Batch Processing
 Donald Chinhuru
Donald Chinhuru
Originally published on my LinkedIn profile
Batch Processing. Part 1
Is a method systems use to periodically complete high-volume, repetitive data jobs which are usually computer-intensive and inefficient to run on individual data transactions. To achieve this, systems usually process such tasks in batches, often off-peak, as background tasks end of the day or overnight, for example, e-commerce orders, financial salary processing, bulk email notifications etc.
Why batch processing
Systems in organizations use batch processing because it requires minimum human interaction, and process large quantity of data in chunks which makes repetitive tasks more efficient to run. Such common tasks where batch processing is used include:
timely interval billing e.g. weekly/daily
data conversion, e.g from an Excel file to a database
financial e.g. payroll, EOD transaction processing
report generation
PoC: Payroll disbursement module for an ERP System
As a Proof Of Concept to demonstrate batch processing, imagine being given a task to implement batch processing service for a Payroll module in an ERP System. To achieve this, we will assume the batch file is a comma-separated list of records in a .txt file.
user-account-number, amount
500008747831, 5000
500008747832, 7500
500008747833, 100500
Project Setup
Technologies used
Java Spring Boot
Spring Batch
Spring JPA
Postgres SQL
Docker
IntelliJ IDEA
I will assume some knowledge of Java Spring and Data JPA. To tackle this, we will use Java SpringBoot with Spring Batch, a lightweight, comprehensive batch framework for robust batch applications for enterprise systems. It provides reusable functions that are essential in processing large volumes of records with other out-of-box components like job restarting, logging, resource management and chunk-based processing which we will use in this example.
Concept
A typical batch program generally:
Reads a large number of records from a database, file, or queue.
Processes the data in some fashion.
Writes back data in a modified form.
Spring Batch automates this basic batch iteration, providing the capability to process similar transactions as a set, typically in an offline environment without any user interaction. Batch jobs are part of most IT projects, and Spring Batch is the only open-source framework that provides a robust, enterprise-scale solution.
In Spring Batch, a batch process is typically encapsulated by a Job consisting of multiple Steps. Each step has a single ItemReader, ItemProcessor and ItemWriter. A Job is executed by a JobLauncher and metadata about configured and executed jobs are stored in a JobRepository. Each Job may be associated with multiple JobInstances, each defined uniquely by its particular JobParameters which will be used in this example. Each JobInstance is referred to as a JobExecution which tracks what happened during a run such as the job statuses which we will be using to know the batch status.
A Step is an independent, specific phase of a batch Job, such that every Job is composed of one or more Steps. The step has an individual StepExecution is similar to a Job's JobExecution that represents a single attempt to execute a Step. It stores similar information as a JobExecution as well as references to its corresponding Step and JobExecution instances.
JobRepository is a persistence mechanism that makes all this possible. It provides CRUD operations for JobLauncher, Job and Step implementations. When a Job is first launched, a JobExecution is obtained from the repository. Also, during execution, StepExecution and JobExecution implementations are persisted by passing them to the repository.
Getting Started
One advantage of Spring Batch is that of minimal dependencies, which makes it easy to get up and running quickly. To speed up setting up our development environment we will use docker to set the database, will use PostgreSQL in docker. The docker-compose.yaml file and project source code used is available on the link at the end of this post. To keep the article short, will use small snippets and shots of important concepts 🙂.
