Efficient Bulk Data Processing in Node.js
 Akinola Raphael
Akinola Raphael
Implementing an efficient method for processing large files in Node.js can be quite challenging. If not executed correctly, it has the potential to result in an unsatisfactory user experience and significant strain on server resources.
In this article, we will explore a scenario where we are tasked with creating an endpoint capable of efficiently handling the creation of millions of customer records from a CSV file. We will delve into various techniques to address this challenge and optimize the process. Let's dive right in.
Setting Up Your Node.js Project
Let's start by creating a Node.js project for our bulk data processing task. Open your terminal and enter the following commands:
mkdir bulk-processing
cd bulk-processing
npm init -y
Next, install the required packages for our project:
npm i express multer csv-parser
Uploading and Parsing CSV to JSON
Our first step is to create a function that allows us to upload and parse a CSV file into JSON format. Here's the code:
const express = require("express");
const router = express.Router();
const multer = require("multer");
const csvParser = require("csv-parser");
// reject non-csv files
const filter = (req, file, cb) => {
if (file.mimetype.includes("csv")) {
cb(null, true);
return;
} else {
cb("Please upload only csv file.", false);
}
};
const storage = multer.memoryStorage();
const upload = multer({ storage, fileFilter: filter });
router.post("/", upload.single("file"), async (req, res) => {
const file = req.file;
if (!file) {
return res.status(400).json({
message: "Please upload a file."
});
}
// Parse the file
await csvBufferToJSON(file.buffer);
return res
.status(200)
.json({
message: "File uploaded successfully."
});
});
const csvBufferToJSON = async (buffer) => {
return new Promise((resolve, reject) => {
const results = [];
const parser = csvParser();
parser.on("data", (data) => {
results.push(data);
});
parser.on("end", () => {
resolve(results);
});
parser.write(buffer);
});
};
module.exports = router;
With this code, we can efficiently parse CSV data into JSON format. When tested with a 1 million-row file, it performed admirably, taking an average of 35 seconds to complete without crashing.

Handling Larger Datasets
However, when attempting to process a 5 million-row CSV file with 512MB of memory, our server crashed. This was due to two primary reasons:
We were using memory storage, which led to loading the entire file into our limited memory.
We were saving all parsed rows into memory, causing our result array to grow until the server ran out of memory.
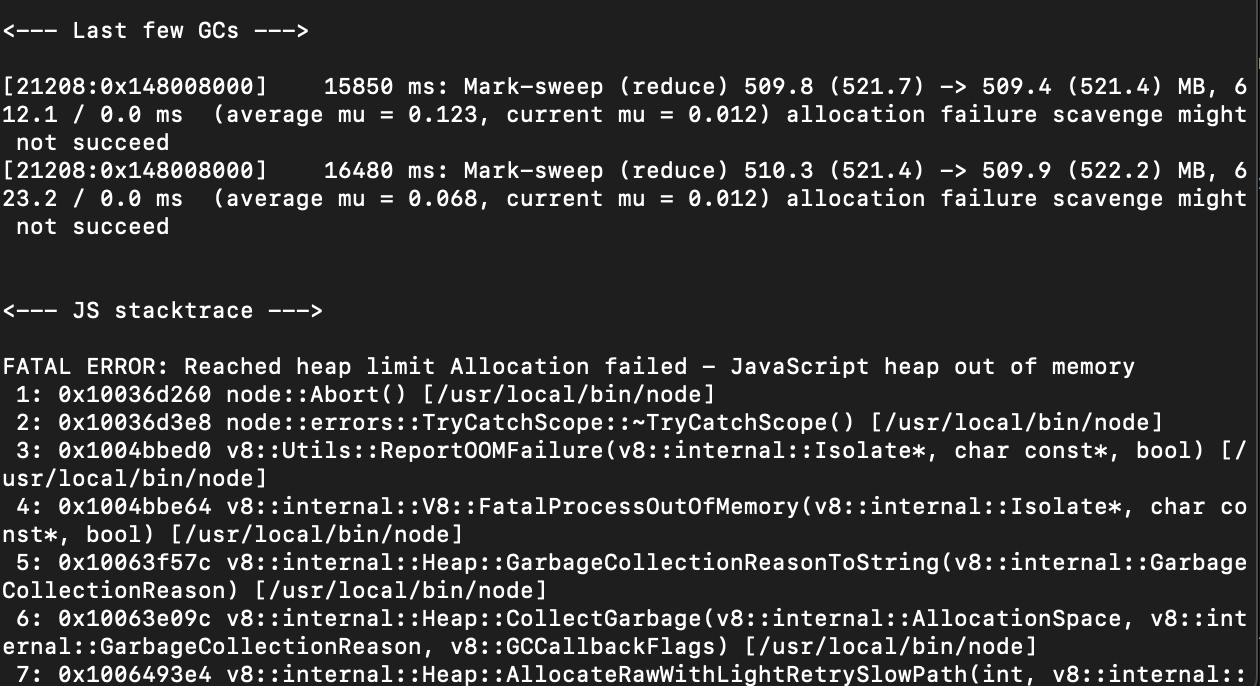
To address these issues, we need to make two key improvements:
1. Saving the File to Disk
Instead of storing the entire file in memory, we can save it to disk using Multer's disk storage. Here's how to do it:
const uploadPath = __dirname + "/uploads/";
const storage = multer.diskStorage({
destination: (req, file, cb) => {
// Save the file to the "uploads" folder
cb(null, uploadPath);
},
filename: (req, file, cb) => {
// Generate a unique name for the file
cb(null, file.fieldname + "-" + Date.now() + file.originalname);
},
});
2. Processing Data as it's Parsed
