A Beginner's Introduction to Apache Kafka
 Hemant
Hemant
Apache Kafka is a system that helps transfer data in real-time. It is commonly used in modern applications where events play a crucial role. For example, when a customer places an order on a website, the order service needs to inform other services about the order's status. This is done by generating an event that triggers actions in other services. Apache Kafka acts as a messaging system that receives data from source systems and sends it to target systems.
Kafka is a distributed system that consists of servers and clients communicating through a high-performance TCP network protocol. It is an open-source system created by LinkedIn and is maintained by companies like LinkedIn, Confluent, IBM, and others. Many well-known companies, including LinkedIn, Airbnb, and Netflix, use Kafka for their data transfer needs.
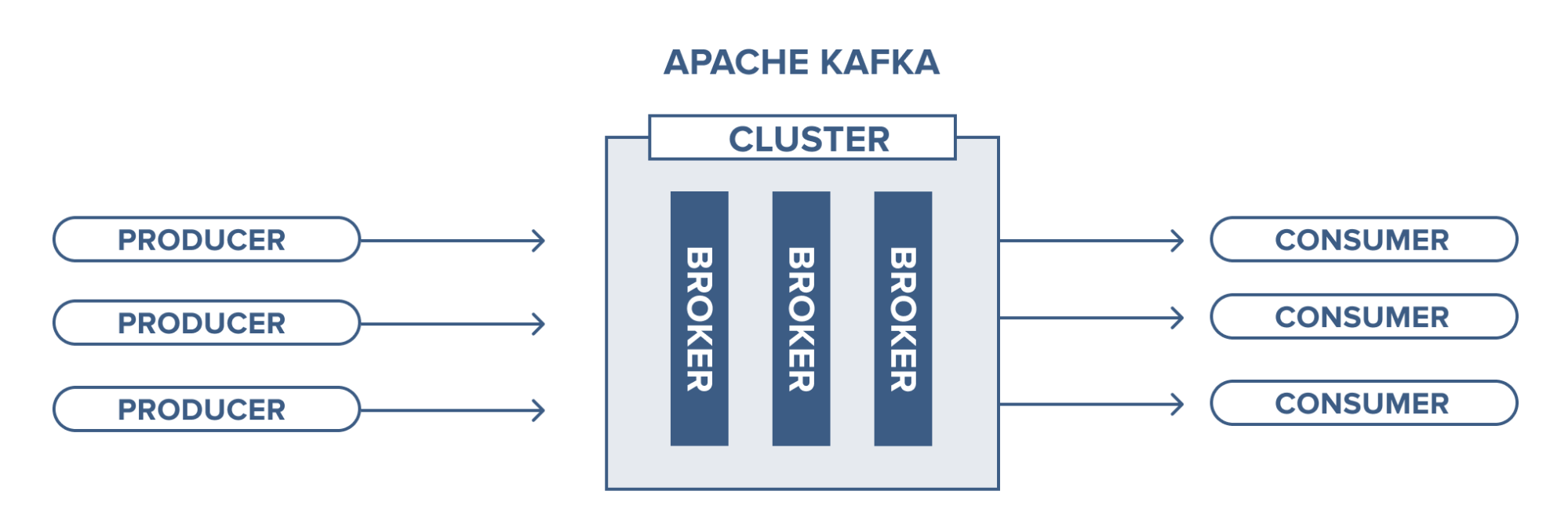
Why should we use Apache Kafka?
Distributed Streaming System: Apache Kafka is a messaging system that consists of multiple servers working together. These servers form a cluster and can be set up anywhere as needed.
Fault Tolerant System: Kafka uses replication to ensure fault tolerance. Data is replicated across all servers, so if one node fails, data can still be processed from other nodes.
Scalability: Kafka is highly scalable. It allows for fast and automatic recovery in case of node failure. You can increase the number of brokers and consumers to handle high loads and increasing demand.
High Performance: Kafka is efficient in handling a large volume of data. It can process millions of messages per second with high throughput and low latency.
