, sample_size):
# Step 1: Bid farewell to nulls
df = df.dropna()
# Step 2: Numbers matter - convert and clean
df.loc[:, column_name] = df[column_name].apply(lambda x: int(float(x)) if str(x).isnumeric() else np.nan)
df = df.dropna()
# Step 3: Let's stick to integers
df.loc[:, column_name] = df[column_name] // 1
# Step 4: Seeking equality in distributions
smallest_distribution = df[column_name].value_counts().min()
# Step 5: Taking samples from the heart
balanced_data = df.groupby(column_name).apply(lambda x: x.sample(n=smallest_distribution, random_state=42)).reset_index(drop=True)
# Step 6: A balanced gift for our analysis
return balanced_data
# Balancing the datasets
RDF1 = balance_dataset(RDF1, 'Rating', 700)
RDF3 = balance_dataset(RDF3, 'Rating', 700)
Bringing It All Together:
Lastly, let's unify the data sources and give them similar names for an elegant blend of insights.
# Renaming for uniformity
RDF1 = RDF1.rename(columns={'Review': 'Review Text'})
# Time for the grand unification
concatenated_data = pd.concat([RDF1[['Review Text', 'Rating']], RDF3[['Review Text', 'Rating']]])
concatenated_data = concatenated_data.reset_index(drop=True)
df = concatenated_data
# A touch of rating transformation magic
df['Rating'] = df['Rating'].apply(lambda x: 0 if x <= 2 else 1)
With this balance and harmony in our dataset, we're all set for the next phase of our sentiment analysis journey! 📊✨
Cleaning Up for Clarity: Getting Your Text Ready!
Hey, text wranglers! It's time to clean up the text data so that our sentiment analysis has a smooth path to follow. Let's break down our text preprocessing journey and see why these steps are the secret spices for making our analysis sing! 🎶🧹
Why Text Preprocessing Matters:
Text data can be a wild jungle of HTML tags, URLs, punctuation, and all sorts of distractions. We're taming it for a clear analysis. We're talking about converting everything to lowercase, removing unwanted characters, and URLs, and even handling tricky negations. This cleanup ensures our analysis doesn't get caught up in the chaos and stays focused on the message.
# Cleaning up the text data
def preprocess_text(df):
# Remove HTML tags
df['clean_text'] = df['Review Text'].apply(lambda x: re.sub(r'<.*?>', '', x))
# Convert to lowercase
df['clean_text'] = df['clean_text'].str.lower()
# Remove URLs, email addresses, and phone numbers
df['clean_text'] = df['clean_text'].apply(lambda x: re.sub(r'http\S+|www\.\S+|\S+@\S+|\d{10}', '', x))
# Handling negation for better analysis
df['clean_text'] = df['clean_text'].apply(lambda x: re.sub(r'\bnot\b(\w+)', r'not_\1', x))
# Removing special characters and punctuation
df['clean_text'] = df['clean_text'].apply(lambda x: re.sub(r'[^a-zA-Z0-9\s]', '', x))
df['clean_text'] = df['clean_text'].apply(lambda x: x.translate(str.maketrans('', '', string.punctuation)))
# Removing numeric tokens
df['clean_text'] = df['clean_text'].apply(lambda x: re.sub(r'\b\d+\b', '', x))
# Tokenization
df['tokens'] = df['clean_text'].apply(word_tokenize)
# Removing stopwords
stop_words = set(stopwords.words('english'))
df['tokens'] = df['tokens'].apply(lambda x: [word for word in x if word not in stop_words])
# Stemming
stemmer = PorterStemmer()
df['tokens'] = df['tokens'].apply(lambda x: [stemmer.stem(word) for word in x])
# Lemmatization
lemmatizer = WordNetLemmatizer()
df['tokens'] = df['tokens'].apply(lambda x: [lemmatizer.lemmatize(word, get_wordnet_pos(word)) for word in x])
# Converting tokens into a single string
df['tokens'] = df['tokens'].apply(lambda x: ' '.join(x))
return df
preprocess_text(df)
Impact of Text Preprocessing: Imagine reading a book with missing letters and random symbols – tough, right? That's similar to how unprocessed text affects our analysis. Preprocessing transforms text into a more manageable and understandable format. Removing clutter, noise, and redundant information lets our sentiment analysis algorithms focus on what truly matters – the sentiment conveyed by the words.So there you have it, text warriors! Our preprocessing steps ensure our text is in tip-top shape, setting the stage for our sentiment analysis to shine! ✨📚
Step 6: Dividing and Conquering Data: Let's Talk Vectors!
