Understanding MapReduce
 Arnab Sen
Arnab Sen
MapReduce is a programming paradigm that helps us perform large-scale computation across computing clusters.
DISCLAIMER: In this blog, I will take a very simple overview of this topic. If this blog actually spikes your interest and you want to delve into the technical nitty-gritty then I would urge you to read the original paper: "MapReduce: Simplified Data Processing on Large Clusters" (It was written by the Top-Gs in the programming world: Jeff Dean and Sanjay).
Background
Let's start with a little bit of background.
Currently at Google, I am working on a project that requires me to process a large amount of logs, perform some computations, and then write the computed results in a database. This has to happen on a daily basis and the output is then consumed by downstream teams for further operation.
One might think, what's the big deal in that? Just take the log file as input, implement the logic, and write the results to an output file. That's what we have always been doing.
Well, one thing we should take into consideration is the size of the file that we are dealing with. It is actually in the multiple of Terabytes. Taking our traditional path for problems like this would cause a lot of issues like:
Performance Issue: the entire thing would probably take a whole lot of time and it can have a lot of potential bottlenecks.
Memory Issue: How are we even going to load the entire TBs of data into memory? We have to implement some partitioning ourselves to do it effectively.
Scalability Issue: Very difficult to actually scale it to multiple machines.
Fault Tolerance: Let's say you somehow managed to overcome all the problems above, what if at the last moment, something crashes, how are we going to recover?
This is why Google came up with the MapReduce paradigm. There is also an open-source implementation of the same called "Apache Hadoop".
![]()
Link: https://github.com/apache/hadoop
What's MapReduce?
You must have already noticed that the name MapReduce is made up of two parts: Map and Reduce.
You might have often used these functions in Python, JavaScript, etc. Something like this:
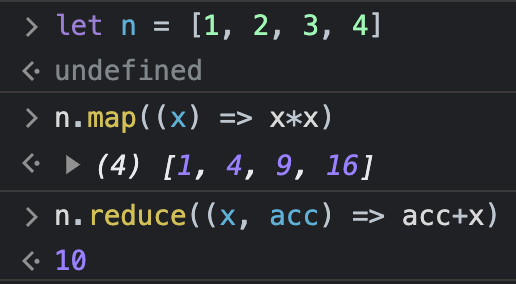
Map Function
The Map function applies a given function to each element in a collection (such as a list or array) and produces a new collection of transformed values. It is often used to perform element-wise operations on data.
Reduce Function
The Reduce function takes a collection and combines its elements into a single result by repeatedly applying a binary operation. It reduces a collection to a single value.
Here is a visualization to help you understand it better:
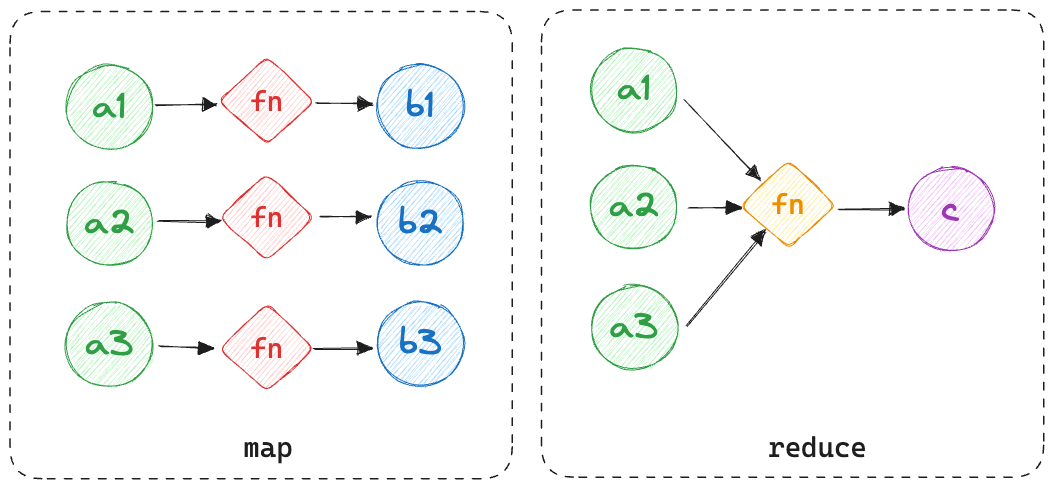
These two methods are fundamental to the Functional Programming Paradigm. I came across these when I started learning functional programming languages like OCaml, Lisp, and Rescript. The main idea is to process the data in a functional, declarative manner.
Inside the map function, we provide the transformational logic and in the reduce function we provide the aggregator logic, and no need to specify any logic for the looping, etc.
A large number of problems can actually be split into two broad logic: Map phase and Reduce phase. Some examples mentioned in the paper are:
Distributed Grep
Counting URL access frequency
Reverse Web-Link Graph
Term-Vector per host
Let me give a simple example, let's say you are working on a Music Recommendation Algorithm. Before you can actually use the data for the recommendation algorithm you will have to do some pre-processing. Usually, logs contain everything, and we may not need all of them, so we have to modify the logs to a form that is relevant to us. To further simplify things, let's say we just need the Genre of the music from the log data. We can use a map function for that.
