Teaching a model to beat Blackjack
 SoJS
SoJS
Reinforcement learning has been a hot topic in the world of artificial intelligence and machine learning for some time now. It's a field that has brought us self-driving cars, advanced game-playing agents, and much more. The real question, however, is can we get a model to learn how to play and beat a popular gambling game, blackjack?
The Rules
Blackjack has very simple rules, and we'll be following only a couple of them. The only actions that we will allow our model to take are hit or stand.
If the agent busts (goes over 21), we will give it a reward of -1.
If it pushes (ties the dealer), we will give it a reward of 0.
If it wins, (beats the dealer, or if the dealer busts), we will give the agent a reward of 1.
The agent will only see what a normal person playing blackjack can see. I am going to assume the majority of people do not know how to count cards, so our agent will not be able to either. All we will be feeding will be the agent's current hand value and the dealer's face-up card.
The Simulation
We will be running 3 simulations, one where the agent learns, one where it tests itself, and one where we choose a random action (for comparison).
The one where the agent learns
To create an agent that learns, we will use the easy-rl class, a library I built so that people can create neural nets that learn in real time in the easiest way possible.
First, we will initialize the model, setting it up with 2 inputs and 2 outputs:
const rn = new RN({numInputs: 2, epsilon: 0.9});
// add layers
rn.addLayer(10, 'sigmoid');
rn.addLayer(10, 'sigmoid');
rn.addLayer(2, 'softmax'); // two outputs
// compile the model
rn.compile();
Then, we just need to set up the simulation. This is relatively easy to do, in fact, I just asked Chat-GPT to generate a blackjack simulation for me, then added the agent into it as a player.
To allow the agent to learn, we need to get the agent action, reward the model based on its action, and then train the model a step.
// initialize the hands
const playerHand = [dealCard(), dealCard()];
const dealerHand = [dealCard(), dealCard()];
// two inputs, hand value and the dealer face up card
const playerState = [handValue(playerHand), dealerHand[0]];
// get the action from the model
let action = await rn.getAction(playerState);
Here, we initialize the hands with the dealCard method (this returns a number from 1-14, then caps it at 10 - this way all face cards have a "value" of ten). Then, we set up the player's state, passing the hand value (this just sums the values of the cards), and the value of the dealer face-up card.
Once we have the model's action, we can then simulate that action (for a look at the code that does this, check out this repl).
Based on the result of the simulation, we can assign that action a reward value.
if (dealerValue > 21 || playerValue > dealerValue) {
await rn.reward(1); // player beats dealer
} else if (playerValue === dealerValue) {
await rn.reward(0); // player pushes
} else {
await rn.reward(-1); // player loses
}
Once that is done, we train the model, using a batchSize of 64. This is not overly important, anything between 32 and 256 should work well.
await rn.next({ batchSize: 64});
After running this ~1000 or so times, we are left with what should be a reasonably good model at playing blackjack. To test this, let's run the second simulation.
The one where the agent tests itself
For the second step of the overall program, we run another blackjack simulation, but this time instead of rewarding the model for wins and losses, we just keep track of them in variables.
if (dealerValue > 21 || playerValue > dealerValue) {
wins++;
} else if (playerValue === dealerValue) {
draws++;
} else {
losses++;
}
Then we just console.log this out, and gather the results! We ran 3 chunks of 1000 rounds to get a truer view of how our model is performing, and here are the results!
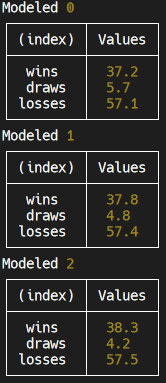
If we combine wins and draws, that's almost a 42% win rate (on average). When we compare this to our random simulation, we find that this is not all that impressive (with random moves you can win ~32% of the time).
It gets even bleaker when we compare this to basic strategy, where you win 49.5% of the time.
Conclusions
Subscribe to my newsletter
Read articles from SoJS directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by