Google Dorking
 Akbar Khan
Akbar Khan
What is a Google Dork?
Google Dorking is also known as “Google hacking.”
Google Dorking or Google hacking refers to using Google search techniques to hack into vulnerable sites or search for information that is not available in public search results. The Google search engine works similarly to an interpreter using search strings and operators. For example, you can say that Google reacts sensitively to certain search strings when applied with specific operators. However, you will learn more about it later in the tutorial on ‘What is Google Dorking’.

Only use this information for legal purposes.
Google dork cheatsheet


Operators
Search Term
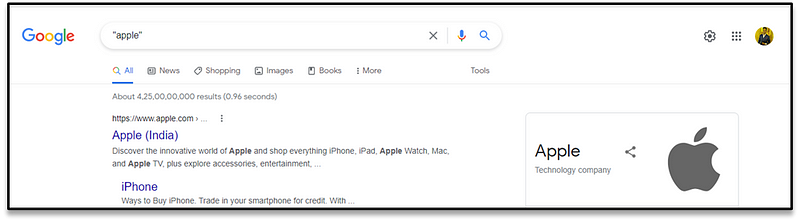
This operator searches for the exact phrase within speech marks only. This is ideal when the phrase you are using to search is ambiguous and could be easily confused with something else, or when you’re not quite getting relevant enough results back. For example:
I was willing to search for a fruit “apple” but what I got as a result. not a wrong one but just confusing.
OR
This self-explanatory operator searches for a given search term OR an equivalent term.
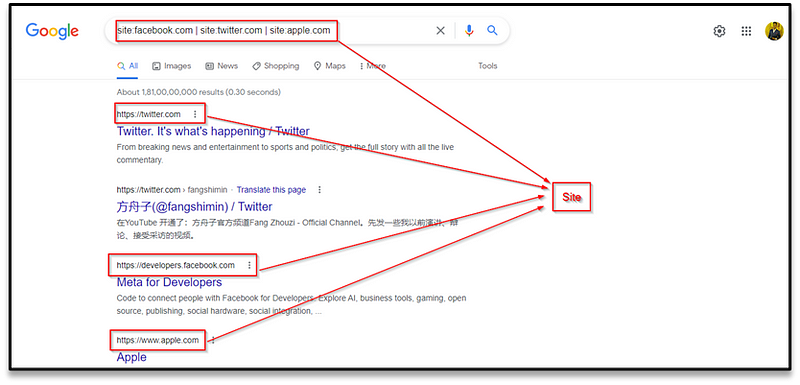
Syntax
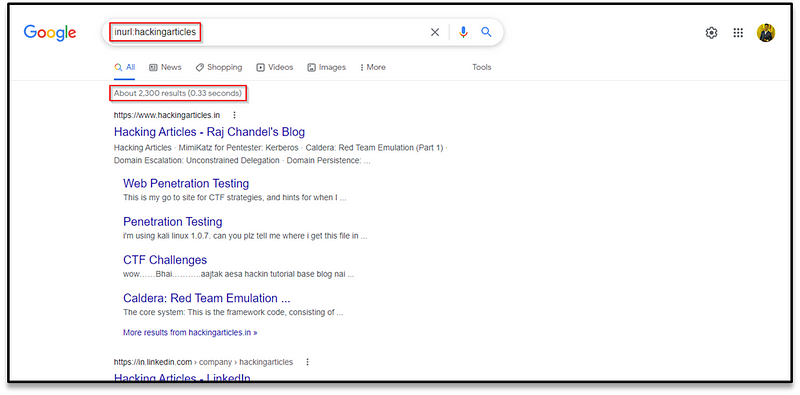
inurl
Filtered result using inurl syntax
site and file type
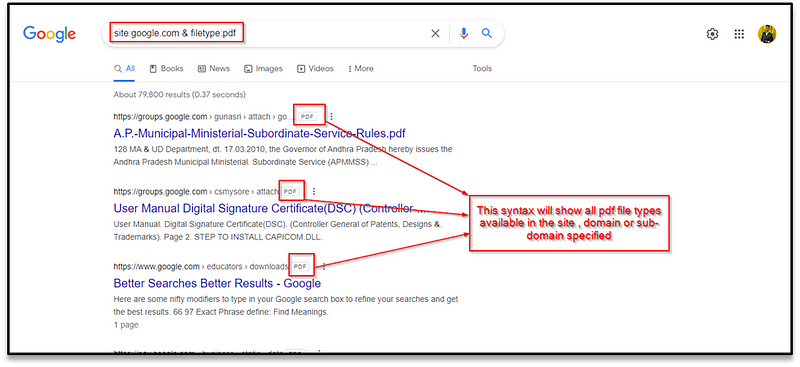
intitle: login page
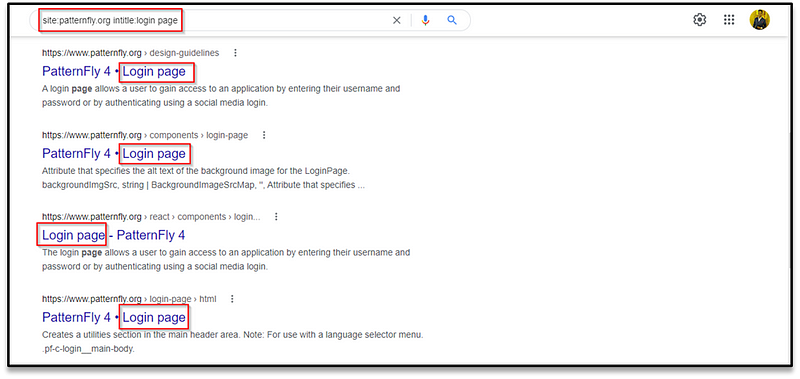
**site:**patternfly.org **intitle:**login page
Search Engine Optimisation
