All You Need To Know About Git and GitHub
 Abhinav Pathak
Abhinav Pathak
We need to have some prerequisites before diving into git and git hub and there comes the concept of SCM (Source Code Management).
Source Code Management
Source Code Management (SCM) is the practice of managing and tracking changes to source code during software development. It involves tools and processes that enable developers to collaborate on code, track changes, and ensure that changes are properly integrated into the codebase.
Centralized SCM: This is a type of SCM system that stores code in a central repository on a server. Developers can check out code from the repository, make changes, and then check the code back in. Examples of centralized SCM systems include CVS and Perforce.
Distributed SCM: This is a type of SCM system that combines the benefits of both local and centralized SCM systems. Each developer has a local repository, and changes are synchronized with a central repository. Examples of distributed SCM systems include Git and Mercurial.
Now that we know the root a bit, now we can proceed with git.
Also, SCM version control is a way to manage and document changes developers make to software code. Version control systems (VCS) are also known as source control management (SCM), so the terminology is interchangeable.
Git
Git is a distributed version control system used by millions of developers to manage code and collaborate on software projects. Developed by Linus Torvalds in 2005, Git has quickly become one of the most popular version control systems in the world due to its speed, flexibility, and ease of use. In this blog, we will explore Git and its key features, including how it works, how to use it, and some of its benefits.
What is Git?
Git is a distributed version control system that tracks changes to files and directories over time. It allows multiple users to work on the same codebase simultaneously, without overwriting each other's changes. Git works by creating a repository, which is a collection of files and directories that are managed by Git. Each time a change is made to a file or directory, Git creates a snapshot of the repository called a commit. These commits are stored in a timeline, allowing developers to track the history of changes to the codebase.
What is GitHub?
GitHub is a web-based platform used by developers to host and collaborate. It was launched in 2008 and has quickly become one of the most popular platforms for version control and code collaboration. GitHub allows developers to create and store repositories, manage code changes, and work together with other developers on the same codebase.
With GitHub, developers can easily share their code with others, whether it's an open-source project or a private repository. It also provides tools for code review and collaboration, making it easy for teams to work together on complex software projects. GitHub integrates with other tools like Jenkins and Travis CI, enabling developers to automate their development workflow and improve productivity.
In addition to its core features, GitHub also provides a range of add-ons and plugins that developers can use to extend its functionality. For example, GitHub Pages allow developers to create and host websites directly from their repositories, while GitHub Actions provides a framework for building, testing, and deploying code. Overall, GitHub is an essential tool for developers and teams looking to manage their code and collaborate more effectively.

How does Git work?
Git uses a decentralized approach to version control, meaning that each user has a local copy of the repository on their machine. This allows developers to work offline and make changes to the codebase without the need for a centralized server. When a developer makes changes to the code, they create a new commit, which contains a snapshot of the changes made. These commits can then be pushed to the central repository, where they are merged with the latest version of the codebase.
Git uses a branching system that allows developers to create separate versions of the codebase. Each branch represents a different version of the code, allowing developers to work on different features or fixes without affecting the main codebase. Once changes have been made and tested, they can be merged back into the main branch using a process called a pull request.
Git 3-stage architecture
Git has a 3-stage architecture, which is also known as the Git workflow. This workflow consists of three stages: the working directory, the staging area (or index), and the repository.
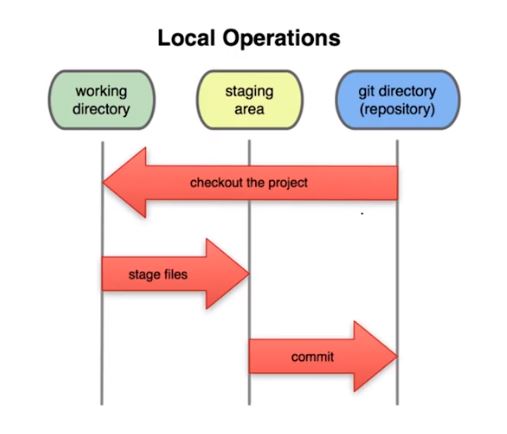
Working Directory: The working directory is the place where developers create, edit, and modify files. When a developer makes changes to a file, Git considers those changes as "untracked" until they are staged. Untracked changes mean that Git is unaware of the changes made when compared to the previous snapshot.