Kafka Architecture
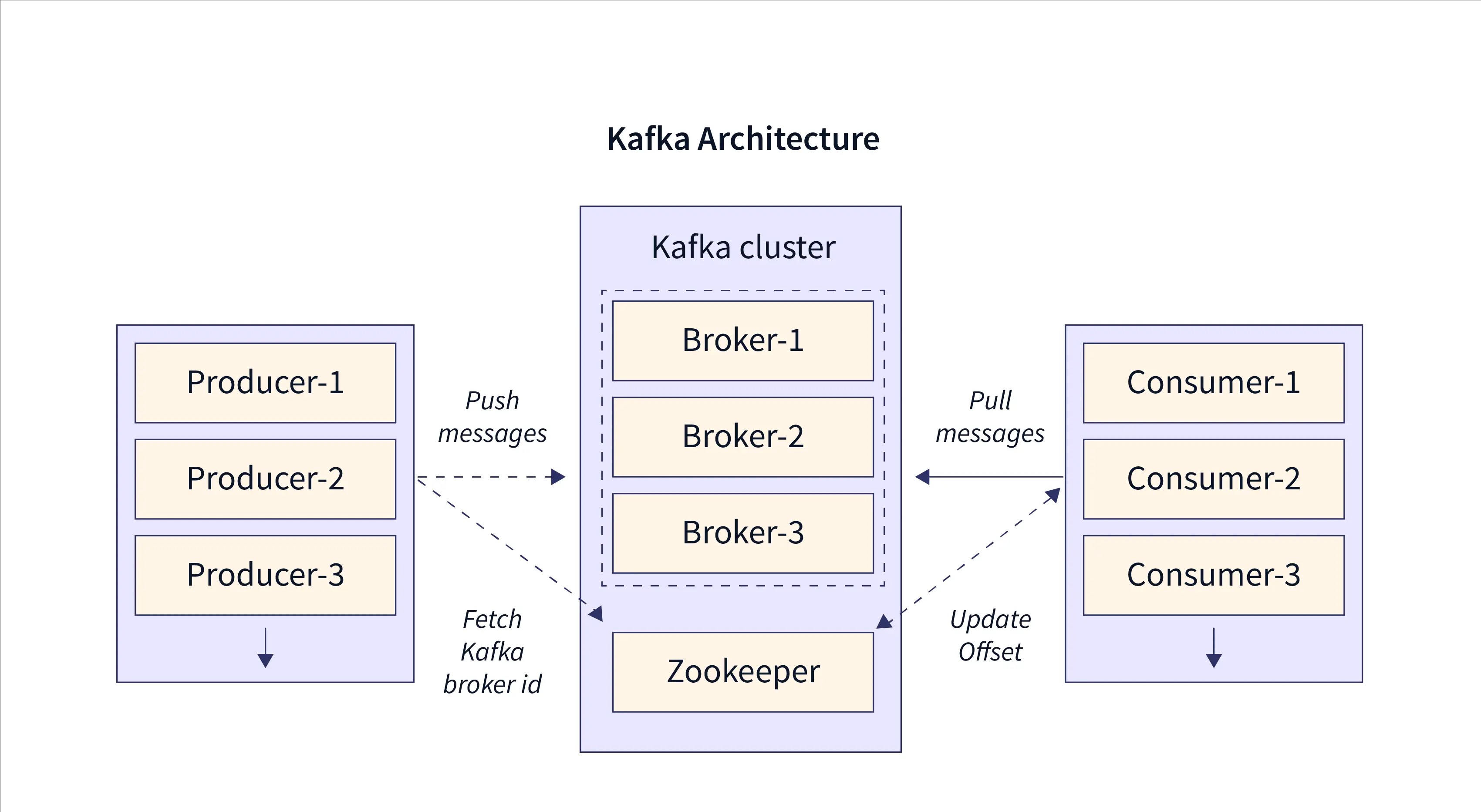
The picture above explains how Kafka is set up. Now, let's talk about each part of the Kafka diagram in simple terms.
Kafka Cluster:
A Kafka cluster is a group of Kafka brokers. Think of a broker as a server that sends and receives data. In Kafka, brokers are called brokers because they handle data. Each broker in the cluster has a unique ID.