Welcome to the realm of data splitting and vectorization – where we slice and dice our data and turn words into numbers that algorithms can groove with! 🧩🔢
Dividing Our Troops: First things first, let's split our data into training and testing groups. It's like having a rehearsal stage for our analysis!
# Splitting the data into training and testing sets
X_train, X_test, Y_train, Y_test = train_test_split(df['tokens'], df['Rating'], test_size=0.2, random_state=42)
Unlocking the Power of Bag of Words (BoW): Text to Numbers
Now, let's delve into the ingenious concept of Bag of Words (BoW) – a methodology that transcends text into numerical data, ripe for computational analysis. Imagine a bottomless bag into which words are thrown without concern for their order, only their presence. BoW is this very bag, adept at converting textual content into a matrix of word occurrences. Each cell of this matrix holds the count of how often a particular word occurs within a document.
The Math Behind Bag of Words: Consider a collection of documents represented by the set D. For each document d in D, we construct a vector v of size |V|, where |V| represents the vocabulary size (unique words across all documents). The elements of v denote the frequency of words in Document D. If word w appears k times in Document D, then the kth element of v corresponds to word w.
Mathematically, if v_w is the count of word w in document d, then v = [v_w1, v_w2, ..., v_w|V|]. This vector representation ensures that each document can be mathematically compared based on word frequency.
By representing text in this numerical fashion, BoW enables machine learning algorithms to operate on the data seamlessly, unearthing hidden patterns within the language.
In essence, BoW provides a distinctive profile for every piece of text, as if each text has been endowed with a unique numeric fingerprint. This fingerprinting paves the way for computational exploration of textual content, where words become numbers and insight awaits discovery.
Unveiling Text Transformation: Enter TF-IDF!
Gladly! Let's delve into the fascinating world of TF-IDF (Term Frequency-Inverse Document Frequency) vectorization. This method encapsulates the essence of words in documents, going beyond mere presence and exploring their significance within the context. Let's unravel the code, the rationale, the math, and the magic behind it!
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(max_features=6000, ngram_range=(1,2), smooth_idf=False)
tfidf.fit(X_train)
# Transforming training and test data using TfidfVectorizer
tfidf_X_train = tfidf.transform(X_train).toarray()
tfidf_X_test = tfidf.transform(X_test).toarray()
The Thought Behind It: Unlike BoW, which counts word occurrences, TF-IDF captures the importance of words within documents concept is twofold:
Term Frequency (TF): It measures how frequently a word appears in a document, aiming to reflect the word's significance within that document.
Inverse Document Frequency (IDF): It gauges how unique a word is across the entire corpus, rewarding words that are distinct and penalizing common ones.
The Mathematics and Logic: Mathematically, for a term w and document d:
Term Frequency (TF): tf(w, d) = Number of times word w appears in document d / Total words in document d.
Inverse Document Frequency (IDF): idf(w) = log(Number of documents / Number of documents containing word w).
The Mathematics and Logic: Mathematically, for a term w and document d:
Term Frequency (TF): tf(w, d) = Number of times word w appears in document d / Total words in document d.
Inverse Document Frequency (IDF): idf(w) = log(Number of documents / Number of documents containing word w).
The Advantages and Disadvantages: Compared to BoW, TF-IDF recognizes that not all words carry equal significance. It addresses the shortcomings of BoW by assigning higher weights to rare words that hold more meaning. While it excels at capturing context, TF-IDF might falter when dealing with extremely short documents or failing to capture the true semantic meaning of words.
Step 7: Model fitting
Buckle up, data voyagers! We're venturing into the realm of machine learning algorithms, where our trusty companions – Random Forest, Multinomial Naive Bayes, Support Vector Machine (SVM), AdaBoost, and Bernoulli Naive Bayes – will decipher the language of sentiment from our transformed text data. Let's demystify the code, the strategy, and the mathematical elegance behind each algorithm.
Random Forest – A Forest of Decisions:
RF = RandomForestClassifier()
RF.fit(BOW_X_train, Y_train)
RF_Y_pred = RF.predict(BOW_X_test)
RF_accuracy = accuracy_score(Y_test, RF_Y_pred)
RF_cm = confusion_matrix(Y_test, RF_Y_pred)
Random Forest amalgamates a multitude of decision trees, each learning from different aspects of the data. By combining their predictions, it provides a robust analysis.