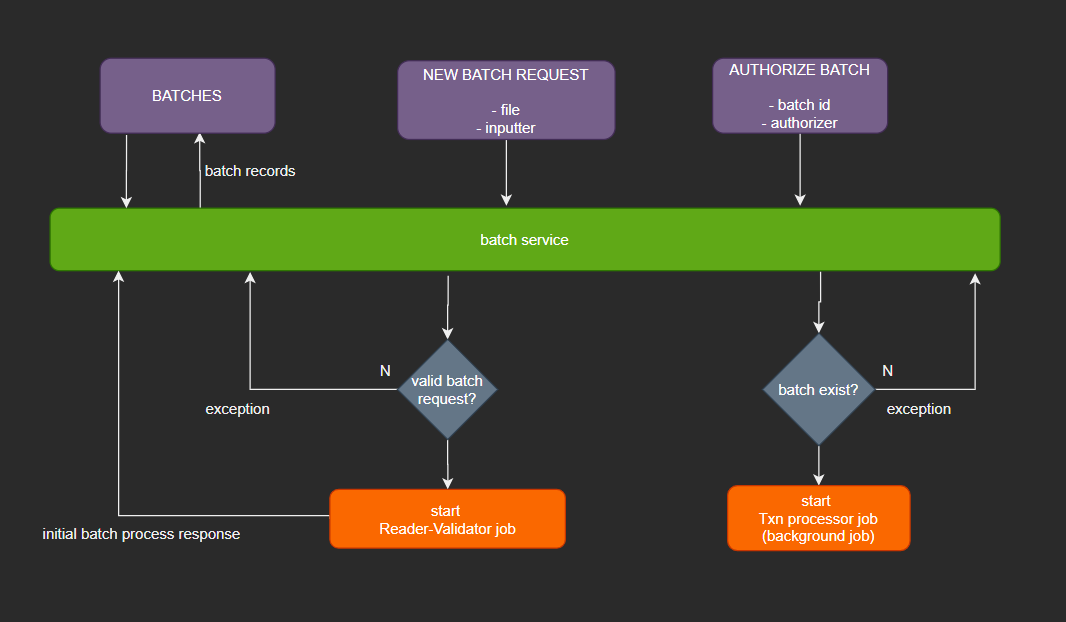
Our process flow will be as above, we will implement 2 Batch Jobs:
- Reader-Validator Job - which will read, parse and validate the uploaded batch file after it has been verified (checked for duplicates & any other initial batch request parameters to validate like the inputter). It reads data from a comma-separated .txt batch file and writes each entry to our Postgres database awaiting authorization.
What if the batch file has invalid entries in it? 🤔 We can't trust user input after all without validating it. This job will implement this logic. We can either throw an Exception when we encounter an invalid entry. This has some drawbacks on user experience, imagine a batch with 1000+ entries and returning an exception on every invalid entry. If the system encounters 200 invalid entries, that means the user will retry the batch 200 times 😲.
For a workaround this, how about we process all the found valid entries and write only invalid entries to another temporary file for the user to fix and reupload later, this is what the Reader-Validator Job will be doing for us.
- Transaction (Txn) Processor Job - after the uploaded batch is authorized, this job kicks in to do the actual transaction processing, it connects to a transaction engine/service/adapter whatever service handles the actual transaction process. After the request, it updates the same batch record with the process result which will be used later when batch records are fetched. It uses JPA Reader to read from the Postgres database, process the record (transaction, payment processing) and write back to the database to update the record.
