Beginner's Guide to Kafka: Everything You Need to Know
 Syed Kumail Rizvi
Syed Kumail Rizvi
I will cover the theoretical part of Kafka in this article

"More than 80% of all Fortune 100 companies trust, and use Kafka."
This is the quote you will find on the Apache Kafka official site. According to this Kafka seems to play a crucial role in real-time data pipelining, streaming applications, event-driven architectures, log aggregation, and more.
Now let us see what need does this Kafka serves.
Why We Need It? 🤔🤔
Kafka is a widely used technology in the sector of event-driven architectures and real-time data analytics.
Let us take an example of an Ola app. This app requires some real-time data processing, which includes the sharing of the current location of the cab driver with the customer and simultaneously invoking other services with the produced resource. Considering the number of drivers in North India to be around 2k, for each driver acting as a producer of resource we need to send the location coordinates to the customer and save it in our DB for further analysis.
A producer is not only producing a single resource, there can be multiple resources.
In the case of the driver, we can say it has the following things:-
driver {
name: Abc,
loc: XYZ,
fare: 123
cabNumber: AB-456,
....
}
So, imagine the amount of data that is being inserted or processed per second from the database. The operations per second are going to be very high and it would definitely crash our databases.
Because the databases we use in the industry have very low throughput (operation per second) and hence we need some software that can handle these large numbers of operations. Here Kafka comes to the rescue.
So does this mean that Kafka is a replacement for the existing DB? 🤔
The answer is 'No' because there are some pros and cons to each and everything.
This is not a replacement instead, it is used as a plug with our DBs.
Kafka has a high throughput which means that it can handle a large number of operations per second in a better manner. But it has a low storage capacity which means that it cannot store our resource data for too long, which can be achieved with the help of DB.
Let us see a basic Diagram:-

It shows that there is a producer connected to Kafka which has some topics and those topics are used by consumers. Although topics are not shown in the figure, you will get to know about them later in the article.
How Kafka Solves Our Problem ❓❔
Now we know that Kafka has a high throughput but low storage capacity, this feature of Kafka helps in real-time data monitoring and many other operations.
Let us take an example of a Zomato App:-
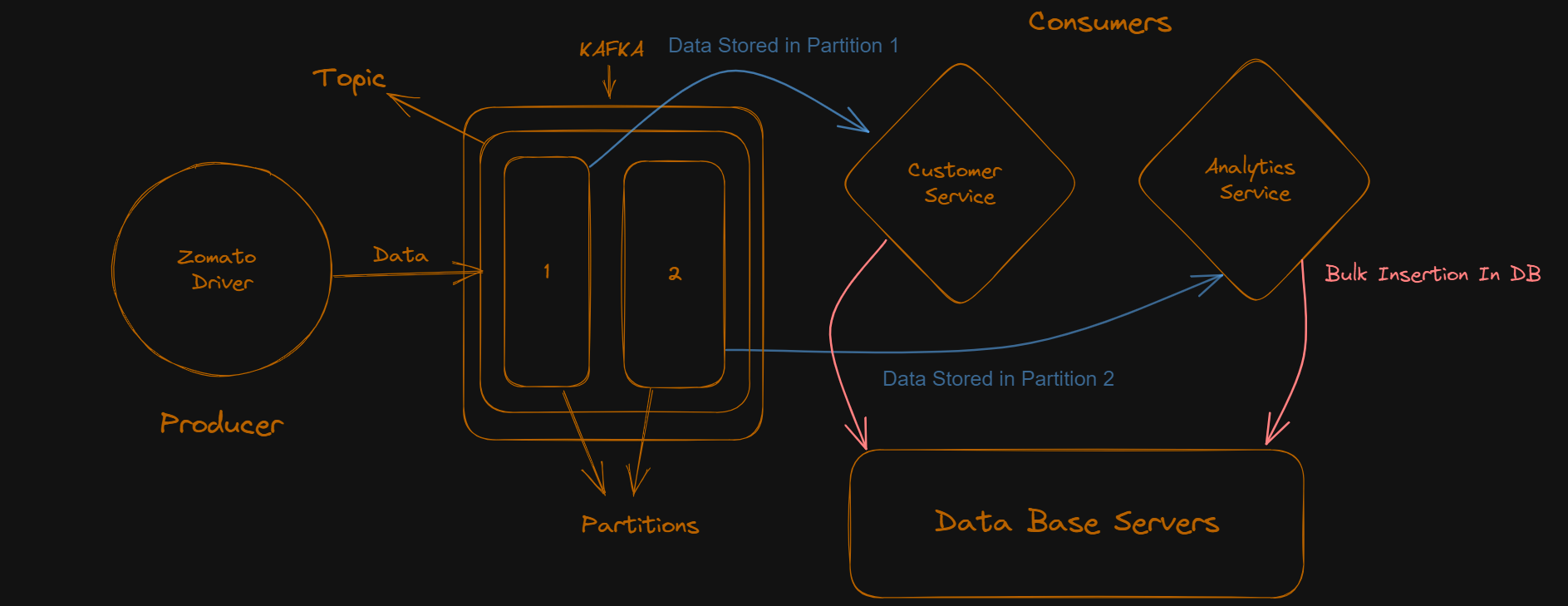
In the above figure, we can clearly see that the delivery person is the producer and that the data produced is being transferred to Kafka topics which are further divided into partitions, and each partition is connected to a consumer, The consumers will process the data received from the partitions and in one single transaction they will store the data in database. In this way, we can handle millions of operations per second and our system is not going to crash.

Developers to Kafka 👆👆
Note:- One partition can be connected to only one consumer. However, one consumer may have connections with multiple partitions from different topics.
Using Kafka makes our system more fault-tolerant and scalable, thus this product is used much in the industry.
Terminology 🔖🔖
Pub/Sub Architecture:- The publish-subscribe architecture of Kafka means that the producer publishes the data to Kafka topics, and the consumer subscribes to the topics to receive data. Kafka says that it follows both the Pub/Sub architecture and the Queue architecture (using Consumer Groups).
Topics:- This term is going to be used a lot in Kafka and it is the key element of Kafka. Topics are logs where data is published. They can be big or small it does not affect Kafka at all. Producers are responsible for writing those logs data in Topics and consumers are there to read that data.
Partitions:- Each topic can be divided into several partitions, that allow data to be distributed and processed in parallel thus increasing the throughput and scalability.
Brokers: In the Kafka cluster the individual servers are known as brokers. Kafka is a distributed system and brokers are individual nodes in the cluster. Each broker may store data for one or more number of partitions.
Producers:- They are responsible for publishing the data or we can say inserting the data into Kafka topics. They push data to Kafka brokers which then distribute it to the appropriate topic partitions.
Consumers:- Consumers are there to read the data from the subscribed topic. They can subscribe to multiple topics and process the data in real time. Kafka allows both consumer groups for parallel processing and individual consumers.
Streams:- Kafka Streams is a stream processing library that allows developers to build real-time applications and microservices that process data from Kafka topics.
These are some terms that we will come across while dealing with Kafka so it is advisable to go through them and gain some knowledge about them.
Although, all these terms require a separate article to be explained in more detail, by going through the above details you will get an overview of the Kafka architecture and its functionality.
Now, you might be wondering how to include this Kafka in our projects, I'll be bringing that up ASAP. Stay connected!
Subscribe to my newsletter
Read articles from Syed Kumail Rizvi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Syed Kumail Rizvi
Syed Kumail Rizvi
Learner | Student | Trainee | Interested In Tech related stuff. | Writes about JS, Java, Node, Spring, ORM. |