Beginner's Guide to Machine Learning
 Vaka Prasanna
Vaka Prasanna
Introduction
The term Machine Learning was first introduced by Arthur Samuel in 1959.
Machine Learning is a Computer program, which works on past experience.
Machine learning is a subfield of Artificial Intelligence (AI) that focuses on developing algorithms and models that enable computers to automatically learn and make predictions or decisions without being explicitly programmed.
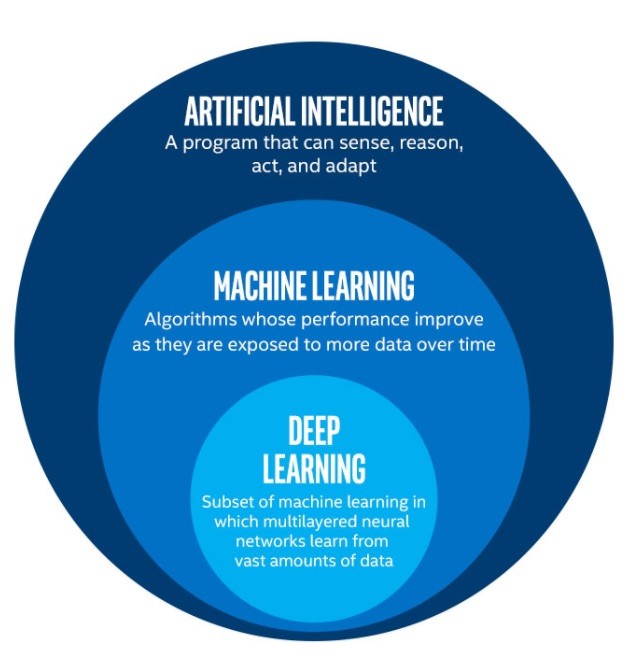
A machine can learn if it can improve its performance by gaining more data.
Formal Definition of Machine Learning
The Formal Definition of Machine Learning can be easily understood by 3 terminologies:
Class of Tasks 'T'
Performance measure 'P'
Experience 'E'
A Machine is said to learn from the Experience 'E' w.r.to Performance measure 'P' and a Class of Tasks 'T', If it's Performance at a task 'T' as measured by 'P' Improves with experience 'E'.
Example: Identifying an e-mail as Spam or Ham
Let us understand the formal definition of Machine Learning, by taking e-mail as an example. In general, all e-mail messages are classified as “Ham”(not spam) and “Spam”.
Spam mail: Spam messages are junk, unsolicited bulk, or commercial messages in the mailbox.
Ham mail: Ham messages are the intended or safe legitimate messages in a mailbox.

Here:
Tasks 'T': The class of tasks 'T' consists of recognizing whether it is e-mail or not and then categorizing emails as either Spam or Ham based on their content, characteristics, and other relevant features.
Performance 'P': It is the accuracy of the email classification system. It is a measure of how well the system correctly categorizes emails as Spam or Ham compared to the total number of emails processed.
Experience 'E': This represents the dataset of labeled emails used to train the machine learning model. This dataset includes a collection of emails with known classifications as either Spam or Ham.
Machine learning is about improving a machine's performance at a set of tasks through experience.
Traditional Approach Vs ML Approach

