Guide written by a novice creator on how to migrate Airbyte connector to Low-code
 Shivam Agarwal
Shivam Agarwal
This is a guide written by a novice developer who embarked on the journey to explore the open-source community with the support of his fellow comrades.
Hola folks,
This is Shivam Agarwal, and I work as a data engineer. I'm excited to present to you a guide that also encapsulates my personal experience. This guide chronicles my journey of attempting to migrate an existing Airbyte source connector from Python CDK to Low-Code CDK, with Openweather being my chosen starting point. But before delving into the specifics of my endeavor, let's first gain a clear understanding of what Airbyte is.
What is Airbyte?
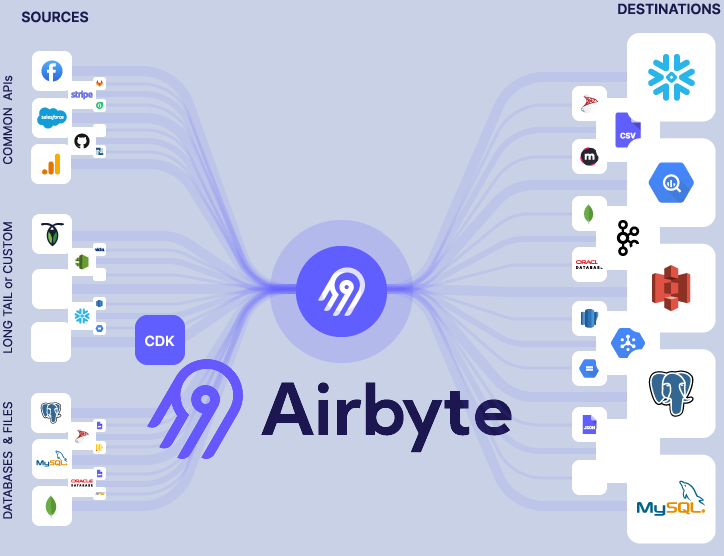
So as per the official website :
Airbyte is an open-source data integration engine that helps you consolidate your data in your data warehouses, lakes and databases.
What I believe Airbyte to be :
Airbyte is a tool that helps data engineers and data professionals to cut out the stress associated with handling data.
Now we have a gist of the tool (I hope the one-liners did the job :P). Let's delve into the focal points of this discussion. My aim is to offer a concise breakdown of the content that lies ahead. I'll be guiding you through the process of migrating a "simple" API connector to Low-code CDK.
Let's start with the basics :
Prerequisites:
python3 (better to have python 3.10 )
docker ( If you don't have it installed, use this link to set it up )
API key of your source
Local setup of Airbyte:
Step 1:
Fork the Airbyte repository and make a local clone of it in your system. If you dont know the commands refer to this - https://docs.github.com/en/get-started/quickstart/fork-a-repo
Clone Command -
git clone https://github.com/<your username>/airbyte.git
Step 2 :
Once you have the repository cloned on your local system, cd into the airbyte root directory
cd airbyte
and run the following command
./run-ab-platform.sh
or
sudo ./run-ab-platform.sh --if you dont have proper priviledges set for docker
This will set up the Airbyte platform on your system. To validate the setup check for the Airbyte banner. Once you are able to see it visit http://localhost:8000. By default, the username is airbyte and password password (love the creativity here :P)
Step 3 : (optional)
If you are not able to make changes to the files like saving or updating. Use this command in the airbyte's root directory to change the permission. This is for Linux based OS like Ubuntu or macOS as well
sudo chown username:username -R .
We are done with the formalities. Let the migration of connectors begin !!!!
Getting started with the templating
We need to first set up the new connector source to be migrated.
Before we start, we need to make the backup of the connector we want to migrate.