Staging Area: The staging area, is a temporary holding area for changes that will be committed to the repository. When a developer stages changes, Git takes a snapshot of those changes and stores them in the staging area. This allows developers to choose which changes they want to commit to the repository and which ones they want to leave out.
Repository: The repository is the place where all the changes are stored. Once the changes are committed to the repository, they become a permanent part of the codebase. The repository contains a history of all the changes that have been made to the code, including the changes that have been made by other developers. Developers can use Git's version control features to track changes, revert changes, and collaborate on the code with other developers.
In summary, the Git workflow consists of three stages: the working directory, the staging area, and the repository. Developers create and edit files in the working directory, stage changes in the staging area, and commit changes to the repository. This workflow allows developers to collaborate on code, track changes, and manage version control more effectively.
Advantages of Git:
Git has several advantages over other version control systems, including:
Speed: Git is designed to be fast, allowing developers to make changes to the code and push them to the central repository quickly.
Flexibility: Git's branching system allows developers to work on different features or fixes without affecting the main codebase.
Collaboration: Git allows multiple developers to work on the same codebase simultaneously, without overwriting each other's changes
Version control: Git allows developers to track changes to the codebase over time, making it easy to roll back changes if necessary.
Important Terms:
Repository: A repository, or "repo" for short, is a place where all the code and files related to a project are stored. It is a central location that allows developers to share and collaborate on code. Repositories can be public, meaning anyone can view and contribute to them, or private, meaning only approved collaborators have access.
Server: The server is a remote computer where the repository is hosted. It is a place where developers can store and share code, and where changes made by different developers are synchronized. GitHub is an example of a remote server that hosts Git repositories.
Working Directory: The working directory is a local directory on a developer's computer where they make changes to the code. It is where developers can create new files, edit existing files, and make changes to the code.
Commit: A commit is a record of changes made to the repository. It is a way to save changes to the code and make them permanent. When a developer commits changes, Git takes a snapshot of the code at that point in time and stores it in the repository's history.
Commit ID: A commit ID is a unique identifier for a particular commit in the repository's history. It is a long string of characters that allows developers to reference a specific commit in the repository's history. Developers can use the commit ID to compare different versions of the code, track changes, and revert changes if necessary.
Tags: A tag is a label that can be assigned to a specific commit in the repository's history. It is often used to mark significant milestones, such as releases or versions. Tags are useful for keeping track of different versions of the code and making it easier to navigate the repository's history.
Snapshot: A snapshot is a complete copy of the repository at a particular point in time. It includes all the files, folders, and commits in the repository at that moment. Snapshots are useful for creating backups, restoring previous versions of the code, and comparing different versions of the code.
Push: Pushing refers to sending local changes from a developer's computer to the remote repository. It updates the repository with the changes made in the developer's local working directory. Pushing is essential for sharing code and collaborating with other developers.
Pull: Pulling refers to retrieving changes from the remote repository to a developer's local working directory. It updates the local working directory with the changes made by other developers in the remote repository. Pulling is essential for keeping the local working directory up to date and avoiding conflicts when multiple developers are working on the same codebase.
How to use Git?
To use Git, you will need to install it on your machine and create a repository. This can be done using the command line or through a graphical user interface (GUI). Once the repository has been created, you can start making changes to the codebase.
To create a new branch, use the command "git branch ". To switch to the new branch, use the command "git checkout ". You can then make changes to the code and create new commits using the command "git commit -m ''".