| Aspect | Traditional Programming | ML Programming |
| Definition | The traditional algorithm takes some input and some logic in the form of code and gives the output. | Machine Learning Algorithm takes an input and an output and gives some logic which can then be used to work with new input to give one an output. |
| Input Data | Explicitly provided by the programmer. | Derived from training data. |
| Algorithm Design | Rule-based, deterministic algorithms. | Statistical models, neural networks, etc. |
| Output | Deterministic, rule-based outputs. | Probabilistic predictions, confidence scores. |
| Problem Types | Well-defined problems with clear rules. | Complex, pattern recognition tasks. |
| Decision Making | The programmer defines decision rules. | The algorithm learns decision rules from the data. |
| Debugging | Easier. | Complex. |
| Domain Knowledge | Requires deep domain expertise. | May require domain expertise, but can learn from the data. |
| Programming Languages | General-purpose languages (e.g., Python, Java). | Python, TensorFlow, PyTorch, etc. |
| Examples | Calculators, databases, web apps. | Image recognition, natural language processing. |
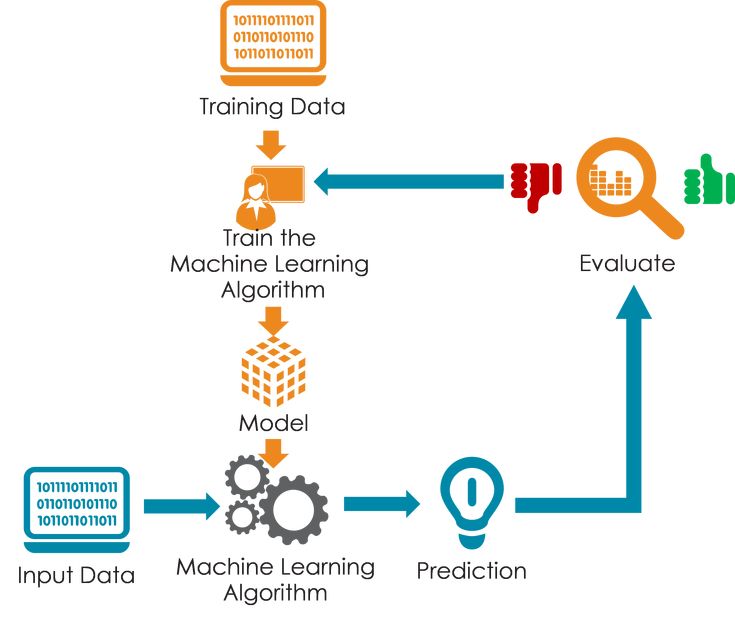
How does Machine Learning work?
Machine Learning starts with historical data, involves training a model using an appropriate algorithm, refining the model's logical representations, and then using the model to make predictions or decisions on new data.
It's a powerful technology that can automate tasks, provide insights, and solve complex problems across various domains.

1) Input Past Data
Machine learning begins with historical or past data. This data can be collected from various sources and can take the form of structured data (e.g., databases), unstructured data (e.g., text or images), or a combination of both. More data and high-quality data generally lead to better model performance.
2) Training
Training is the process through which a machine learning model learns from past data. It involves several key steps:
Data Preprocessing: Cleaning, transforming, and preparing the data to ensure it is suitable for training.
Feature Selection: Choosing relevant features or creating new ones to improve model performance.
Splitting Data: Dividing the past data into two or three sets—typically a training, validation, and test set.
Model Selection: Choosing an appropriate machine learning algorithm or model that leads to better performance.
3) Machine Learning Algorithm
The choice of a machine learning algorithm depends on the nature of the problem. Common types of machine learning algorithms include:
Supervised Learning: Models learn from labeled data, where each data point has an associated output.
Unsupervised Learning: Models discover patterns or relationships in unlabeled data.
Reinforcement Learning: Agents learn to make decisions in an environment to maximize rewards and minimize penalty.
Deep Learning: Neural networks with multiple layers used for tasks like image recognition and natural language processing
4) Building Logical Models
As the model trains on past data, it builds logical representations or internal patterns that help it make predictions or decisions.
These logical models can be simple, like linear relationships between input features, or highly complex, as in the case of deep neural networks.
5) Testing New Data
After training, you need to evaluate the model's performance. This is done by using a separate dataset (testing or validation data) that the model has never seen before. The model's predictions are compared to the actual target values, and metrics like accuracy, precision, or others are used to assess its performance.
6) Output
It refers to the result or prediction generated by a trained ML model when it's given new, unseen data. If the model predicts correctly with a high level of accuracy, it is considered a good model. Otherwise, you may need to explore different algorithms and techniques until you achieve the correct output with great accuracy.
Classification of Machine Learning
Machine learning can be broadly categorized into three main types based on the learning approach and the nature of the training data.
Supervised Learning
Unsupervised Learning
Reinforcement Learning
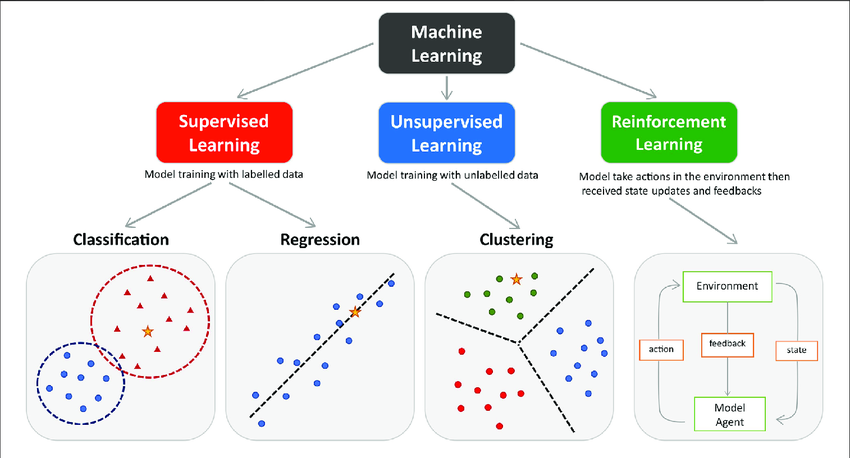
1) Supervised Learning
Supervised learning is a type of machine learning method in which we provide sample labeled data to the machine learning system to train it, and on that basis, it predicts the output.
The goal is to build a model that can learn from this labeled data to make predictions or classifications on new, unseen data. Labeled datasets have both input and output parameters.
Here the algorithms learn to map points between inputs and correct outputs. It has both training and validation datasets labeled.
Common algorithms used in supervised learning include decision trees, support vector machines, and neural networks.