Multinomial Naive Bayes – Bayes' Blessing:
MNB = MultinomialNB(alpha=0.3, fit_prior=True)
MNB.fit(BOW_X_train, Y_train)
MNB_Y_pred = MNB.predict(BOW_X_test)
MNB_accuracy = accuracy_score(Y_test, MNB_Y_pred)
MNB_cm = confusion_matrix(Y_test, MNB_Y_pred)
Naive Bayes leverages probability theory to classify data. It assumes that features are independent, simplifying calculations. Multinomial Naive Bayes fits perfectly for text data, treating words as features.
Support Vector Machine (SVM) – Drawing the Line:
SVM = SVC()
SVM.fit(BOW_X_train, Y_train)
SVM_Y_pred = SVM.predict(BOW_X_test)
SVM_accuracy = accuracy_score(Y_test, SVM_Y_pred)
SVM_cm = confusion_matrix(Y_test, SVM_Y_pred)
SVM seeks the optimal line that separates data into classes. By maximizing the margin between classes, it ensures robust classification.
AdaBoost – Boosting with Confidence:
adaboost = AdaBoostClassifier()
adaboost.fit(BOW_X_train, Y_train)
adaboost_Y_pred = adaboost.predict(BOW_X_test)
adaboost_accuracy = accuracy_score(Y_test, adaboost_Y_pred)
adaboost_cm = confusion_matrix(Y_test, adaboost_Y_pred)
AdaBoost enhances model accuracy by combining several weak learners into a strong ensemble, boosting predictive power.
Bernoulli Naive Bayes – The Binary Perspective:
BNB = BernoulliNB(alpha=0.3, fit_prior=True)
BNB.fit(BOW_X_train, Y_train)
BNB_Y_pred = BNB.predict(BOW_X_test)
BNB_accuracy = accuracy_score(Y_test, BNB_Y_pred)
BNB_cm = confusion_matrix(Y_test, BNB_Y_pred)
Bernoulli Naive Bayes is tailored for binary classification, like our sentiment analysis. It handles data where features are binary (present or absent).
Mathematics and Logic Behind It: Machine learning algorithms use a myriad of mathematical equations to adjust model parameters based on training data. Naive Bayes, in particular, leverages Bayes' theorem, calculating probabilities of different classes given the features observed.
Advantages and Disadvantages: Naive Bayes algorithms excel in handling text data due to their probabilistic nature and simplicity. They're efficient, even with limited data. However, they assume feature independence, which might not hold true for complex relationships in some datasets.
Do the same using tf-idf
Step 8:Preserving the Power of Models:
Saving for Future Insights
Indeed, we've voyaged through the algorithmic seas, and the Bernoulli model combined with TF-IDF has illuminated our path with accuracy. Now, let's immortalize these models for future adventures. Buckle up for the last leg of our journey – model saving!
Salvaging Bernoulli's Brilliance:
# Save the Bernoulli Naive Bayes model as a .pkl file
with open('../models/bernoulli_model.pkl', 'wb') as file:
pickle.dump(BNB, file)
Preserving the TF-IDF Magic:
# Save the trained TF-IDF Vectorizer using pickle
with open('../models/tfidf.pkl', 'wb') as f:
pickle.dump(tfidf, f)
With these lines of code, we're creating pickled files that encapsulate our trained Bernoulli Naive Bayes model and the precious TF-IDF Vectorizer. These files are like treasure chests – they hold the wisdom and power of our models, ready to be opened and utilized whenever needed.
As you embark on new data journeys, these models will serve as trusty companions, guiding you with the insights they've learned. Remember, it's not just about analyzing data; it's about building bridges between the present and the future. 🗺️🔮
About Me
I’m Harsh Joshi, an aspiring AI Engineer passionate about sharing knowledge and helping fellow enthusiasts in the field of machine learning and artificial intelligence. You can find me on various platforms:
Email: joshiharsh0506@gmail.com
GitHub: harsh0506
Portfolio Website: harshjcodes.netlify.app
LinkedIn: Harsh Joshi
Thank you for joining me on this journey of building a restaurant with sentiment analysis using tf-idf and data analytics App (part 1). I’m excited to continue guiding you through the api development and deployment process in the upcoming conclusion!
Stay curious and keep learning,
Harsh Joshi Aspiring AI Engineer
Subscribe to my newsletter
Read articles from Harsh Joshi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Harsh Joshi
Harsh Joshi
Aspiring fresher with expertise in Python, React, ML, AWS, and more. Eager to innovate and create impactful products, seeking opportunities in frontend development and beyond.