How to curb aggressive parallelism in Microsoft SQL Server
 Josef Richberg
Josef Richberg
Microsoft SQL Server, like most modern database systems, can convert a query into a set of parallel instructions to improve efficiency. This is map-reduce before map-reduce was a popular programming paradigm (think Hadoop). This is done by the optimizer based on numerous information points that the system has access to at runtime. 99% of the time, this is perfectly fine, but when you find that 1% it can be very tricky to solve. In this article, I will show you one technique that I use to solve these edge cases.
This is the query I am working with:
select s.SalesRepName,
m.material as ISBN
from MaterialSalesRepMap m
join SalesHierarchy s on (get_bit(EligibilityKey,Position)=1
and SalesRepName in ('Smith,Joe','Doe,John','Doe,Jane','Lowry,Amanda'))
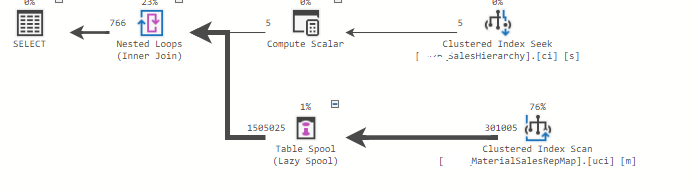
The optimizer chose to parallelize this and we can see it here

One thing to note is that when you make the collection parallel (distribute streams) you then need to funnel those threads back into a controlling thread to output (gather streams).
Statistics (pay attention to the highlighted portion):

It turns out that 2nd worktable grows/shrinks based on the number of reps.
select s.SalesRepName,
m.material as ISBN
from MaterialSalesRepMap m
join SalesHierarchy s on (get_bit(EligibilityKey,Position)=1
and SalesRepName in ('Smith,Joe','Doe,John','Doe,Jane'))

MaterialSalesRepMap
Scan count: NumReps+1
logical reads: 301586*NumReps
The worktable grows by millions for each additional rep. We have 3,998 'rep' entries! It was a this point that I remembered SQL Server (from 2018+) can be 'aggressive' in its choice of how many workers to use when it chooses parallelism.
There is an optimizer hint (maxdop N) which stands for MaxDegreeOfParallelism. This directs the optimizer to use N number of threads when determining how many to use. Rather than guess what would be an optimal number for a query with a varying number of reps in the request, I wanted to see how efficient the system would be without it. So I turned off parallelism by saying (maxdop 1).
select s.SalesRepName,
m.material as ISBN
from MaterialSalesRepMap m
join SalesHierarchy s on (get_bit(EligibilityKey,Position)=1
and SalesRepName in ('Smith,Joe','Doe,John','Doe,Jane','Lowry,Amanda'))
option (maxdop 1)
As you can see this forced the optimizer to ignore any type of parallel processing.
The results were fantastic (and consistent)

The only thing that changes is the underlined blue portion. The Scan Count is equal to the number of reps and the logical reads fluctuates slightly up or down accordingly.
If you are looking to squeeze out some additional performance or look for consistent results this would be one of those specialized tuning approaches that you can take. I have used this approach successfully in selects, inserts, and deletes.
Subscribe to my newsletter
Read articles from Josef Richberg directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Josef Richberg
Josef Richberg
I've been working in and around SQL for over 3 decades. I am currently working on making our business intelligence systems self-driven by using an event-based architecture. This involves providing curated data in some of the largest SQL Azure Analysis Services cubes ever built (over 6 billion records in 1 table alone). I've developed several APIs leveraging a serverless Azure architecture to provide real-time data to various internal processes and projects. Currently working on Project Dormouse; Durable select messaging queue that enables polling processes to extract specific messages.