Here, a Labeled dataset is fed to the model as an input, along with some labels such as Carrot, Tomato, and Bell Pepper. Now, the model is trained and ready to make predictions. At this stage, new test data is given to the machine to make predictions and classify them. The model correctly predicts the given data and labels them correctly.
In this, the user knows What to train and What to predict.
Supervised Learning Types:
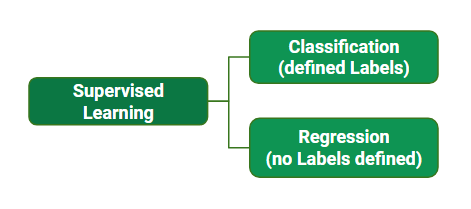
Supervised learning can be further classified into two categories:
1) Classification
2) Regression
-> Classification
It is a type of supervised learning algorithm that accurately assigns data into different categories or classes.
Classification is the task of predicting a discrete class label for a given input.
Classification algorithms are used when the output variable is categorical.
Example:

The data(vegetables + Groceries) is given to the Classification model and then it classifies them into 2 different categories: Vegetables and Groceries.
This is further classified as:
a) Binary Classification
It is a specific form of classification where the algorithm's task is to classify input data into one of two possible classes or categories.
Common examples include:
-> Spam vs. non-spam email classification
-> medical diagnosis (e.g., a person having a disease or not).
-> Yes-No, male-female, True-False, 0/1 etc.
b) Multiclass Classification
The algorithm assigns input data into one of several possible classes or categories.
Here, each instance belongs to one and only one class.
Common examples include:
-> Image classification (e.g., identifying different types of animals)
-> Natural language processing tasks like language identification
->Hand-written, digit recognition.
c) Multi-label Classification
In this, each input can be associated with multiple labels or categories.
This is used when a single instance can belong to more than one class simultaneously.
Common examples include:
-> Movie recommendation system, a movie can be tagged with multiple genres (e.g., action, comedy, drama).
-> Regression
- Regression algorithms are used if there is a relationship between the input variable and the output/target variable.
A regression problem is used when the output variable is a real or continuous value.
Example: Predicting house prices
let us Consider an example of Predicting the price of a House with Regression:

