Get Going: peek into slice
 Weiping LarryD
Weiping LarryD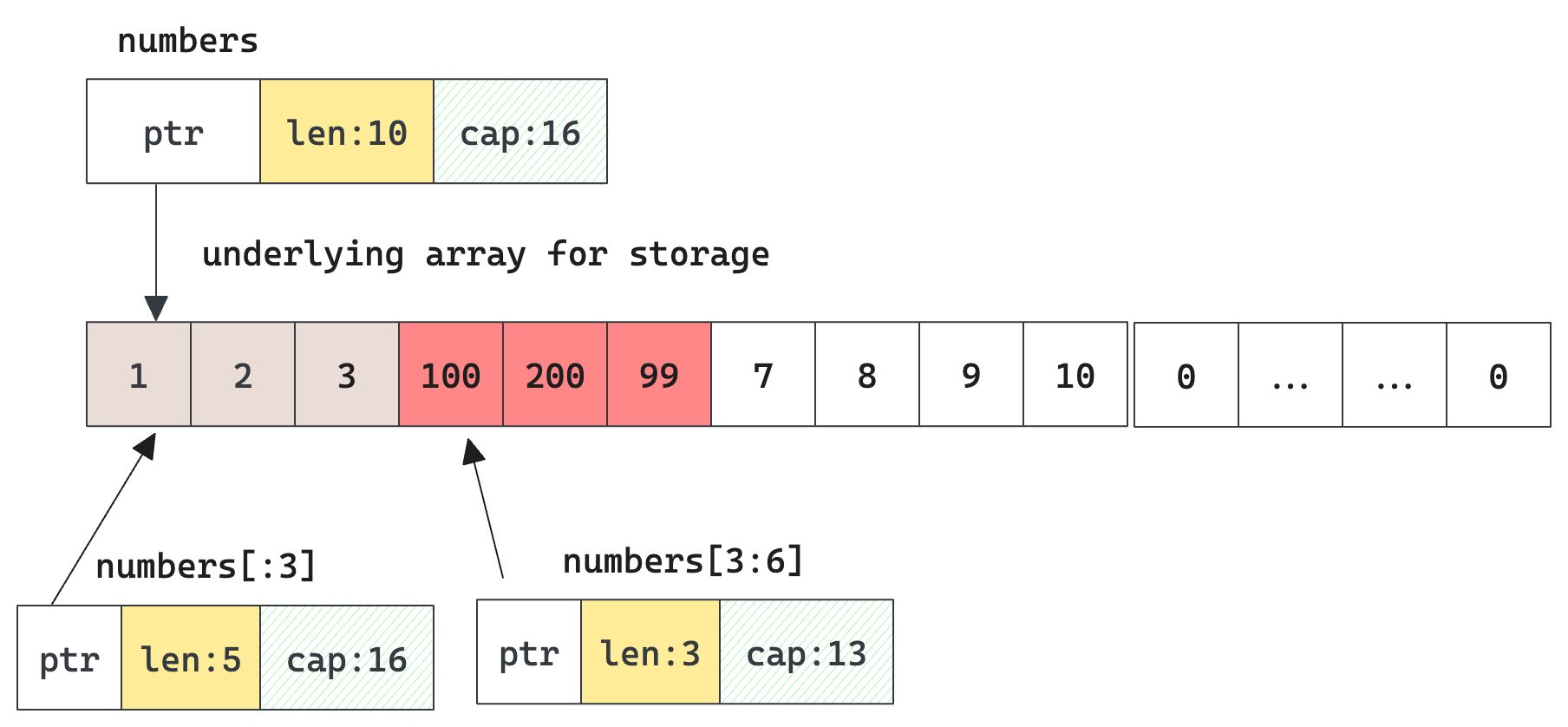
In previous posts, I explored the unique design of Go error handling. This time I am moving to another part: Go slice. Similar to error handling, this data structure (essentially dynamic array) is something so common (JavaScript array, Python list etc.), but Go has its unique behaviors. I find it is essential to build the right mental model to slice internal structure, so we can better reason about the outcome of operations and know exactly how to use it properly. Let's dig in.
Slice data structure
In short, slice is a lightweight struct (also known as slice header) that describes the underlying array. As in Go slice blog, you can think of its definition as below:
type sliceHeader struct {
Length int,
Capacity: int,
ZerothElementPtr // pointer to first element in underlying array
}
Underneath it use array type as backing storage. It's a building block of slice type. As array need to be declared with a fixed size, but in real it's often a dynamic list of things. That's why we almost always work on slice type instead of array in the practical program.