Since a batch may contain a lot of entries, the Txn processor job will be run in the background and in chunks to improve performance. Because Spring Batch is highly flexible, we can add a listener to notify a particular user when this batch completes processing with its batch completion status.
Batch File IO
We can't talk about batch without mentioning File I/O. Some kind of validation checking is necessary to make sure we don't process the same file, this will be catastrophic in financial or medical organizations, imagine duplicating a financial transaction to the same user. To avoid this, we will use duplicate finding techniques, for this demonstration we use simple file hashing comparison. We hash the uploaded file and check if the same file name or hash has been processed, if so, we raise an Exception, or else we start our validator job in real-time.
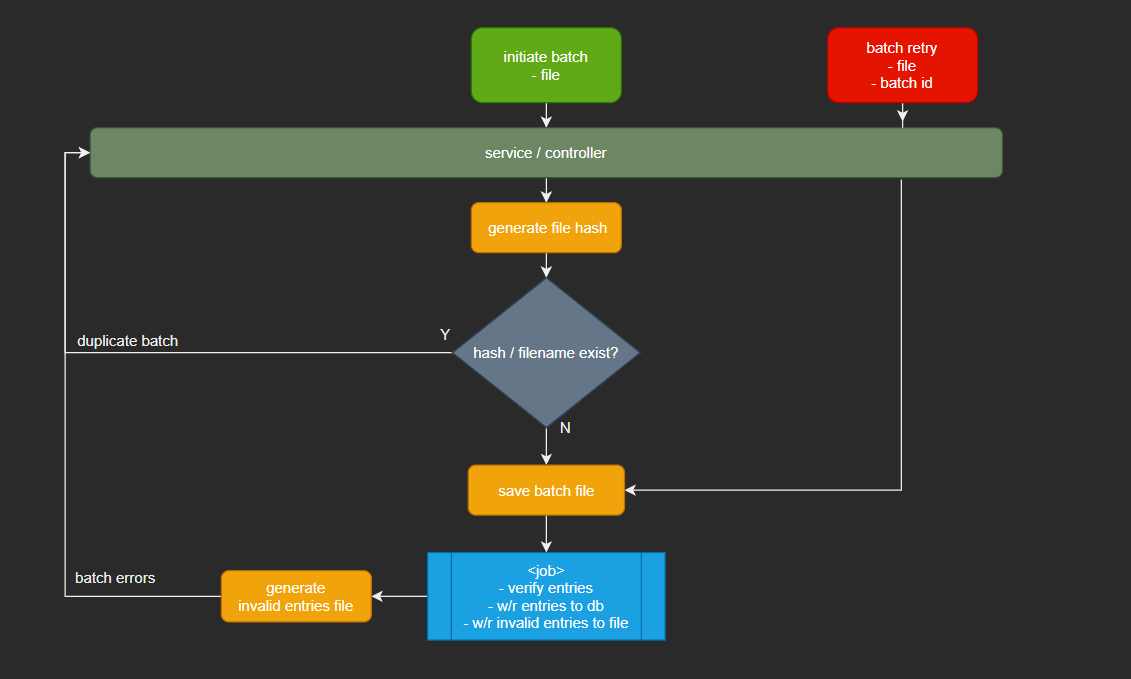
If any invalid entries are found, they are written to a temporary file and returned to the inputter. The inputter can recheck these entries, fix them and reupload that batch.
Imagine a batch entry in which we expect only an account and amount as below
900000123445, 5000.0
9990000234512, 7800.55
If we encounter an entry that doesnt match this pattern, it will be skipped and written to an error file for the inputter to relook.
Batch Jobs
The actual logic is handled by 2 Jobs. After the batch file is checked for duplicates, the first job is fired, this implements a FlatFile Reader from a .txt file as the input data, the processor maps the batch entries to a Batch Transaction Entity. The writer will save each Batch Transaction Entity to the database waiting for authorization.
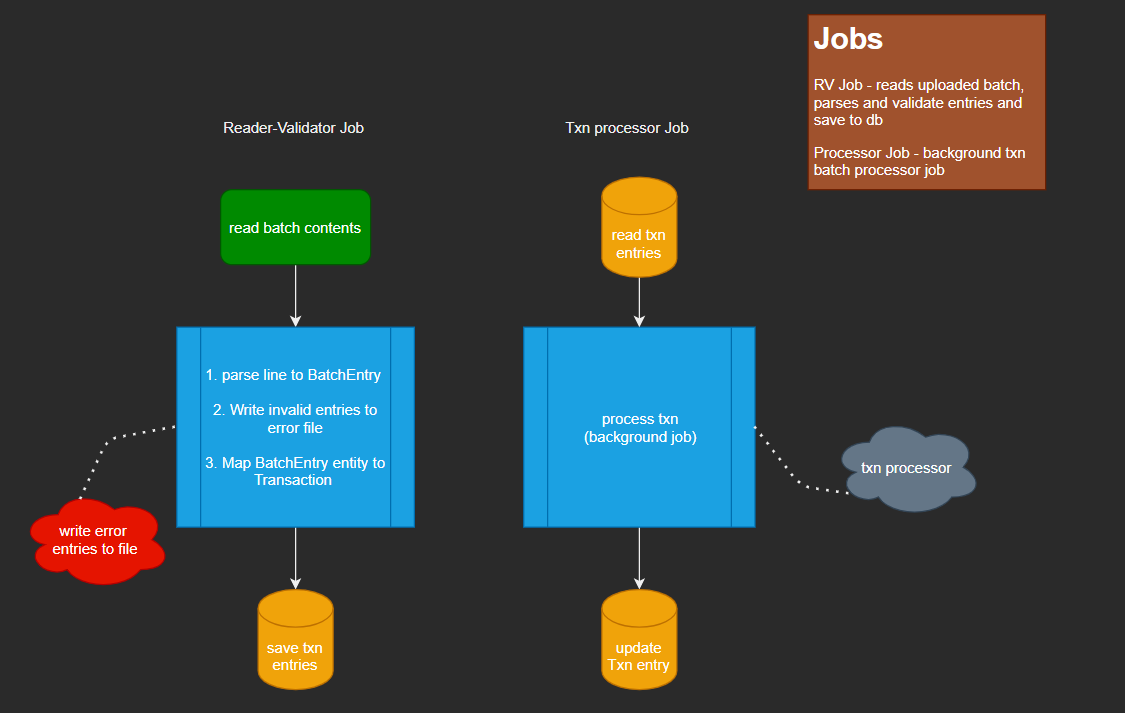
Batch implementations
For some crucial parts of batch processing, I will be adding snapshots, the complete code will be found on the link at the end.