For my use case, I did it by updating the source directory name and adding a "-backup" to it (something that was suggested by @bktcodedev). Make sure you do not commit this directory. This backup will help you go through the functionalities that are supported by the connector

Now you can create the new source.
In order to do so first move into the template generator directory and execute the ./generate.sh bash file. Commands for this would be as follows :
cd airbyte-integrations/connector-templates/generator
./generate.sh
This will bring up an interactive helper application.

Use the arrow keys to pick a template from the list. Select the Configuration Based Source template and then input the name of your connector.

The application will create a new directory airbyte/airbyte-integrations/connectors/ with the name of your new connector. The generator will create a new module for your connector with the name source-<connector-name> for me it was source-openweather.
Now you have the source configured. What next? Adding the dependencies and creating a virtual environment.
Creating a Virtual Environment and installing the dependencies
Let's start by creating a python virtual environment for our source. The provided command assumes that the python reference corresponds to a python version that is 3.9.0 or newer. In certain instances, python might direct to a Python2 setup, while python3 indicates Python3. If this situation applies to your system, replace python within the command. The following python usages will then employ the virtual environment established for the connector. (Personal note: In my case, the Python version is 3.10)
cd ../../connectors/source-exchange-rates-tutorial
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
These steps create an initial Python environment and install the dependencies required to run an API Source connector.
Let's verify everything works as expected by running the Airbyte spec operation:
python main.py spec
This output is an indication that we are moving in the righteous path. Let's GOOO!!!!
{"type": "SPEC", "spec": {"documentationUrl": "https://docsurl.com", "connectionSpecification": {"$schema": "http://json-schema.org/draft-07/schema#", "title": "Python Http Tutorial Spec", "type": "object", "required": ["TODO"], "additionalProperties": false, "properties": {"TODO: This schema defines the configuration required for the source. This usually involves metadata such as database and/or authentication information.": {"type": "string", "description": "describe me"}}}}}
This is a simple sanity check to make sure everything is wired up correctly. More details on the spec operation can be found in Basic Concepts and Defining Stream Schemas.
Now the next step would be to go through the directory structure and list out the important files. Files that we would add details to or update.
Files of interest (where the doughs at )