Here you can find a succinct explanation about the meaning of len and cap from this blog, we can see more in the following sections.
The
lengthis the upper bound for indexing operationsx[len-1]or the number of loops when iterating the slice.while the capacity is the upper bound for slice operations like
x[i:cap].
Next we will look into some common use cases on slice to understand how slice header utilizes the backing array.
Append to slice
Append is similar to what JavaScript Array.push does. The difference here in Go is append operation always returns a new slice. You need to assign the returned value to the initial passed in slice after the call in order to keep appending to the original slice. In fact, the compiler won’t let you call append without saving the result.
This can be a bit confusing initially. But again we know slice is just like a simple descriptor (with len, cap and a pointer) instead of underlying array. So what append does is to take a descriptor and return a new descriptor to the current status of underlying array.
Using some little nice trick from Closer-look-at-go-slice-append, we can inspect how slice changes over the iteration.
var numbers []int
for i := 0; i < 10; i++ {
// need to assign the returned slice back to original one
// complier won't allow if no left hand variable to assign
numbers = append(numbers, i)
fmt.Printf("len: %d, cap: %d, first addr: %p, \n", len(numbers), cap(numbers), numbers)
}
Notice the use of %p format to print the address. The printed result:

We can see every append returns a new slice header struct, with updated len . But the underlying array may be shared (pay attention to addresses in the highlighted rectangle box):
So if there is still room to append (len <= cap), cap and first element address won't change. Otherwise cap is increased, allocating a larger block of memory for the new array. All existing elements are then copied over, and the new element is appended to the new array. In this case all 3 fields in slice header are updated.
Slicing on slice
Let's do some slicing on the previous numbers , how will numbers, nums1, nums2 look like this time?
var numbers []int
for i := 0; i < 10; i++ {
numbers = append(numbers, i)
}
nums1 := numbers[:3]
nums2 := numbers[3:6]
Another trick to tinker with some address arithmetic, we can print slice address and each element address in the slice.
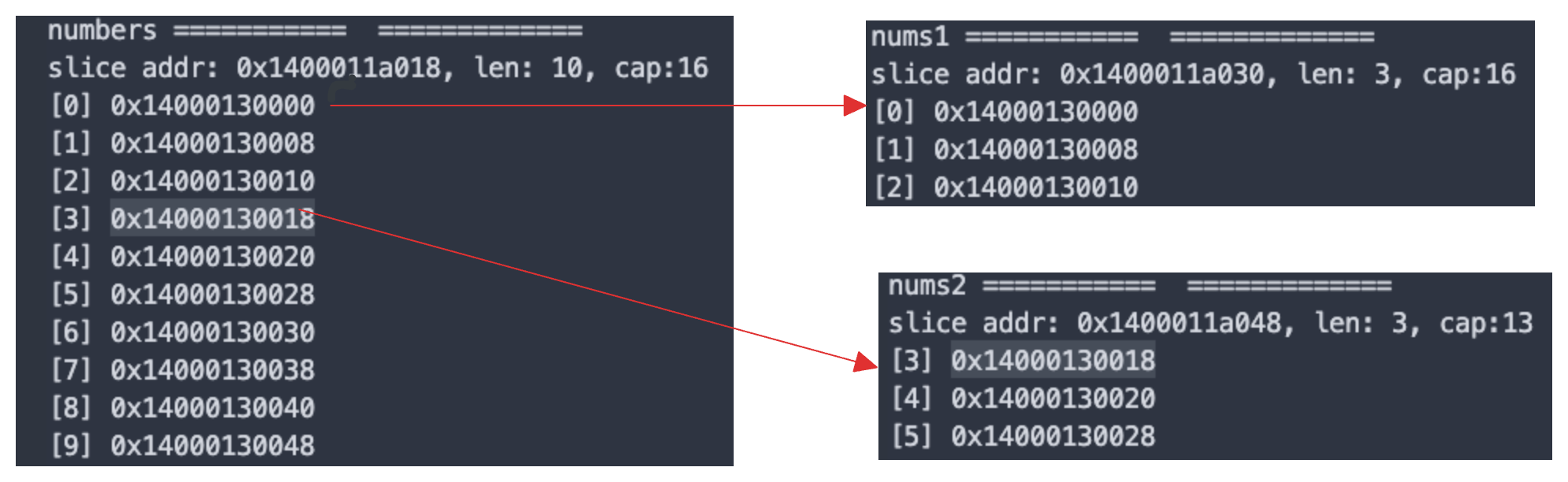
We can see when performing slice operation using the syntax: s[start:end] (end is exclusive), it does not allocate a new array, and copy data. Instead it returns a new slice that describes a portion of the original underlying array. It means all these sub-slices share the same underlying array. As shown above, that's why nums1 has 3 elements, each of the addresses is the same as the original numbers slice. Same case for nums2 slice.