From the above graph, we can easily understand Linear Regression, where house size (in square meters) is taken on the X-axis and the Price (in $) of a house is taken on the Y-axis.
The prediction was based on the Linear relationship that existed between the price of a house and the size of the house.
Here, each data point is a house with its respective size and the price that decides the selling price for a particular House.
Now, you have a house, whose size is 1250 square meters to sell, how would you decide selling Price?
We can build a Linear Regression model from this dataset. Your model will fit a straight line to the data, as shown below:

Based on this straight line fit to the data, you can see that for a house of 1250 square meters size, the price is about $220,000.
Hence, Linear Regression helps to fit a linear relationship between input features and a target variable.
Common examples include:
-> Predicting house prices based on features like square footage
-> Weather forecasting
-> Market Trends, Salary, Weight, etc.
-> Real-World Applications of Supervised Learning
Risk Assessment, Image Classification, Fraud Detection, Visual Recognition, etc**.**
2) Unsupervised Learning
Unsupervised learning is a learning method in which a machine learns without any supervision.
The goal of unsupervised learning is to restructure the input data into new features or a group of objects with similar patterns.
The machine tries to find useful insights from a huge amount of data.
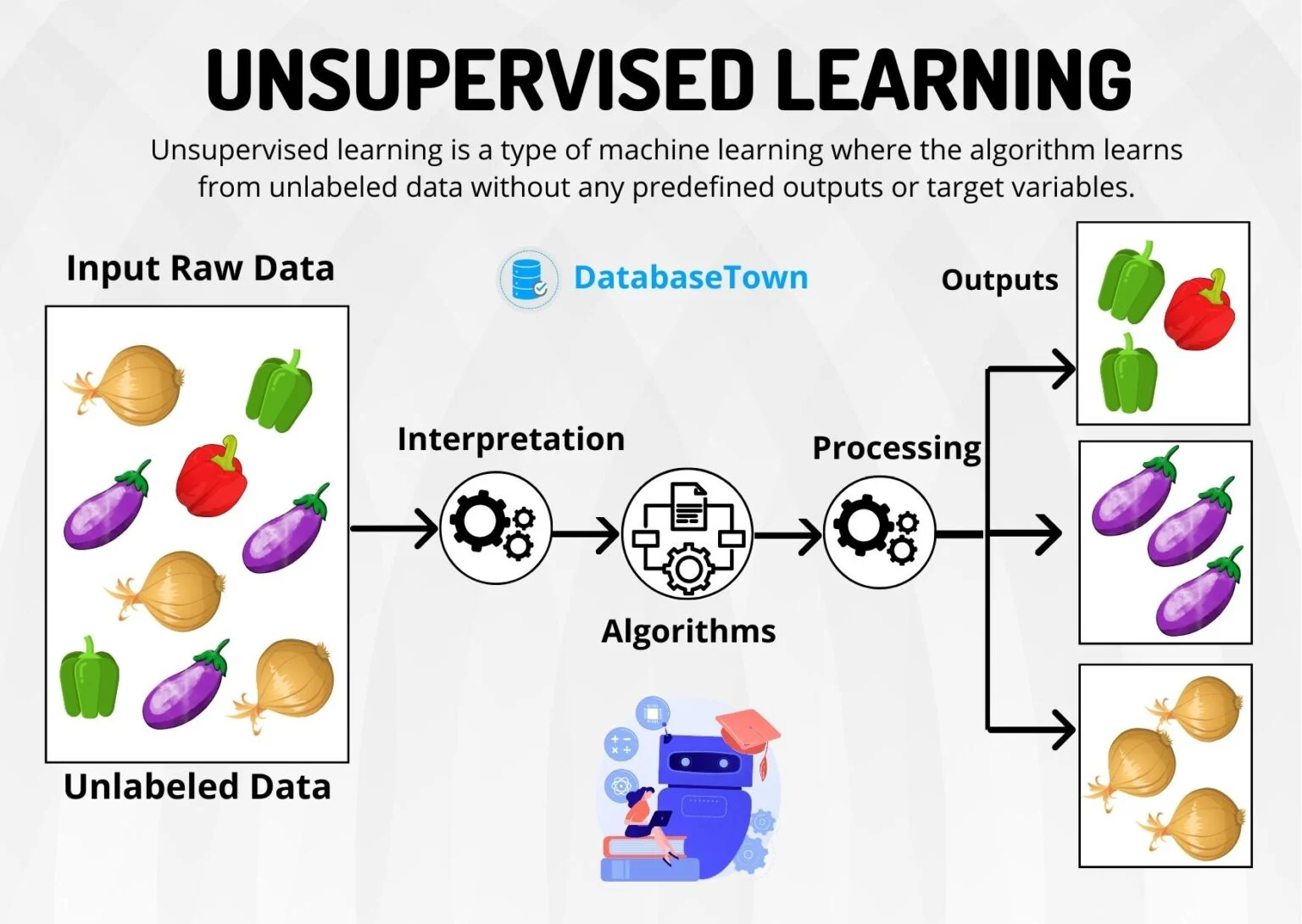
From the above figure, we can see that Unlabeled data is been fed to a machine, which interprets and analyzes the data with the help of algorithms and then processes it to form Clusters or similar groups.
The machine would consider the shape of each item(Vegetable) from a given unlabeled dataset and the similar data items(with the same shape) are been grouped and these are called Clusters.
Hence, we got 3 clusters: Capsicum, Brinjal, and Onions Clusters.
Unsupervised Learning Types:
Unsupervised learning can be further classified into two categories:
1) Clustering
2) Association