Search Engine Optimisation or SEO is a prevalent and lucrative topic in modern-day search engines. So much so, that entire businesses capitalize on improving a domain's SEO “ranking”. From an abstract view, search engines will “prioritize” those domains that are easier to index. There are many factors in how “optimal” a domain is — resulting in something similar to a point-scoring system.
To highlight a few influences on how these points are scored, factors such as:
• How responsive your website is to the different browser types I.e. Google Chrome, Firefox and Internet Explorer — this includes Mobile phones!
• How easy it is to crawl your website (or if crawling is even allowed …but we’ll come to this later) through the use of “Sitemaps”
• What kind of keywords your website has (i.e. In our examples if the user was to search for a query like “Colours” no domain will be returned — as the search engine has not (yet) crawled a domain that has any keywords to do with “Colours”
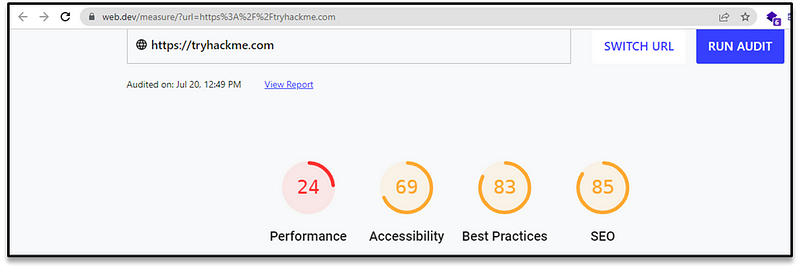
There are various online tools — sometimes provided by the search engine providers themselves that will show you just how optimized your domain is. For example, let’s use Google’s Site Analyser to check the rating of a website :
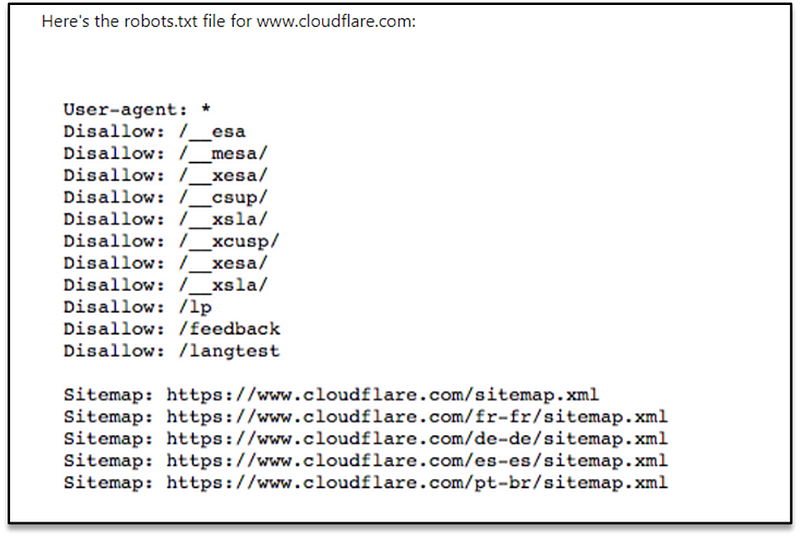
robots.txt
A robots.txt file tells search engine crawlers which URLs the crawler can access on your site. This is used mainly to avoid overloading your site with requests; it is not a mechanism for keeping a web page out of Google. To keep a web page out of Google, block indexing with no index or password-protect the page.