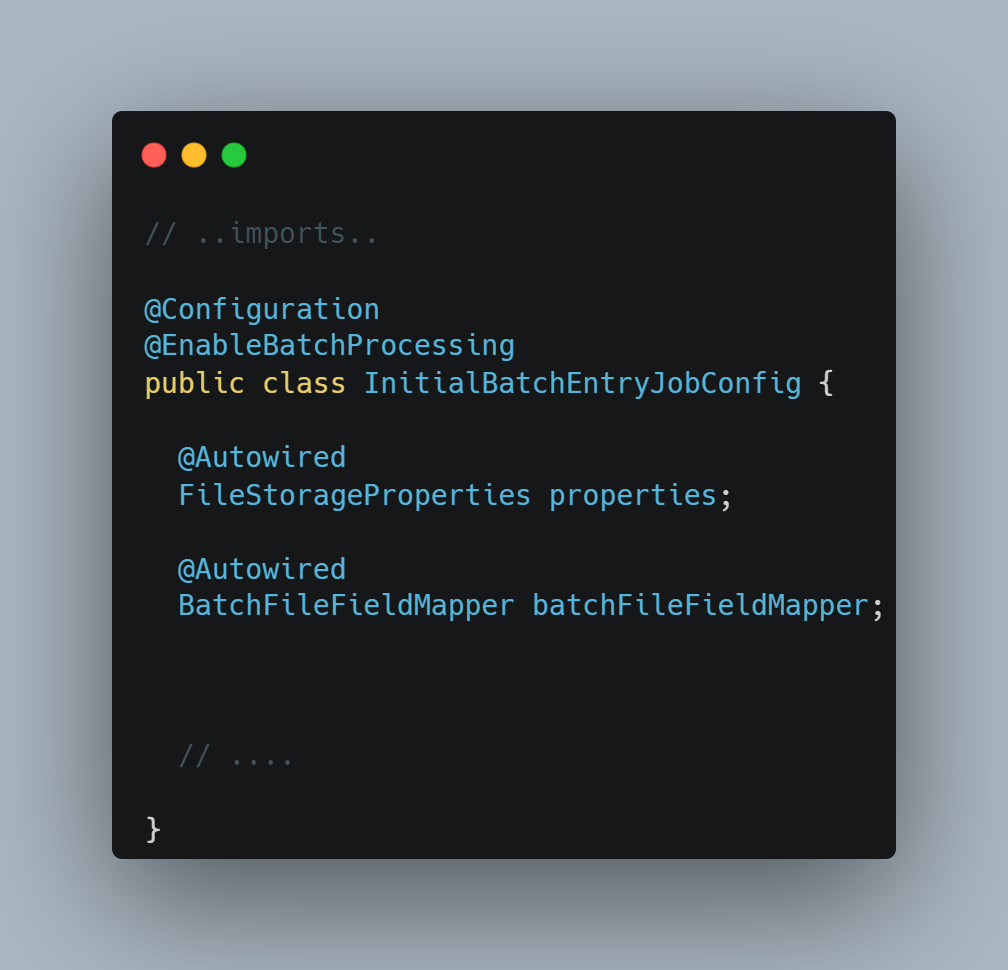
The @EnableBatchProcessing annotation enables Spring Batch features and provides a base configuration for setting up batch jobs. The FileStorageProperties is a config file that ties our batch upload and error files directory. The BatchFileFieldMapper is the implemented mapper that maps the batch file entries into our POJO Entity.