This is important. So we know when mutating any of the sub-slices, the original slice also gets mutated.
To draw a more intuitive illustration:
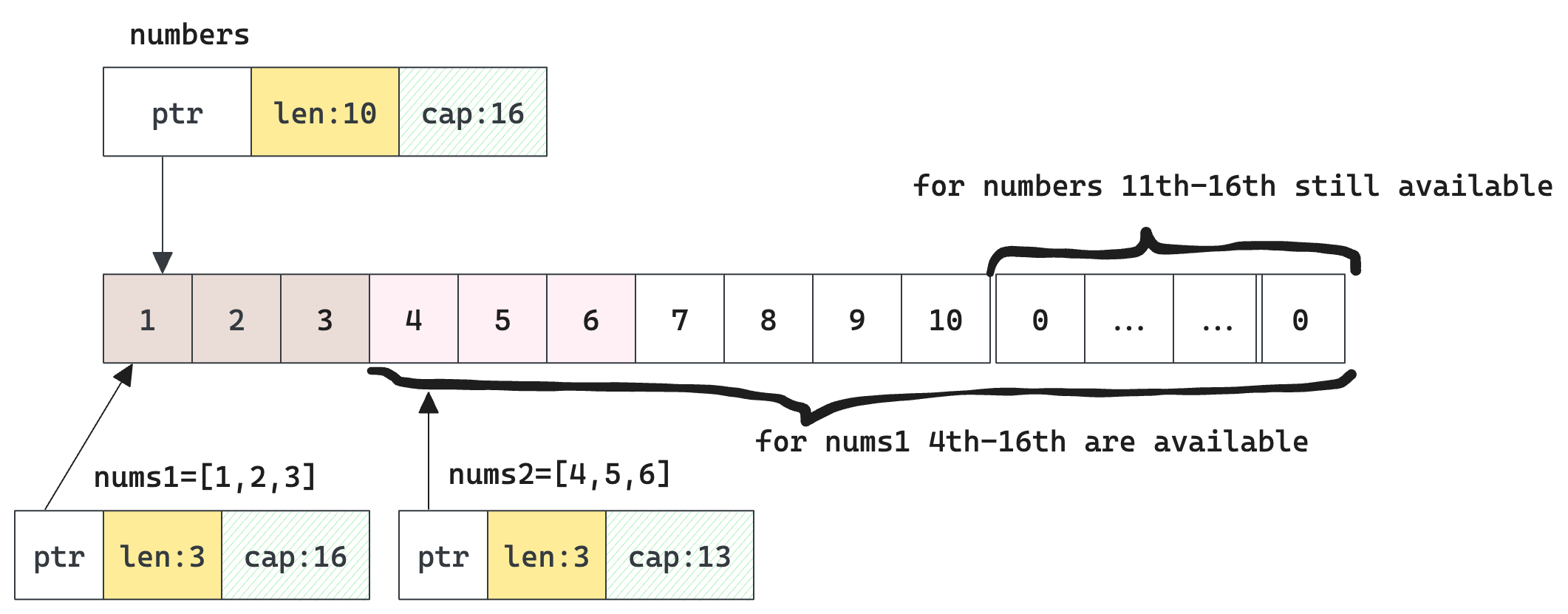
Note: because the capacity is increased to 16, the available slots are filled with default value 0 for []int. These are "seats" available to be filled.
As discussed before, len is the upper bound for indexing. After slicing, we can only access 3 elements in nums1 and nums2 even though they all have extra capacity to host more elements in the same underlying array. So nums1[5] or nums[4] will give an error.
what happens if we mutate nums2[2] = 99 ? Because it's the same array, numbers[5] will become 99 as well. (the third of nums2 is the sixth of the original numbers)
what happens if we append 2 elements: nums1 = append(nums1, 100, 200)? Because it still has room for nums1 len < cap, 100 and 200 are appended right after the last element of nums1 , which is nums1[2]. Because it's the same array both numbers and nums2 will be affected after this append.