Once you have made changes to the code, you can push them to the central repository using the command "git push". If you want to merge changes from a branch back into the main codebase, you will need to create a pull request. This allows other developers to review your changes and provide feedback before the changes are merged into the main codebase.
Basic Git Commands:
git init: Initializes a new Git repository in the current directory.
git add <file_name>: Adds changes to the staging area, preparing them for committing.
git commit -m "<commit message>": Records changes made to the repository, creating a new commit.
git status: Shows the status of the repository, including files that have been modified, added, or deleted.
git log: Displays the commit history of the repository.
git diff: Shows the differences between the working directory and the most recent commit.
git branch: Lists all branches in the repository.
git branch <branch_name>: Adds new branch
git checkout <branch_name>: Switches to a different branch or commit.
git checkout -b <branch_name>: Adds new branch and switches to it simultaneously.
git branch -d <branch_name>: Remove branch from git.
git merge: Merges changes from one branch into another.
git clone: Copies a repository from a remote server to the local machine.
git pull origin <branch_name>: Retrieves changes from the remote repository and applies them to the local repository.
git fetch: Fetches all the remote branches.
git push origin <branch_name>: Sends local changes to the remote repository.
git remote -v: Lists all remote repositories that are connected to the local repository.
git remote add origin <your_remote_git_url>: Add remote repositories.
git remote remove origin: Remove remote repository.
git tag: Creates, lists, or deletes tags in the repository.
git stash: Temporarily stores changes that are not ready to be committed, allowing developers to switch branches or work on other tasks without losing their progress.
git config: Sets configuration options for Git.
git config --global user.name <your_username>
git config --global user.email <your Email>
Branching:
Branching is one of the key features of git which enables developers to work on multiple versions of a project simultaneously, without interfering with each other's work. This article will explore the basics of Git branching and how to use it effectively.
What is Git Branching?
In Git, a branch is a separate line of development that diverges from the main codebase. Each branch can have its own set of changes, commits, and history. By default, when a new Git repository is created, there is only one branch, called the "master" branch. However, developers can create and switch between multiple branches to work on different features or bug fixes.
How to Create a Branch in Git?
To create a new branch in Git, use the "git branch" command followed by the name of the new branch. For example, to create a new branch called "feature-branch", use the following command:
git branch feature-branch
This will create a new branch with the name "feature-branch", but you will still be on the master branch. To switch to the new branch, use the "git checkout" command followed by the name of the branch:
git checkout feature-branch
Now, any changes you make to the codebase will be saved to the "feature-branch" branch and the master branch will be untouched.
How to Merge Branches in Git?
Once you have made changes to a branch and are ready to merge those changes back into the main codebase, you can use the "git merge" command. For example, to merge the "feature-branch" branch back into the master branch, use the following command:
git checkout master
git merge feature-branch
This will merge the changes made in the "feature-branch" branch into the master branch. If there are any conflicts between the two branches, Git will prompt you to resolve them manually.
How to Delete a Branch in Git?
After a branch has been merged into another branch, it is no longer needed and can be safely deleted. To delete a branch in Git, use the "git branch -d" command followed by the name of the branch. For example, to delete the "feature-branch" branch, use the following command:
git branch -d feature-branch
This will delete the branch and its history from the repository.
Merge Conflicts
Sometimes, merging changes from different branches can lead to conflicts. Merge conflicts occur when two or more developers make changes to the same file or lines of code, and Git is unable to automatically determine how to combine those changes.
In a merge conflict, Git will halt the merging process and prompt the user to resolve the conflict manually. When a merge conflict occurs, Git will highlight the conflicting changes in the affected file(s) and prompt the user to choose which changes to keep.
Below are the steps to resolve a merge conflict:
Identify the conflicted file(s): Git will identify the files with conflicts and mark them as "unmerged". Use git status to see which files have conflicts.
Open the conflicted file(s): Open the conflicted file(s) in a text editor to view the conflicting changes.