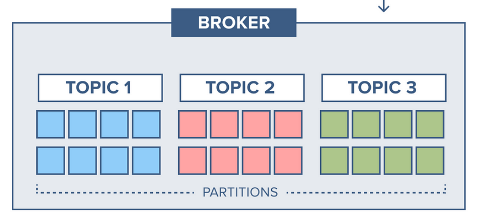
Kafka Broker:
Brokers in Kafka have different topics. A topic is like a stream of data in the Kafka cluster. Each topic is divided into partitions. Topics are identified by their names. The partitions of a topic are spread evenly across the brokers in the cluster, which helps Kafka handle large amounts of data. Brokers are responsible for copying data to different partitions. Each broker in the Kafka cluster has all the information about the entire cluster. Brokers receive messages from producers and store them on disk. A Kafka broker is also called a bootstrap server.
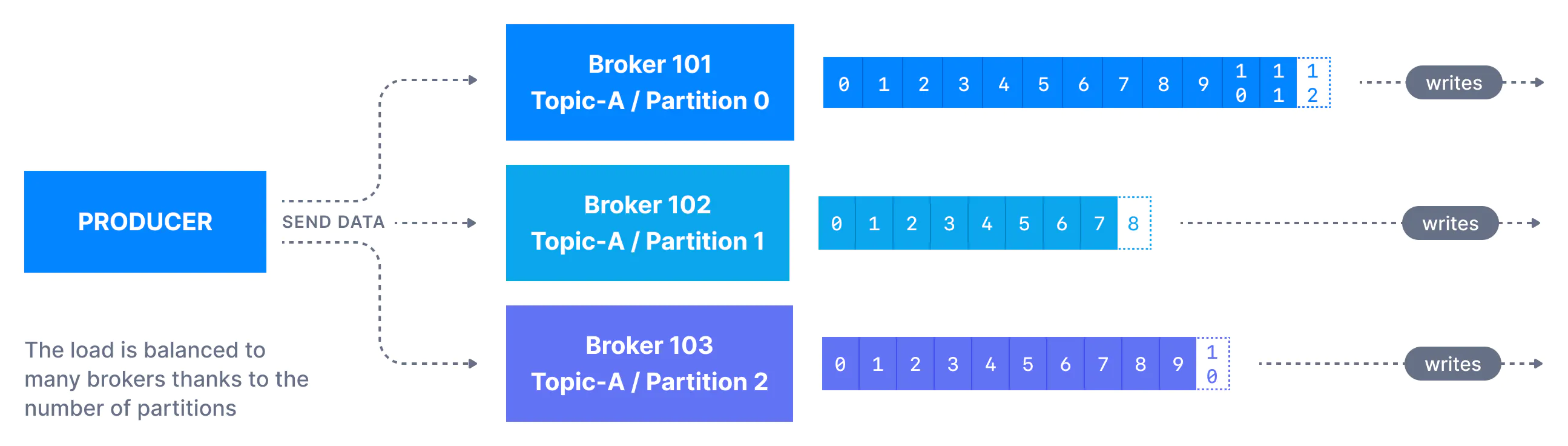
Producers:
In the Kafka system, there are several producers that send data to Kafka topics. Producers are smart and can determine which partitions to write data to. If a Kafka server with a partition fails, the producers can recover automatically. Before sending messages to Kafka topics, producers use message serializers to convert the messages into a suitable format.
In Kafka, data is sent and received as bytes. Producers convert the data into bytes before sending it to Kafka, and consumers receive the data as bytes. This byte-based communication allows Kafka to handle different types of data effectively and ensures that producers and consumers can work together seamlessly.
Consumers:
Consumers in Kafka are responsible for reading messages from Kafka topics. They use a pull model to retrieve data from specific partitions within a topic. Consumers are organized into consumer groups, and each group can have multiple consumers reading data from a topic.
When reading data, a consumer starts from a lower offset and reads messages in order up to a higher offset within a partition. However, if a consumer is reading from multiple partitions, the order of messages is not guaranteed. Kafka sends data to consumers in the form of bytes. To make the data usable, consumers use message deserializers to convert the bytes back into their original object format.
ZooKeeper:
In the Kafka ecosystem, there is another important component called ZooKeeper. ZooKeeper is responsible for managing the metadata of the Kafka system. It helps Kafka by informing producers and consumers about the addition or removal of Kafka brokers in the cluster. Additionally, Kafka brokers rely on ZooKeeper to determine the leader of each partition. In summary, ZooKeeper plays a crucial role in coordinating and maintaining the overall stability and functionality of the Kafka system.