-> Clustering
'Clustering' is the process of grouping similar entities.
The goal of this unsupervised machine learning technique is to find similarities in the data point and group similar data points together.

From the above figure, we can easily understand that Clustering/Grouping can be done based on different parameters like Colour, Shape, and Size.
-> Association
Association rule learning is a kind of unsupervised learning technique that tests for the reliance of one data element on another data element.
It is designed appropriately so that it can be more cost-effective.
It tries to discover some interesting relations or associations between the variables of the dataset.

In the above figure, the Association Rule is applied, which aims to understand customer behavior and preferences by identifying which products are frequently purchased together.
Consider a Supermarket, where:
Customer 1 purchased a few items like Bread, Milk, fruits, and Wheat.
Customer 2 purchased a few items like Bread, Milk, Rice, and Butter.
Customer 3 entered the shop and purchased Bread, Now he would be more likely to purchase Milk.
It says that whenever Bread is being purchased, Milk is also purchased. This dependency or reliance on data elements is given by the Association Rule.
-> Clustering Vs Association
A bit confused about understanding Clustering and Association? Don't worry, Have a look at the below figure:

-> Real-World Applications of Unsupervised Learning
Natural Language processing, image, and video analysis, customer segmentation, recommendation engines, Identifying accident-prone areas, etc.
3) Reinforcement Learning
This is a feedback-based learning method, in which a learning Agent interacts with the environment and explores it.
It gets a reward for each right action and gets a penalty for each wrong action.
The goal of an agent is to get the most reward points, and hence, it improves its performance.
This learning is similar to a small Boy exploring and learning things around.

-> Key components of reinforcement learning
Agent: The learner, who interacts with the environment. The agent's goal is to learn a policy (a strategy) that maximizes the reward.
Environment: The external system with which the agent interacts. It provides feedback to the agent in the form of rewards based on the agent's actions.
State: The state provides information about the environment's current condition and is used by the agent to make decisions.
Action: The set of possible moves or decisions that the agent can make in the environment. The agent chooses actions based on its current policy, which maps states to actions.
Policy: A strategy or a mapping from states to actions that define the agent's behavior. The goal of reinforcement learning is to find an optimal policy that maximizes the expected cumulative reward over time.
Reward: A numerical signal provided by the environment after each action taken by the agent. The agent's objective is to maximize the cumulative reward.
-> Example of Reinforcement Learning
Scenario: Teaching a Virtual Dog Tricks using Reinforcement Learning