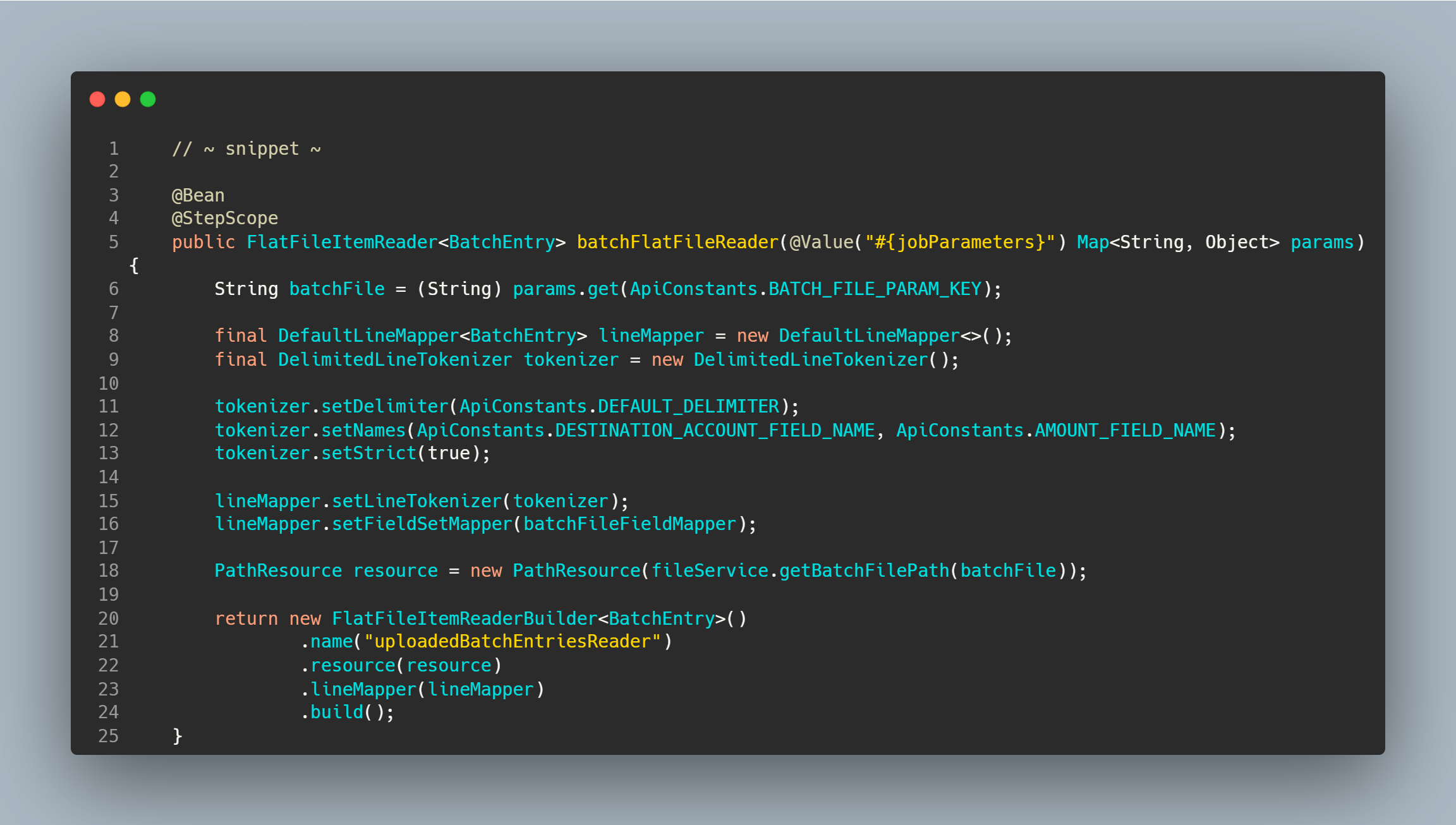
The magic to read the uploaded batch is implemented as above. The system should be flexible enough to process the batch uploaded by the user via REST. To achieve this, the way to process that uploaded file is to take advantage of the JobParameters object provided by SpringBatch. Remember a JobParameter is an object that holds a set of parameters used to start a batch job, so we will add our batch file for process here so that our ItemReader will pick from there [line 6 above]. The ItemReader represents the retrieval of input for a Step, one item at a time. SpringBatch offers several ItemReaders but here we used FlatFile which typically describes records with fields of data defined by fixed positions in the file e.g. comma separated as we see from our batch sample above. The reader will read all contents one at a time until it exhausts all entries.
To easily map the file entries to our custom POJO, the names of the fields can be injected into the LineTokenizer implementations to increase the readability of the mapping function as on line 12, this will be useful in our custom FileFieldMapper which is set on line 16 which looks like below.