We are prepared to commence the implementation of the connector.
Throughout this tutorial, we will be modifying several files that were produced by the code generator:
source-openweather/source_openweather/manifest.yaml: This document serves as the connector's manifest. It outlines how data should be extracted from the API source and specifies the configurable inputs for the connector.source-openweather/integration_tests/configured_catalog.json: This file represents the connector's catalog. It elucidates the available data within a source.
In addition, we will be generating the following files:
source-openweather/secrets/config.json: This configuration file will be employed for testing the connector. Its structure must adhere to the specifications outlined in the spec file.source-openweather/integration_tests/invalid_config.json: An invalid configuration file, which follows the schema defined in the spec file, will also be created for testing purposes.source_openweather/schemas/onecall.json: This file contains the schema definition for the stream we are about to implement. The JSON schema of the API response received.
Starting with the big guns:
manifest.yaml :
This is the file that controls it all. The command center for the connector. It has generally 2 parts:
definitions: This hosts all the details for different components like record selectors, retrievers, and requesters.spec: This section hosts the details configuration required for the integration.
definitions :
There are a few components that are present in the definitions :
record selector: This component allows the connector to define how to retrieve the data. The selector typeRecordSelectorallows us to extract the data from the API response. The definition for the record selector can be found here. Point to note here is that the selector is used to define the path from the data. Say you want a specific part within your API response to be returned instead of all the jargon that is attached to it. We do not want our responses to be too confusing. To make sure we are extracting only the crème de la crème we use a record selectorrequesters: This component is used to prepare HTTP requests to send to the source API. Presently, there exists a sole implementation known as HttpRequester, which is characterized byurl_base: The root of the API sourcehttp_method: the HTTP method to use (GET or POST)A request options provider: Defines the request parameters (query parameters), headers, and request body to set on outgoing HTTP requests
For Openweather we need to send longitude, latitude, and appid as request parameters. For that we used
request_parameters. This option allows the definitions of request parameters that are required.Fun fact: In order to implement conditional selections, one can use Jinja's conditional statements. For Eg: I used the below condition to make sure that the latitude values are always within the range of -90 to 90
lat: "{% if -90.00 <= config['lat']|float <= 90.00 %}{{ config['lat'] }}{% else %} WRONG LATITUDE{% endif %}"
authenticator: Defines how to authenticate to the sourceerror_handler: Defines how to handle errors.
retriever: The data retriever defines how to read the data for a Stream and acts as an orchestrator for the data retrieval flowstream_definitions: This section is used to define the streams that you want to include within your connector. For Openweather, there is only one stream i.e.onecall. In order to define the stream you need to have abase_streamwhich is defined using DeclarativeStream and can be referenced by multiple streams. For myonecall_stream, we have to define the configuration related to the stream here likepath(The specific endpoint to fetch data from for a resource)andname.
There are other sections namely pagination and incremental sync which are not implemented in this connector since this connector does not require them. ( *sigh*)
The definitions section that I used for openweather source:
definitions:
selector:
type: RecordSelector
extractor:
type: DpathExtractor
field_path: []
requester:
type: HttpRequester
url_base: "https://api.openweathermap.org/data/3.0/"
http_method: "GET"
request_parameters:
lat: "{% if -90.00 <= config['lat']|float <= 90.00 %}{{ config['lat'] }}{% else %} WRONG LATITUDE{% endif %}"
lon: "{% if -180.00 <= config['lon']|float <= 180.00 %}{{ config['lon'] }}{% else %}WRONG LONGITUDE{% endif %}"
appid: "{{ config['appid'] }}"
lang: "{{ config.get('lang')}}"
units: "{{ config.get('units')}}"
error_handler:
response_filters:
- http_codes: [ 500 ]
action: RETRY
retriever:
type: SimpleRetriever
record_selector:
$ref: "#/definitions/selector"
paginator:
type: NoPagination
requester:
$ref: "#/definitions/requester"
base_stream:
type: DeclarativeStream
retriever:
$ref: "#/definitions/retriever"
onecall_stream:
$ref: "#/definitions/base_stream"
name: "onecall"
retriever:
$ref: "#/definitions/retriever"
$parameters:
path: "onecall"
spec :
This section is used to define source specification made up of connector metadata and how it can be configured. It hosts details like connection_specification, properties etc.
There are a few components that are present in the spec :
documentation_url: The link to the documentation for the configured sourceconnection_specifications:required: This will define all the properties that are required for integration. All the properties mentioned here can't be skipped and one must define those.properties: This is a list of all the properties. It can host required as well as optional properties.additionalProperties: This is a boolean value that specifies that there might be additional properties apart from what has already been mentioned
This section can be directly copied from the existing spec.json file in the original source connector. Using any available online converter for JSON to YAML, we can get this converted to YAML and directly use that.
The spec section that I used for openweather source:
spec:
type: Spec
documentation_url: https://docs.airbyte.com/integrations/sources/openweather
connection_specification:
title: Openweather Spec
type: object
required:
- lat
- lon
- appid
additionalProperties: true
properties:
lat:
type: string
pattern: "^[-]?\\d{1,2}(\\.\\d+)?$"
description: "Latitude, decimal (-90; 90). If you need the geocoder to automatic convert city names and zip-codes to geo coordinates and the other way around, please use our Geocoding API"
examples:
- "45.7603"
- "-21.249107858038816"
lon:
type: string
pattern: "^[-]?\\d{1,2}(\\.\\d+)?$"
description: "Longitude, decimal (-180; 180). If you need the geocoder to automatic convert city names and zip-codes to geo coordinates and the other way around, please use our Geocoding API"
examples:
- "4.835659"
- "-70.39482074115321"
appid:
type: string
description: "API KEY"
airbyte_secret: true
units:
type: string
description: "Units of measurement. standard, metric and imperial units are available. If you do not use the units parameter, standard units will be applied by default."
enum :
- standard
- metric
- imperial
examples:
- "standard"
- "metric"
- "imperial"
# dt:
# type: string
# description : "Date in UNIX format"
# example:
# - '1693023447'
only_current:
type: boolean
description : "True for particular day"
example:
- 'true'
lang:
type: string
description: You can use lang parameter to get the output in your language.
The contents of the description field will be translated. See <a href="https://openweathermap.org/api/one-call-api#multi">here</a>
for the list of supported languages.
enum:
- af
- al
- ar
- az
- bg
- ca
- cz
- da
- de
- el
- en
- eu
- fa
- fi
- fr
- gl
- he
- hi
- hr
- hu
- id
- it
- ja
- kr
- la
- lt
- mk
- 'no'
- nl
- pl
- pt
- pt_br
- ro
- ru
- sv
- se
- sk
- sl
- sp
- es
- sr
- th
- tr
- ua
- uk
- vi
- zh_cn
- zh_tw
- zu
examples:
- en
- fr
- pt_br
- uk
- zh_cn
- zh_tw
Coming to the essentials
configured_catalog.json
The catalog is used to test the connection as well as read data from the stream.The catalog is structured as a list of AirbyteStream. In the case of a database a "stream" is analogous to a table. This configuration is used to define the properties that aid to the reading of data.
Let's walk through what each field in a stream means.
name- The name of the stream.supported_sync_modes- This field lists the type of data replication that this source supports. The possible values in this array includeFULL_REFRESH(docs) andINCREMENTAL(docs).json_schema- This field is a JsonSchema object that describes the structure of the data. Notice that each key in thepropertiesobject corresponds to a column name in our database table.
configured_catalog for Openweather :
{
"streams": [
{
"stream": {
"name": "onecall",
"json_schema": {},
"supported_sync_modes": ["full_refresh"]
},
"sync_mode": "full_refresh",
"destination_sync_mode": "overwrite"
}
]
}
Once the entries are populated. We need to check if the connection is getting established with the source properly. For that, we would need to run the following command
python main.py check --config secrets/config.json
A successful run would return the below output :