Kafka with Node.js:
Prerequisites:
Node.JS Intermediate level
Experience with designing distributed systems
Node.js: Download Node.JS
Docker: Download Docker
VsCode: Download VSCode
Refer this gist for the code and all commands which we are going to use!
Start ZooKeeper: Kafka uses ZooKeeper for coordination, so you need to start ZooKeeper before starting Kafka. ZooKeeper manages the configuration, synchronization, and leader election for Kafka.
- Start Zookeper Container and expose PORT
2181.
$ docker run -p 2181:2181 zookeeper
ZooKeeper JMX enabled by default
Using config: /conf/zoo.cfg
2023-09-08 16:07:19,761 [myid:] - INFO [main:o.a.z.s.q.QuorumPeerConfig@177] - Reading configuration from: /conf/zoo.cfg
2023-09-08 16:07:19,769 [myid:] - INFO [main:o.a.z.s.q.QuorumPeerConfig@431] - clientPort is not set
2023-09-08 16:07:19,769 [myid:] - INFO [main:o.a.z.s.q.QuorumPeerConfig@444] - secureClientPort is not set
2023-09-08 16:07:19,770 [myid:] - INFO [main:o.a.z.s.q.QuorumPeerConfig@460] - observerMasterPort is not set
2023-09-08 16:07:19,770 [myid:] - INFO [main:o.a.z.s.q.QuorumPeerConfig@477] - metricsProvider.className is org.apache.zookeeper.metrics.impl.DefaultMetricsProvider
2023-09-08 16:07:19,793 [myid:] - ERROR [main:o.a.z.s.q.QuorumPeerConfig@702] - Invalid configuration, only one server specified (ignoring)
2023-09-08 16:07:19,799 [myid:1] - INFO [main:o.a.z.s.DatadirCleanupManager@78] - autopurge.snapRetainCount set to 3
2023-09-08 16:07:19,799 [myid:1] - INFO [main:o.a.z.s.DatadirCleanupManager@79] - autopurge.purgeInterval set to 0
2023-09-08 16:07:19,799 [myid:1] - INFO [main:o.a.z.s.DatadirCleanupManager@101] - Purge task is not scheduled.
2023-09-08 16:07:19,799 [myid:1] - WARN [main:o.a.z.s.q.QuorumPeerMain@139] - Either no config or no quorum defined in config, running in standalone mode
2023-09-08 16:07:19,805 [myid:1] - INFO [main:o.a.z.j.ManagedUtil@46] - Log4j 1.2 jmx support not found; jmx disabled.
2023-09-08 16:07:19,808 [myid:1] - INFO [main:o.a.z.s.q.QuorumPeerConfig@177] - Reading configuration from: /conf/zoo.cfg
2023-09-08 16:07:19,811 [myid:1] - INFO [main:o.a.z.s.q.QuorumPeerConfig@431] - clientPort is not set
2023-09-08 16:07:19,811 [myid:1] - INFO [main:o.a.z.s.q.QuorumPeerConfig@444] - secureClientPort is not set
2023-09-08 16:07:19,811 [myid:1] - INFO [main:o.a.z.s.q.QuorumPeerConfig@460] - observerMasterPort is not set
2023-09-08 16:07:19,811 [myid:1] - INFO [main:o.a.z.s.q.QuorumPeerConfig@477] - metricsProvider.className is org.apache.zookeeper.metrics.impl.DefaultMetricsProvider
2023-09-08 16:07:19,811 [myid:1] - ERROR [main:o.a.z.s.q.QuorumPeerConfig@702] - Invalid configuration, only one server specified (ignoring)
2023-09-08 16:07:19,812 [myid:1] - INFO [main:o.a.z.s.ZooKeeperServerMain@123] - Starting server
2023-09-08 16:07:19,849 [myid:1] - INFO [main:o.a.z.s.ServerMetrics@64] - ServerMetrics initialized with provider org.apache.zookeeper.metrics.impl.DefaultMetricsProvider@4218d6a3
2023-09-08 16:07:19,861 [myid:1] - INFO [main:o.a.z.s.a.DigestAuthenticationProvider@51] - ACL digest algorithm is: SHA1