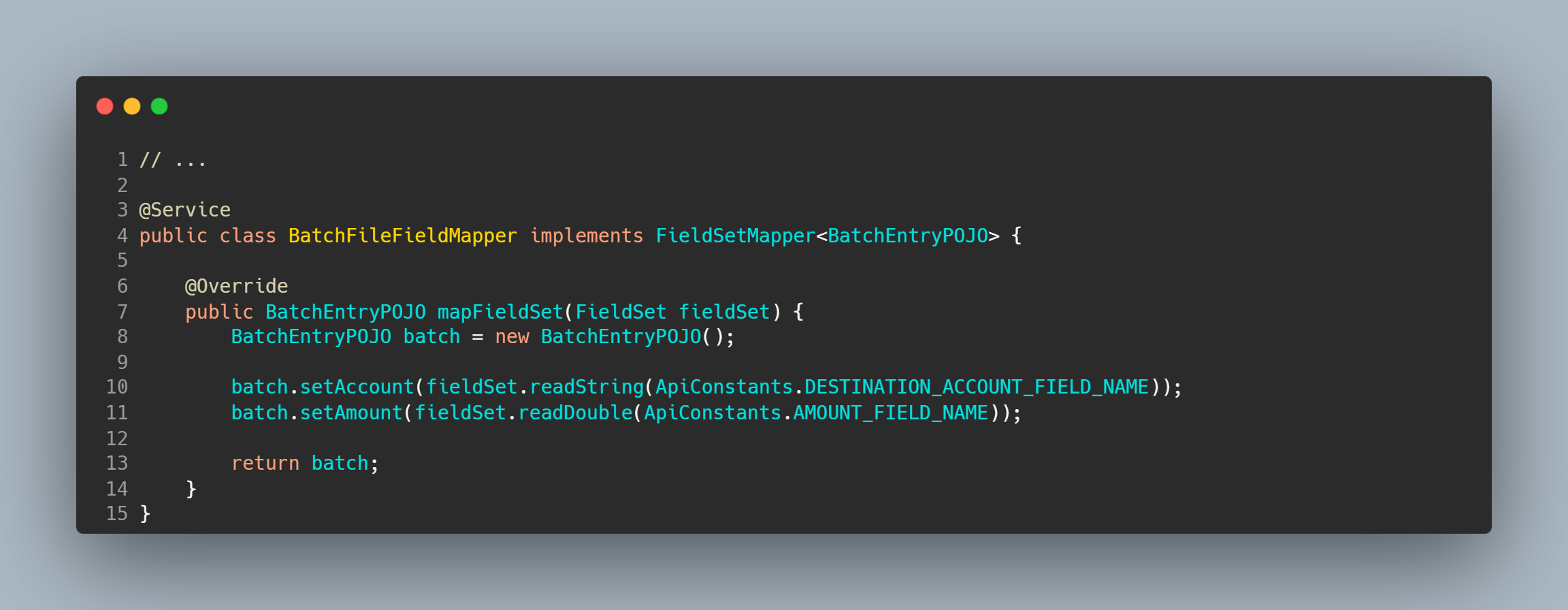
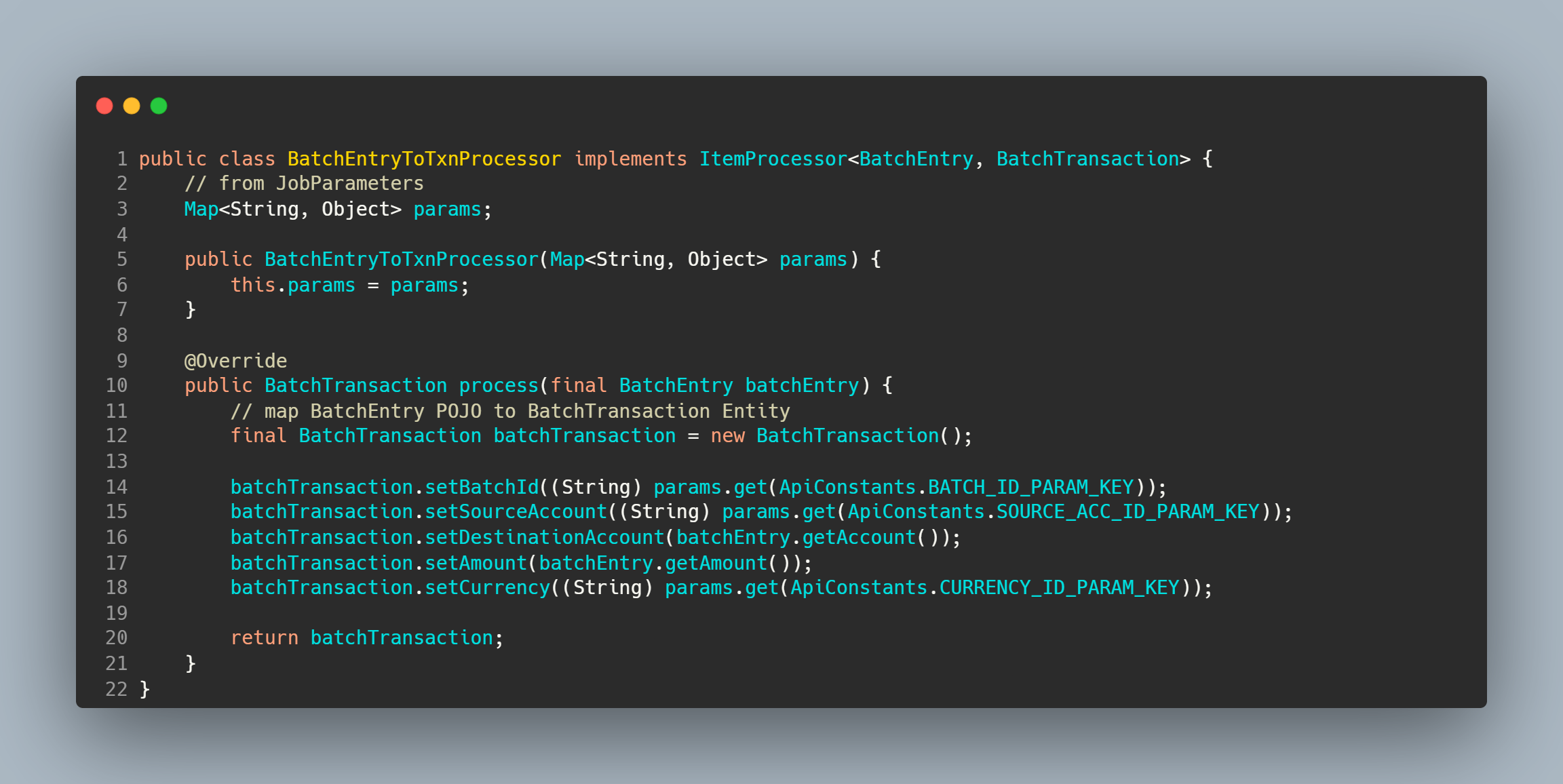
Processor
A processor transforms input items and introduces business logic in an item-oriented processing scenario. A simple item processor for mapping is as below