Locate the conflict markers: Git will insert markers in the file to identify the conflicting changes. These markers look like <<<<<<<, =======, and >>>>>>>. The content between <<<<<<< and ======= represents the changes made in the current branch, while the content between ======= and >>>>>>> represents the changes made in the other branch.
Choose which changes to keep: Review the conflicting changes and decide which changes to keep. Remove the conflict markers and make any necessary modifications to the file.
Add and commit the changes: Once the conflict is resolved, use git add to stage the changes, and git commit to commit the changes to the repository.
It's important to communicate with other developers to prevent merge conflicts from occurring. Pulling changes from the remote repository frequently and resolving conflicts promptly can help minimize the impact of conflicts on a project.
Cherry-Pick:
What is Cherry-Picking?
Cherry-picking is the act of choosing a specific commit from one branch and applying it to another branch. It allows developers to selectively copy changes from one branch to another, without merging entire branches. This can be useful when a developer needs to apply a specific fix or feature from one branch to another, without merging the entire branch and risking conflicts or issues.
How to Use Cherry-Pick?
To cherry-pick a commit, you first need to identify the commit you want to copy. You can do this by using the git log command to view the commit history of the source branch. Once you have identified the commit you want to copy, use the git cherry-pick command followed by the commit hash to apply the commit to the current branch.
Here's an example: Let's say you have two branches, main and feature, and you want to apply a specific commit from the feature branch to the main branch. First, switch to the main branch using the git checkout command. Then, use the git log command to find the commit hash of the specific commit you want to copy. Finally, use the git cherry-pick command followed by the commit hash to apply the commit to the main branch.
git checkout main
git log --oneline feature
abc1234 Fix bug in feature
def5678 Add new feature to feature
git cherry-pick abc1234
This will copy the changes made in the abc1234 commit and apply them to the main branch. You can then use the git status command to verify that the changes have been applied correctly.
Stash and Pop:
Git Stash
Git stash allows developers to save changes that they have made to their working directory but are not yet ready to commit. This is useful when you need to switch branches, but don't want to commit the changes you've made yet. The syntax for git stash is simple:
git stash
This command will save your changes to a stash and revert your working directory to the last committed state. You can also add a message to the stash to make it easier to identify later:
git stash save "My stash message"
To see a list of your stashes, you can use the following command:
git stash list
To apply the most recent stash, you can use the following command:
git stash apply
This will apply the most recent stash to your working directory without deleting it from the stash list. If you have multiple stashes, you can specify which stash to apply using its index:
git stash apply stash@{1}
This will apply to the second stash in the list.
Git Pop
Git pop is a command that retrieves the most recent stash and applies it to your working directory. The syntax for git pop is:
git stash pop
This command is similar to git stash apply, but it also removes the stash from the stash list. If you want to apply a specific stash and remove it from the list, you can use the following command:
git stash pop stash@{1}
This will apply to the second stash in the list and remove it from the list.
Rebase:
Git rebase is a powerful Git command that allows developers to integrate changes from one branch into another by reapplying each individual commit on top of the other branch, rather than merging the entire branch. This can be useful for keeping the Git history clean and easy to understand, and for avoiding the creation of unnecessary merge commits.
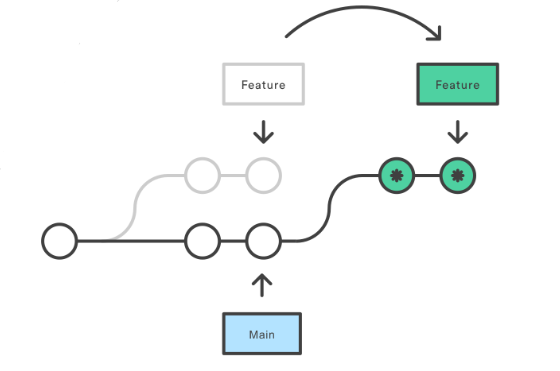
Git Rebase vs. Git Merge:
Before we dive into Git rebase, it's important to understand the difference between Git rebase and Git merge. Git merge creates a new commit that combines the changes from two or more branches, while Git rebase applies each commit from one branch onto another branch in a linear fashion, creating a new commit for each commit from the original branch. In other words, Git merge creates a new "merge commit" that shows the history of both branches, while Git rebase "replays" the commits from one branch onto another branch.