2023-09-08 16:07:19,862 [myid:1] - INFO [main:o.a.z.s.a.DigestAuthenticationProvider@65] - zookeeper.DigestAuthenticationProvider.enabled = true
2023-09-08 16:07:19,877 [myid:1] - INFO [main:o.a.z.s.p.FileTxnSnapLog@124] - zookeeper.snapshot.trust.empty : false
2023-09-08 16:07:19,922 [myid:1] - INFO [main:o.a.z.ZookeeperBanner@42] -
2023-09-08 16:07:19,922 [myid:1] - INFO [main:o.a.z.ZookeeperBanner@42] - ______ _
2023-09-08 16:07:19,922 [myid:1] - INFO [main:o.a.z.ZookeeperBanner@42] - |___ / | |
2023-09-08 16:07:19,922 [myid:1] - INFO [main:o.a.z.ZookeeperBanner@42] - / / ___ ___ | | __ ___ ___ _ __ ___ _ __
2023-09-08 16:07:19,922 [myid:1] - INFO [main:o.a.z.ZookeeperBanner@42] - / / / _ \ / _ \ | |/ / / _ \ / _ \ | '_ \ / _ \ | '__|
2023-09-08 16:07:19,922 [myid:1] - INFO [main:o.a.z.ZookeeperBanner@42] - / /__ | (_) | | (_) | | < | __/ | __/ | |_) | | __/ | |
2023-09-08 16:07:19,922 [myid:1] - INFO [main:o.a.z.ZookeeperBanner@42] - /_____| \___/ \___/ |_|\_\ \___| \___| | .__/ \___| |_|
2023-09-08 16:07:19,923 [myid:1] - INFO [main:o.a.z.ZookeeperBanner@42] -
| |
2023-09-08 16:07:19,923 [myid:1] - INFO [main:o.a.z.ZookeeperBanner@42] -
|_|
Start Kafka: Once ZooKeeper is up and running, you can start Kafka. Kafka consists of multiple components, including brokers, topics, producers, and consumers.
- Start Kafka Container, expose PORT
9092and setup ENV variables.
$ docker run -p 9092:9092 \
-e KAFKA_ZOOKEEPER_CONNECT=<PRIVATE_IP>:2181 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://<PRIVATE_IP>:9092 \
-e KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 \
confluentinc/cp-kafka
PRIVATE_IP is the unique address assigned to your computer on the local network. You can find this address by running the ipconfig command in the terminal or command prompt.
Let's move on to the code part:
Now open up your sample folder in your code editor.
Initializing a node.js app with
yarn initand press enter for all the default settings.Install
kafkajsas your dependency.
npm install kafkajs
Now create a client.js file in the root directory of your app and pase the below code:
const { Kafka } = require("kafkajs");
exports.kafka = new Kafka({
clientId: "my-app",
brokers: ["<YOUR_PRIVATE_IP>:9092"],
});
Create a Topic: Topics are the core abstraction in Kafka. They represent a particular stream of records. You can create a topic using the Kafka command-line tools or programmatically using the Kafka API.
Create a admin.js file and paste the below code:
const { kafka } = require("./client");
async function init() {
const admin = kafka.admin();
console.log("Admin connecting...");
admin.connect();
console.log("Adming Connection Success...");
console.log("Creating Topic [rider-updates]");
await admin.createTopics({
topics: [
{
topic: "rider-updates",
numPartitions: 2,
},
],
});
console.log("Topic Created Success [rider-updates]");
console.log("Disconnecting Admin..");
await admin.disconnect();
}
init();
Produce Messages: Producers are responsible for publishing messages to Kafka topics. You can create a producer application that sends messages to a specific topic. Messages can be in any format, such as JSON, Avro, or plain text.