Instead of storing all the parsed data in memory, we can process it immediately as it's being parsed. To accomplish this, we'll introduce a custom writable stream. This approach is crucial because the "on data" event doesn't support asynchronous operations. Therefore, attempting to modify the "on data" event within the csvBufferToJSON function, as illustrated below, won't yield the desired results:
parser.on("data", async (data) => {
await saveCustomer({
...data
});
});
const saveCustomer = async (data) => {
return new Promise((resolve, reject) => {
setTimeout(() => {
resolve(data);
}, 1000);
});
};
Let's create a custom writable stream that can seamlessly handle our data:
class ProcessCsvChuck extends stream.Writable {
async _write(chunk, encoding, done) {
await saveCustomer(chunk);
done();
}
async _final(done) {
done();
}
};
With this custom stream in place, we'll adjust our controller to efficiently route data from reading the file through the csv-parser and into our custom stream writer. Here's the updated controller:
router.post("/", upload.single("file"), async (req, res) => {
const file = req.file;
if (!file) {
return res.status(400).json({
message: "Please upload a file."
});
}
const processChuckStream = new ProcessCsvChuck({
// We use objectMode to process data as objects instead of buffers
objectMode: true,
});
fs.createReadStream(file.path)
.pipe(csvParser())
.pipe(processChuckStream)
.on("finish", () => {
return res.status(200).json({
message: "File uploaded successfully."
});
});
});
These changes empower us to efficiently handle substantial datasets without worrying about memory constraints.
Asynchronous Processing
Processing a dataset with 5 million rows can be a time-consuming task. To improve user experience, we can process the file asynchronously and provide immediate feedback to the user. Here's how to implement this using the BullMQ package and Redis:
Install BullMQ:
npm i bullmq
Set up a queue for bulk processing:
// queue.js
const { Queue } = require("bullmq");
const BULK_PROCESSING_QUEUE = "bulk-processing-queue";
const redisConfig = {
host: "localhost",
password: "",
port: 6379,
};
const queue = new Queue(BULK_PROCESSING_QUEUE, {
connection: redisConfig,
});
module.exports = {
BULK_PROCESSING_QUEUE,
redisConfig,
queue
};
Implement a worker to handle the background processing:
// worker.js
const { Worker } = require("bullmq");
const {
BULK_PROCESSING_QUEUE,
redisConfig
} = require("./queue");
const worker = new Worker(
BULK_PROCESSING_QUEUE,
async (job) => {
const { file } = job.data;
// Process the file using the custom write stream.
// ...
// send done notification
// ...
}, {
connection: redisConfig,
}
);
With this setup, the server can immediately acknowledge the file upload and process it in the background, improving user experience.
Efficient Parallel Processing: The Two-Worker Approach
To enhance processing efficiency for large files, we can implement a strategy of breaking down the data into smaller chunks and then processing them concurrently. This is beneficial because, with the previous implementation, handling 5 million rows would take an impractical 57 days to complete with the 1-second delay added to our mock saveCustomer function. Let's explore how we can make this improvement:
Step 1: Data Splitter Worker
We'll start by introducing a new function to swiftly count the total number of rows in a CSV file. This functionality is crucial for the data splitting algorithm and tracking progress after processing a chuck.