An illustration after these mutations, red slots are those affected.
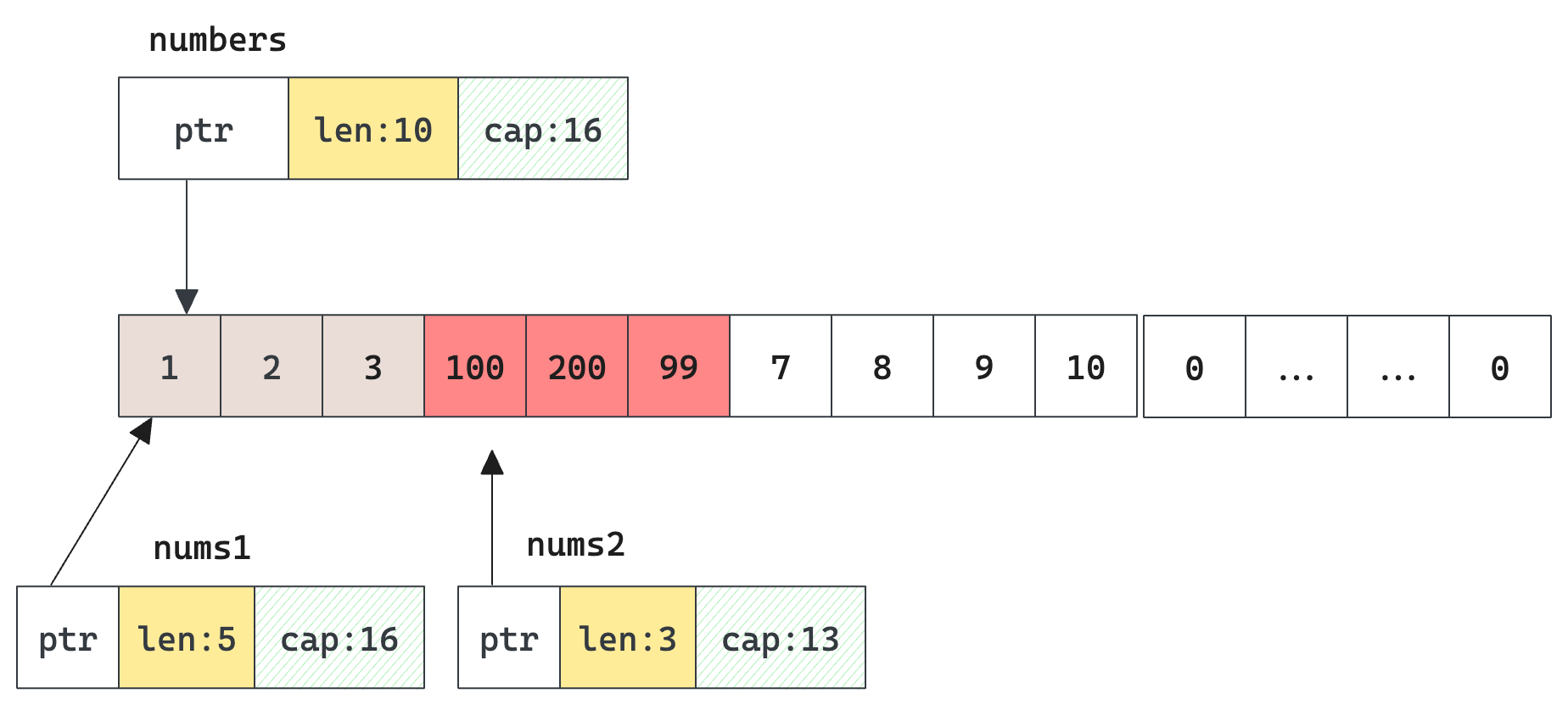
From this perspective, I feel slicing is more like a read-only struct that is bound to a portion of data in the underlying array, indexing and iteration can only work on this boundary, ignoring other existing elements.
References
https://go.dev/blog/slices
https://go.dev/blog/slices-intro
https://research.swtch.com/godata
Subscribe to my newsletter
Read articles from Weiping LarryD directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by