Create a producer.js file and paste the below code:
const { kafka } = require("./client");
const readline = require("readline");
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
async function init() {
const producer = kafka.producer();
console.log("Connecting Producer");
await producer.connect();
console.log("Producer Connected Successfully");
rl.setPrompt("> ");
rl.prompt();
rl.on("line", async function (line) {
const [riderName, location] = line.split(" ");
await producer.send({
topic: "rider-updates",
messages: [
{
partition: location.toLowerCase() === "north" ? 0 : 1,
key: "location-update",
value: JSON.stringify({ name: riderName, location }),
},
],
});
}).on("close", async () => {
await producer.disconnect();
});
}
init();
Consume Messages: Consumers read messages from Kafka topics. You can create a consumer application that subscribes to a topic and processes the incoming messages. Consumers can be single-threaded or multi-threaded, depending on your requirements.
Create a consumer.js file and paste the below code:
const { kafka } = require("./client");
const group = process.argv[2];
async function init() {
const consumer = kafka.consumer({ groupId: group });
await consumer.connect();
await consumer.subscribe({ topics: ["rider-updates"], fromBeginning: true });
await consumer.run({
eachMessage: async ({ topic, partition, message, heartbeat, pause }) => {
console.log(
`${group}: [${topic}]: PART:${partition}:`,
message.value.toString()
);
},
});
}
init();
Now let's try running our code:
- Run the
admin.jsfile first.
$ node .\admin.js
Admin connecting...
Adming Connection Success...
Creating Topic [rider-updates]
Topic Created Success [rider-updates]
Disconnecting Admin..
- Let's try producing messages by running
producer.jsfile.
$ node .\producer.js
{"level":"WARN","timestamp":"2023-09-08T16:27:32.852Z","logger":"kafkajs","message":"KafkaJS v2.0.0 switched default partitioner. To retain the same partitioning behavior as in previous versions, create the producer with the option \"createPartitioner: Partitioners.LegacyPartitioner\". See the migration guide at https://kafka.js.org/docs/migration-guide-v2.0.0#producer-new-default-partitioner for details. Silence this warning by setting the environment variable \"KAFKAJS_NO_PARTITIONER_WARNING=1\""}
Connecting Producer
Producer Connected Successfully
> tom south
> jerry north
- Now let's see if we can get our produced messages or not by running
consumer.jsfile.
$ node consumer.js user-1
{"level":"INFO","timestamp":"2023-09-08T16:29:58.307Z","logger":"kafkajs","message":"[Consumer] Starting","groupId":"user-1"}
{"level":"ERROR","timestamp":"2023-09-08T16:29:58.415Z","logger":"kafkajs","message":"[Connection] Response GroupCoordinator(key: 10, version: 2)","broker":"192.168.0.101:9092","clientId":"my-app","error":"The group coordinator is not available","correlationId":2,"size":55}
{"level":"ERROR","timestamp":"2023-09-08T16:29:58.936Z","logger":"kafkajs","message":"[Connection] Response GroupCoordinator(key: 10, version: 2)","broker":"192.168.0.101:9092","clientId":"my-app","error":"The group coordinator is not available","correlationId":3,"size":55}
{"level":"ERROR","timestamp":"2023-09-08T16:29:59.634Z","logger":"kafkajs","message":"[Connection] Response GroupCoordinator(key: 10, version: 2)","broker":"192.168.0.101:9092","clientId":"my-app","error":"The group coordinator is not available","correlationId":4,"size":55}
{"level":"INFO","timestamp":"2023-09-08T16:30:04.361Z","logger":"kafkajs","message":"[ConsumerGroup] Consumer has joined the group","groupId":"user-1","memberId":"my-app-a98b5172-1bd0-4602-b0ed-7d02b25ef2ee","leaderId":"my-app-a98b5172-1bd0-4602-b0ed-7d02b25ef2ee","isLeader":true,"memberAssignment":{"rider-updates":[0,1]},"groupProtocol":"RoundRobinAssigner","duration":6051}
user-1: [rider-updates]: PART:1: {"name":"tom","location":"south"}
user-1: [rider-updates]: PART:0: {"name":"jerry","location":"north"}
Congratulations!
We're successfully getting the produced messages as consumers!
If you want to understand Kafka in more detail then go and check their docs.
Also, you can check out this awesome video by Piyush Garg about Kafka with an easy explanation!!
Subscribe to my newsletter
Read articles from Hemant directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Hemant
Hemant
My passion for creating beautiful websites led me to become a fellow frontend developer