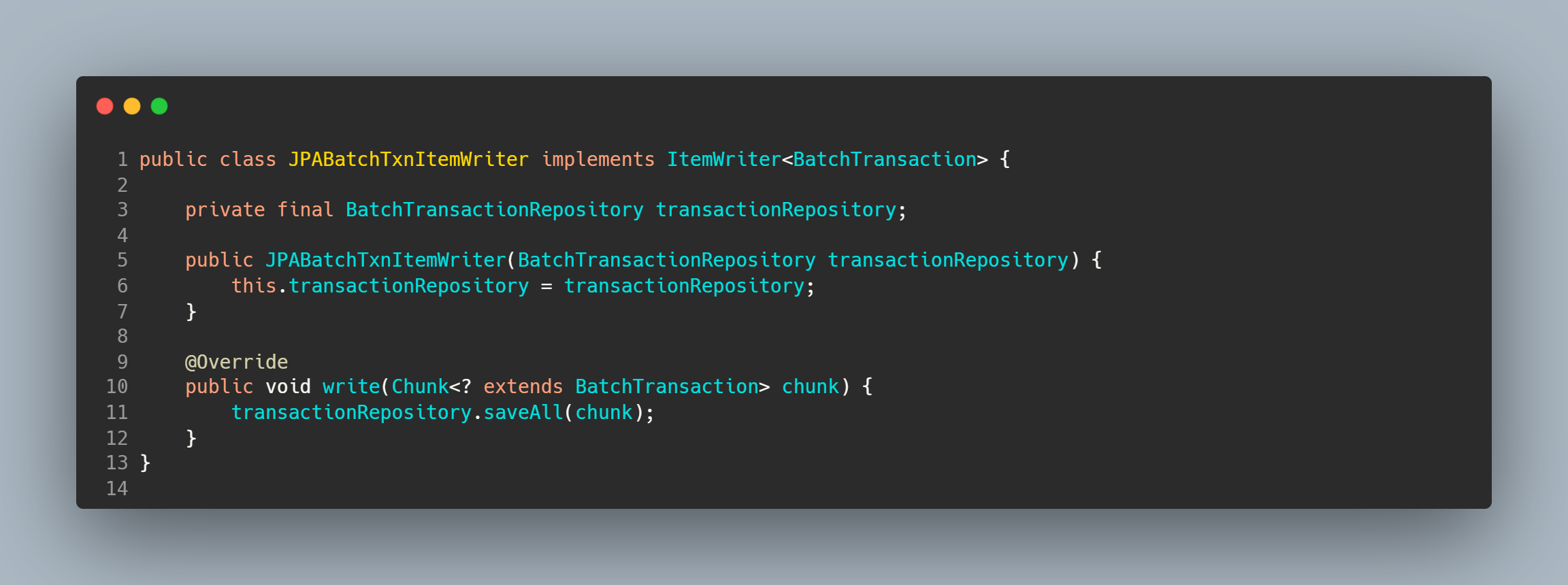
JPA Writer
After processing, we need to write these Batch Transactions to the database. SpringBatch again offers several ItemWriters but for simplicity here we use JPA Writer.