schema.json :
Think of schema files like those trusty old sneakers you've got tucked away in the closet. You only really dig them out when your funky dance moves suddenly become cool again. Since the API we want to use has not changed the API response format. We will use the existing schema file as it is with a minor addition - "additionalProperties": true. This property would allow the addition of extra properties without specific definitions. In case you do not have the schema handy, use ChatGPT to get the API response created in the following format. (This AI is making me lazy LOL! )
Schema I used :
source_openweather/schemas/onecall.json
{
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"additionalProperties": true,
"properties": {
"lat": {
"type": "number"
},
"lon": {
"type": "number"
},
"timezone": {
"type": "string"
},
"timezone_offset": {
"type": "number"
},
"current": {
"type": "object",
"additionalProperties": true,
"properties": {
"dt": {
"type": "number"
},
"sunrise": {
"type": "number"
},
"sunset": {
"type": "number"
},
"temp": {
"type": "number"
},
"feels_like": {
"type": "number"
},
"pressure": {
"type": "number"
},
"humidity": {
"type": "number"
},
"dew_point": {
"type": "number"
},
"uvi": {
"type": "number"
},
"clouds": {
"type": "number"
},
"visibility": {
"type": "number"
},
"wind_speed": {
"type": "number"
},
"wind_deg": {
"type": "number"
},
"weather": {
"type": "array"
},
"rain": {
"type": "object",
"additionalProperties": true,
"properties": {
"1h": {
"type": "number"
}
}
}
}
},
"minutely": {
"type": "array"
},
"hourly": {
"type": "array"
},
"daily": {
"type": "array"
},
"alerts": {
"type": "array"
}
}
}
secrets/config.json:
This file contains the access keys and the required properties that are needed for the connector to function properly. Any values defined here won't be committed to the git as this is a git-ignored file.
config.json for Openweather :
{
"lat": "33.44",
"lon": "-94.04",
"appid": "api-key",
"lang": "fr",
"units": "standard"
}
integration_tests/invalid_config.json:
This file contains invalid properties that are needed for the integration tests.
invalid_config.json for Openweather :
{
"lat": "12.1",
"lon": "-43.1",
"appid": "wrongkey"
}
Now we are done with the basic configurations. It is time to harvest what we have sown. Get ready for the big battle.