Agent: A dog.
Environment: Dog's surroundings, which includes the owner or trainer, as well as objects (ball) related to performing tricks.
State: Dog's current position(sitting), the type of trick to perform (catch a ball) i.e. the owner's command.
Action: The dog's response to the owner's command, is performing one of the available tricks(catching the ball).
Policy: The policy is the strategy the dog uses to decide which trick to perform in response to the owner's command.
Reward: The reward is given to the dog based on its actions.
In this scenario, the dog receives biscuits as a reward for successfully performing tricks (catching the ball). Each trick can have a specific associated reward, such as one biscuit for "sit," two biscuits for "catching the ball," and so on.
-> Real-World Applications of Reinforcement Learning
- Robotics, Game playing (e.g., AlphaGo*), Autonomous vehicles, Recommendation systems, Healthcare etc.*
Advantages and Limitations of Machine Learning
Machine learning (ML) has both advantages and limitations. Understanding these is crucial for effectively applying ML in various domains.
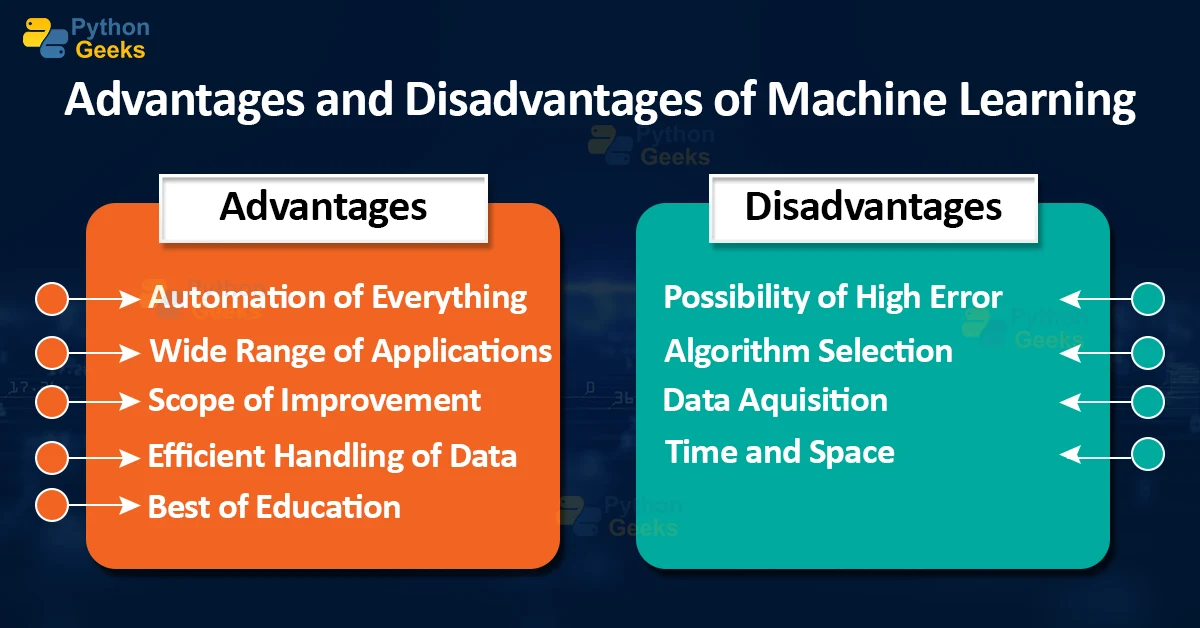
Understanding these advantages and limitations is essential for organizations and individuals working with machine learning to make informed decisions, address challenges, and harness the potential of this technology responsibly.
Applications of Machine Learning
Machine learning has a wide range of applications across various industries and domains.

These are just a few examples, and the applications of machine learning continue to expand as the technology advances.
Machine learning is a versatile tool that can be applied to virtually any domain where data is available for analysis and decision-making.
Subscribe to my newsletter
Read articles from Vaka Prasanna directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by