How to Use Git Rebase?
To use Git rebase, first switch to the branch that you want to apply the changes to. For example, if you want to apply changes from branch "feature" to branch "master", first switch to the "master" branch by running the command:
git checkout master
Then, run the command to start the rebase:
git rebase feature
This command will rebase the changes from the "feature" branch onto the "master" branch. Git will apply each commit from the "feature" branch on top of the "master" branch, one by one. If there are any conflicts between the two branches, Git will pause the rebase process and prompt you to resolve the conflicts manually. Once all conflicts are resolved, you can continue the rebase by running the command:
git rebase --continue
Once the rebase is complete, the "master" branch will contain all the changes from the "feature" branch, but with a linear history. This means that instead of a merge commit, Git will create a new commit for each individual commit from the "feature" branch.
When to Use Git Rebase
Git rebase is particularly useful in situations where you want to keep your Git history clean and easy to understand. For example, if you are working on a feature branch and want to integrate it into the main branch, using Git rebase can help to avoid creating a cluttered and confusing history. Instead of having a separate branch with a merge commit, Git rebase will "replay" each commit from the feature branch onto the main branch, resulting in a cleaner and more organized history.
Git Squash:
When you're working on a complex project in Git, it's easy to accumulate a long list of commits, each with a unique message describing a small change. This can make it difficult to keep track of what you've done, and it can be overwhelming when you need to review your work or share it with others. That's where Git squash comes in.
Git squash is a command that allows you to combine multiple commits into a single, more meaningful commit. Instead of having a long list of small, insignificant commits, you can create a single commit that summarizes all the changes you've made. This can make it easier to understand your work, and it can help you avoid cluttering your repository with unnecessary commits.
How to use Git Squash
To use Git Squash, you'll need to follow the below steps:
Step 1: Start by creating a new branch from the branch you want to squash. This will ensure that you don't accidentally overwrite any existing commits.
Step 2: Use the Git rebase command to squash the commits. You can do this by running the following command:
git rebase -i HEAD~n
Replace "n" with the number of commits you want to squash. This will open up an interactive rebase window where you can choose which commits to squash.
Step 3: In the interactive rebase window, change the word "pick" to "squash" for each commit you want to squash. Leave the first commit as "pick".
Step 4: Save and close the interactive rebase window. This will squash the selected commits into a single commit.
Step 5: Use the Git push command to push the changes to the remote repository.
By squashing commits, you can simplify your Git history and make it easier to understand your work. It's also a good practice to follow when working in a team, as it can make it easier for others to review your changes.
However, it's important to note that squashing commits can also make it harder to track down bugs and issues in your code. If you encounter a problem, it may be harder to identify which commit introduced the issue if you've squashed multiple commits into one.
In summary, Git Squash is a useful command for simplifying your Git history and making it easier to understand your work. By combining multiple commits into a single, meaningful commit, you can avoid cluttering your repository with unnecessary commits and make it easier to review your changes. Just be aware that squashing commits can make it harder to track down issues, so use it wisely.
That is all from my end. I would request you to open a terminal and do hands-on to get a feel for each command that you look at.
Also, here is the git cheat sheet for quick revision and handy commands.
Please like this blog if it was able to add value to your knowledge.
I would appreciate your feedback, as it is valuable to me in improving my blog content.
I would love to connect with you on LinkedIn: Abhinav Pathak
Subscribe to my newsletter
Read articles from Abhinav Pathak directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by