// utils.js
const readline = require("readline");
const fs = require("fs");
exports.countCsvRows = (filePath) => {
return new Promise((resolve, reject) => {
const fileStream = fs.createReadStream(filePath);
const rl = readline.createInterface({
input: fileStream,
crlfDelay: Infinity,
});
let rowCount = -1; // to exclude header row
rl.on("line", (line) => {
rowCount++;
});
rl.on("close", () => {
resolve(rowCount);
});
rl.on("error", (err) => {
reject(err);
});
});
};
Then we'll proceed with creating the Data Splitter Worker:
// spliter-worker.js
const csvParser = require("csv-parser");
const fs = require("fs");
const stream = require("stream");
const { Worker } = require("bullmq");
const {
FILE_SPLITTING_QUEUE,
redisConfig,
dataProcessingQueue,
} = require("./queue");
const { countCsvRows } = require("./utils");
const worker = new Worker(
FILE_SPLITTING_QUEUE,
async (job) => {
const { file } = job.data;
const totalRows = await countCsvRows(file.path);
const processChuckStream = new ProcessCsvChuck({
// objectMode is needed to process data as object instead of buffer
objectMode: true,
totalRows,
fileIdentifier: file.filename,
});
await new Promise((resolve, reject) => {
fs.createReadStream(file.path)
.pipe(csvParser())
.pipe(processChuckStream)
.on("finish", () => {
resolve();
});
});
},
{
connection: redisConfig,
}
);
class ProcessCsvChuck extends stream.Writable {
chunk = [];
chuckSize = 1000;
totalRows = 0;
fileIdentifier = "";
totalSent = 0;
constructor(options) {
super(options);
this.totalRows = options.totalRows;
this.fileIdentifier = options.fileIdentifier;
}
async _write(data, encoding, done) {
if (
this.chunk.length < this.chuckSize &&
this.totalRows > this.totalSent + this.chunk.length + 1
) {
this.chunk.push(data);
return;
}
if (this.chunk.length) {
this.chunk.push(data);
} else {
this.chunk = [data];
}
await dataProcessingQueue.add(
"process-chunk",
{
chunk: this.chunk,
totalRows: this.totalRows,
fileIdentifier: this.fileIdentifier,
},
{
removeOnComplete: true,
}
);
this.totalSent += this.chunk.length;
this.chunk = [];
done();
}
};
Step 2: Data Processing Worker
Next, we'll create the Data Processing Worker to process the data chunks concurrently:
// data-processor.js
const { Worker } = require("bullmq");
const { DATA_PROCESSING_QUEUE, redisConfig } = require("./queue");
const { saveFileReport } = require("./database");
const worker = new Worker(
DATA_PROCESSING_QUEUE,
async (job) => {
const { chunk, totalRows, fileIdentifier } = job.data;
const res = await Promise.allSettled(chunk.map(saveCustomer));
const report = {
totalRows,
fileIdentifier,
currentProcessedRows: res.length,
failed: res.filter((r) => r.status === "rejected");
};
// save chuck report and return overall file report
const fileReport = await saveFileReport(report);
if (fileReport.totalProcessedRows === fileReport.totalRows) {
// We are done with all
// send notification
await sendNotification(`Done processing file: ${fileIdentifier}`);
}
},
{
connection: redisConfig,
}
);
This approach allows us to efficiently process large files in parallel, significantly reducing processing time. Notably, the saveFileReport function incorporates a protective measure to mitigate potential race conditions that could arise when multiple workers attempt to modify the same record. This safeguard is achieved through the implementation of a locking mechanism.
Additionally, the function handles the storage of all the data that couldn't be processed, allowing for the generation of a comprehensive report later for visibility and analysis. In this regard, we have the flexibility to introduce another worker specifically designed to generate the report in a memory-efficient manner, to ensure the optimal utilization of system resources.
Performance Testing and Results
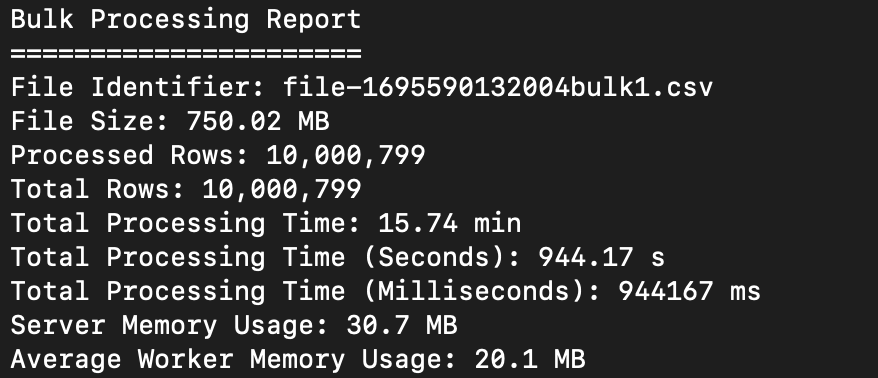
With 10 instances of our Data Processing Workers, we achieved an impressive processing time of just 15 minutes for a CSV file containing 10 million rows. This outcome emphasizes the scalability and efficiency of our parallel processing workflow compared to the initial estimate of 57 days for 5 million rows.
The test was conducted with just 50MB of memory allocated to both the server and workers. Surprisingly, the test ran without any disruptions, signifying our capability to effectively process large files even under low memory constraints.
Conclusion
By following these steps, we've transformed our bulk data processing system into an efficient and scalable solution. We can now handle large datasets without overwhelming our server's memory, provide immediate feedback to users, and process data in the background and in parallel for optimal performance. This approach ensures a smoother user experience and improved overall system efficiency.
In a production environment, several additional best practices should be implemented. These include cleanups to remove files from the server and storage bucket after processing and robust error-handling mechanisms.
Subscribe to my newsletter
Read articles from Akinola Raphael directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Akinola Raphael
Akinola Raphael
Documenting me.