Step
After the reader, processor and writer are implemented, they are all connected in a JobStep. A Step will define the chunk size to process, here a chunk size can be played around with to see how the batch processing can be optimized.
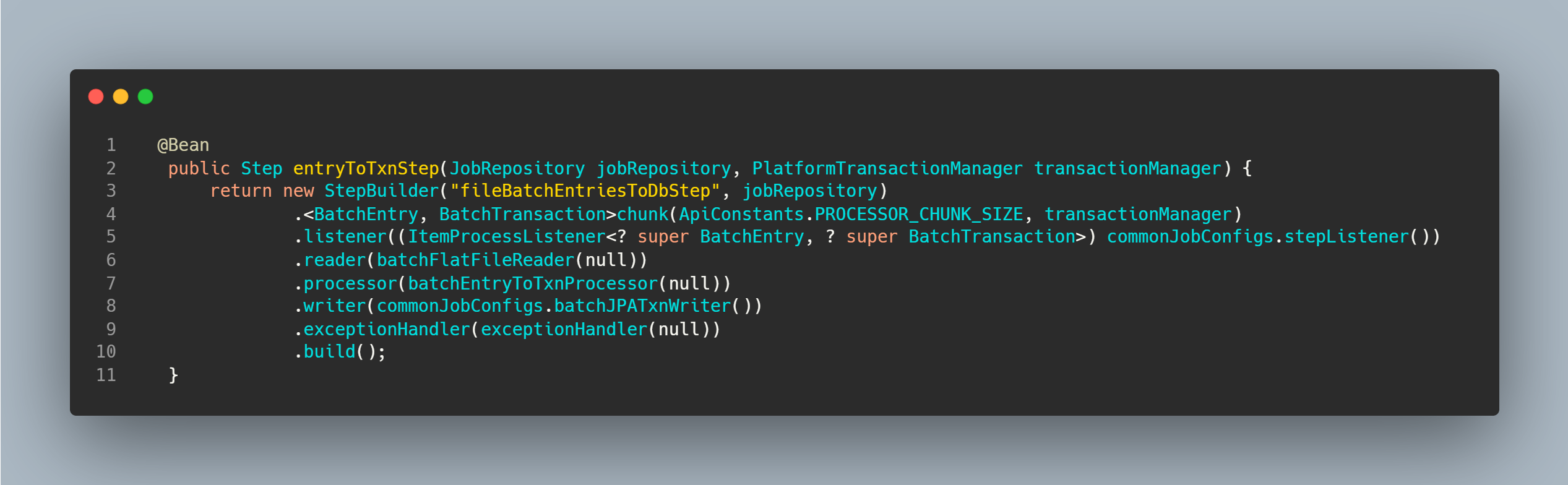
Initiating Batch Jobs
By default, SpringBatch will automatically start the configured job. We do not want this behavior since our approach has a human intervention to initiate a batch. To avoid this, set this property in your application.yml properties.
# ~ snippet ~
batch:
job:
enabled: false
jdbc:
initialize-schema: always
This way, we will have the ability to start the job via Rest once the inputter has uploaded the file.
Will stop here for today, the project source can be found on my GitHub profile here
Subscribe to my newsletter
Read articles from Donald Chinhuru directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by