Robots.txt files are mostly intended for managing the activities of good bots like web crawlers, since bad bots aren’t likely to follow the instructions.
A bot is an automated computer program that interacts with websites and applications. There are good bots and bad bots, and one type of good bot is called a web crawler bot. These bots “crawl” webpages and index the content so that it can show up in search engine results. A robots.txt file helps manage the activities of these web crawlers so that they don’t overtax the web server hosting the website, or index pages that aren’t meant for public view.
Example of a robots.txt file
What is a user agent? What does ‘User-agent: *’ mean?
Any person or program active on the Internet will have a “user agent,” or an assigned name. For human users, this includes information like the browser type and the operating system version but no personal information; it helps websites show content that’s compatible with the user’s system. For bots, the user agent (theoretically) helps website administrators know what kind of bots are crawling the site.
In the example above, Cloudflare has included “User-agent: *” in the robots.txt file. The asterisk represents a “wild card” user agent, and it means the instructions apply to every bot, not any specific bot.
How do ‘Disallow’ commands work in a robots.txt file?
The Disallow command is the most common in the robot exclusion protocol. It tells bots not to access the webpage or set of web pages that come after the command. Disallowed pages aren’t necessarily “hidden” — they just aren’t useful for the average Google or Bing user, so they aren’t shown to them. Most of the time, a user on the website can still navigate to these pages if they know where to find them.
How to Allow full access?
Such a command would look as follows:
Disallow:
This tells bots that they can browse the entire website because nothing is disallowed.
Hide the entire website from bots
Disallow: /
The “/” here represents the “root” in a website’s hierarchy, or the page that all the other pages branch out from, so it includes the homepage and all the pages linked from it. With this command, search engine bots can’t crawl the website at all.
In other words, a single slash can eliminate a whole website from the searchable Internet!
What is the Sitemaps protocol? Why is it included in robots.txt?
The Sitemaps protocol helps bots know what to include in their crawling of a website.
A sitemap is an XML file that looks like this:
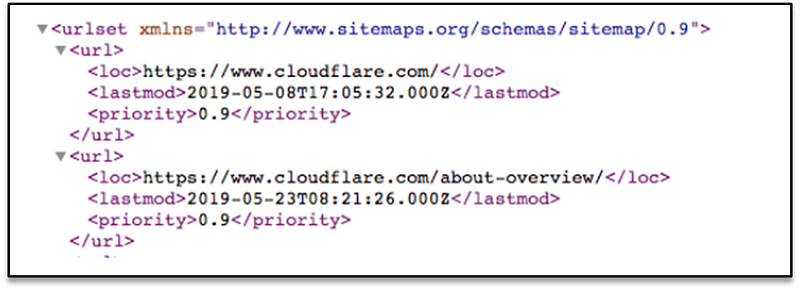
It’s a machine-readable list of all the pages on a website. Via the Sitemaps protocol, links to these sitemaps can be included in the robots.txt file. The format is: “Sitemaps:” followed by the web address of the XML file. You can see several examples in the Cloudflare robots.txt file above.
While the Sitemaps protocol helps ensure that web spider bots don’t miss anything as they crawl a website, the bots will still follow their typical crawling process. Sitemaps don’t force crawler bots to prioritize webpages differently.
References
https://www.techtarget.com/whatis/definition/Google-dork-query
https://www.simplilearn.com/tutorials/cyber-security-tutorial/google-dorking
https://en.wikipedia.org/wiki/Google_hacking
https://www.hackthebox.com/blog/What-Is-Google-Dorking
https://www.techopedia.com/definition/30938/google-dorking
https://gist.github.com/sundowndev/283efaddbcf896ab405488330d1bbc06
https://www.cloudflare.com/en-in/learning/bots/what-is-robots.txt/
Subscribe to my newsletter
Read articles from Akbar Khan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Akbar Khan
Akbar Khan
Experienced Information Technology Professional | eLearn Security Certified Professional Penetration Tester (eCPPTv2) With 5 years of hands-on experience in the Information Technology and cybersecurity domains, I have developed a comprehensive skill set in Linux, Windows OS / Windows Server, and ethical hacking. My expertise extends to system security fundamentals such as Public Key Infrastructure (PKI), cryptography, and encryption/decryption algorithms.