Does the connector return data?
To test if we can read the data from the source, we need to define our configured_catalog.json , schema.json and the manifest.yaml. For our purposes, we have already configured them above.
Now to validate the run we need to execute the following command
python main.py read --config secrets/config.json --catalog integration_tests/configured_catalog.json
Here the read operation reads the data from the source and it looks something like this -
"Houston, We have secured connection! I repeat we have a connection! "
Based on the above screenshot we can confirm that the data is being read successfully. If you are facing any issues try to debug or use Kapa - the saviour on Slack.
What's left ???????
Testing the connector

So testing would make you believe in God again, you might find yourself wishing for his return to Earth, hoping that he would assist you in successfully passing the acceptance tests. But then again if everything is in order it would be a smooth ride. To configure tests, you need to update the acceptance-test-config.yml file. This will host the tests you want your connector to pass. Some types of tests are
Test Connection: Verify that a check operation issued to the connector with the input config file returns a successful response
Test Discovery: Verifies when a
discoveroperation is run on the connector using the given config file, a valid catalog is produced by the connectorTest Basic Read: Configuring all streams in the input catalog to full refresh mode verifies that a read operation produces some RECORD messages
You could reuse the original acceptance-test-config.yml from the back. Just make sure the formatting is proper and the tests are valid.
The acceptance-test-config.yml for Openweather:
connector_image: airbyte/source-openweather:dev
acceptance_tests:
connection:
tests:
- config_path: "secrets/config.json"
status: "succeed"
- config_path: "integration_tests/invalid_config.json"
status: "failed"
discovery:
tests:
- config_path: "secrets/config.json"
backward_compatibility_tests_config:
disable_for_version: "0.1.6"
basic_read:
tests:
- config_path: "secrets/config.json"
configured_catalog_path: "integration_tests/configured_catalog.json"
incremental:
bypass_reason: "This connector does not implement incremental sync"
Once you have this configured start with the prayers, I mean with the next steps. Starting with the creation of a docker image for the source. Run the following command in the source root directory
docker build . -t airbyte/source-openweather:dev
Make sure to name your docker image properly. Once this is built successfully, we need to run the test script. There are two ways to run it, either by running it through the docker or through the terminal. To run it through the terminal execute the following command
python -m pytest integration_tests -p integration_tests.acceptance
It should return something of this sorts

Or you could use the docker way. For that, you need to run the following command from the connector root
./acceptance-test-docker.sh
Once you run the code and the tests pass. You could thank the heavens. You have successfully migrated a connector.

Conclusion
With minimal coding experience and a knack for finding ways to cut corners, you have successfully migrated the connector to Low-code CDK. Following this step-by-step guide/tutorial/personal experience, you have learned how to migrate an existing source connector to Low-code. You have learned how to create and configure the manifest.yml file, reuse the existing schema.json file with minor changes and defining the acceptance-test-config.yml .
Places to look for references
Airbyte Docs (holy grail)
Low-Code CDK YAML overview (holy grail version 2)
Special mentions :
Thank you for your help :)
Avinash Gour
bktcodedev
Mikhail Masyagin

Disclaimer: This guide is written by a developer who has tried his hands on the migration for the first time. Please do reach out for suggestions and advice
Subscribe to my newsletter
Read articles from Shivam Agarwal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by