Then let's say our recommendation algorithm also needs the number of music the user has listened to for each genre. A reduce function can do this. Here is a sample Python code to help you understand better:
from functools import reduce
logs = [
{
'name': 'Shape of You',
'singer': 'Ed Sheeran',
'genre': 'pop'
},
{
"name": "Uptown Funk",
"singer": "Mark Ronson ft. Bruno Mars",
"genre": "pop"
},
{
"name": "Bohemian Rhapsody",
"singer": "Queen",
"genre": "rock"
},
{
"name": "Friends in Low Places",
"singer": "Garth Brooks",
"genre": "country"
}
]
def update_frequency_count(freq_dict, num):
if num in freq_dict:
freq_dict[num] += 1
else:
freq_dict[num] = 1
return freq_dict
# Map operation
# {name, singer, genre} -> genre
genres = list(map(lambda log: log['genre'], logs))
# genres: ['pop', 'pop', 'rock', 'country']
# Reduce operation
frequency_count = reduce(update_frequency_count, genres, {})
print(frequency_count)
# {'pop': 2, 'rock': 1, 'country': 1}
Both of these functions are deterministic. Also, the map operation on one element doesn't depend on the result of another operation. In other words, they are independent of each other as well.
So we can parallelize the operations of Map and Reduce. We can further extend the same thought process by breaking the input data into several chunks of data and having one map function for each chunk of data. This can also solve our Fault Tolerance issue, if something breaks on operation, it won't affect the others cause now they are all running independently in a parallel fashion. We can just re-run the broken process with the small chunk of data. You can see the big picture now as to why the Map and Reduce functions were considered specifically to solve this kind of problem.
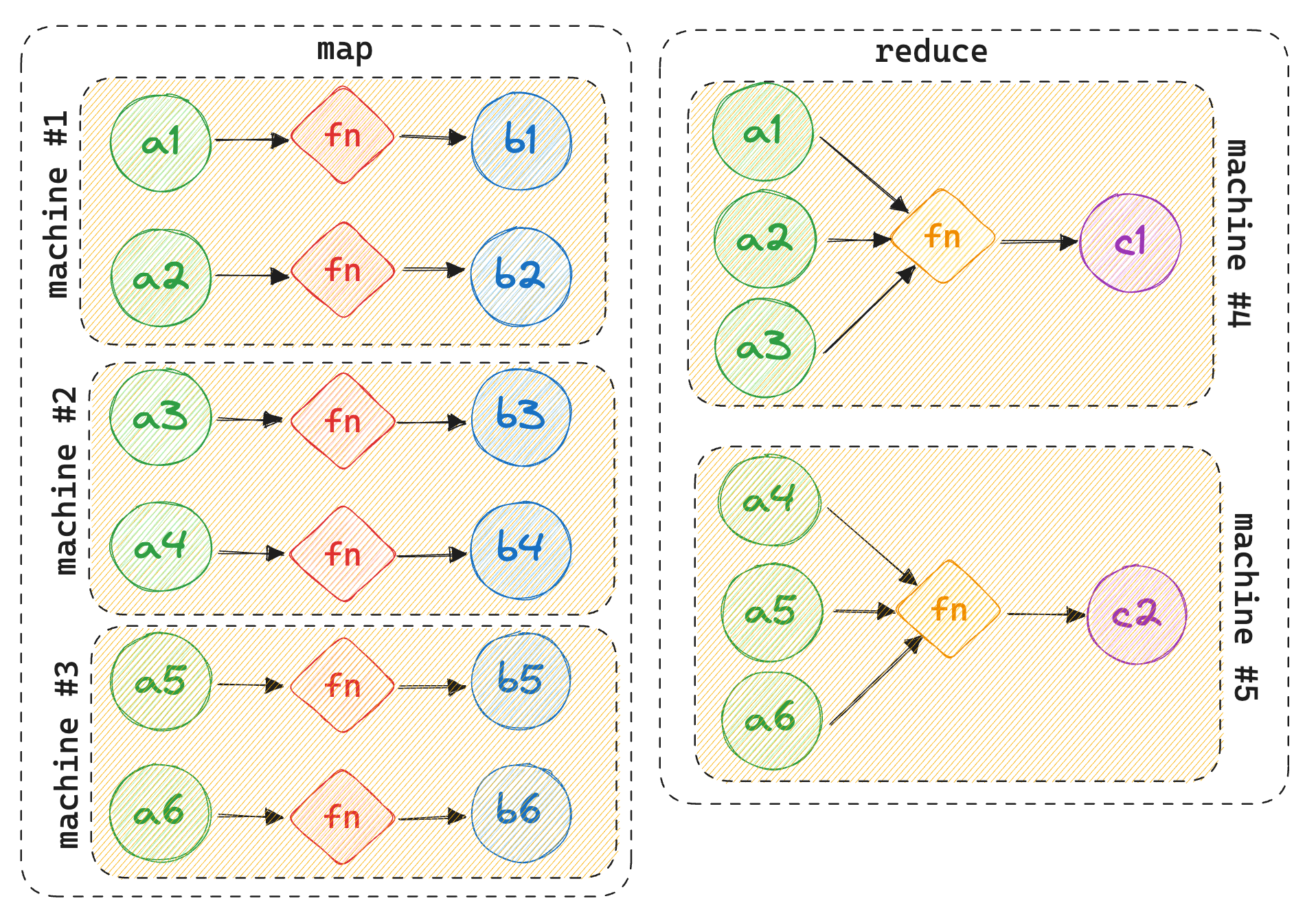
To quote the paper:
"Our use of functional model with user specified map and reduce operation allows us to paralelize large computations easily and to use re-execution as the primary mechanism for fault tolerance."
Let's dive into the programming model deeper and then we will take another very popular example to understand the programming model.
With MapReduce, we usually deal with key/value pairs cause it's pretty generic. The Map takes an input pair and produces a set of intermediate key/value pairs. The MapReduce library groups all the intermediate values associated with the intermediate key I and passes them to the Reduce function.
The Reduce function then accepts the intermediate key I and a set of values for that key and then merge together values to form a possibly smaller set of values (it can be one as well).
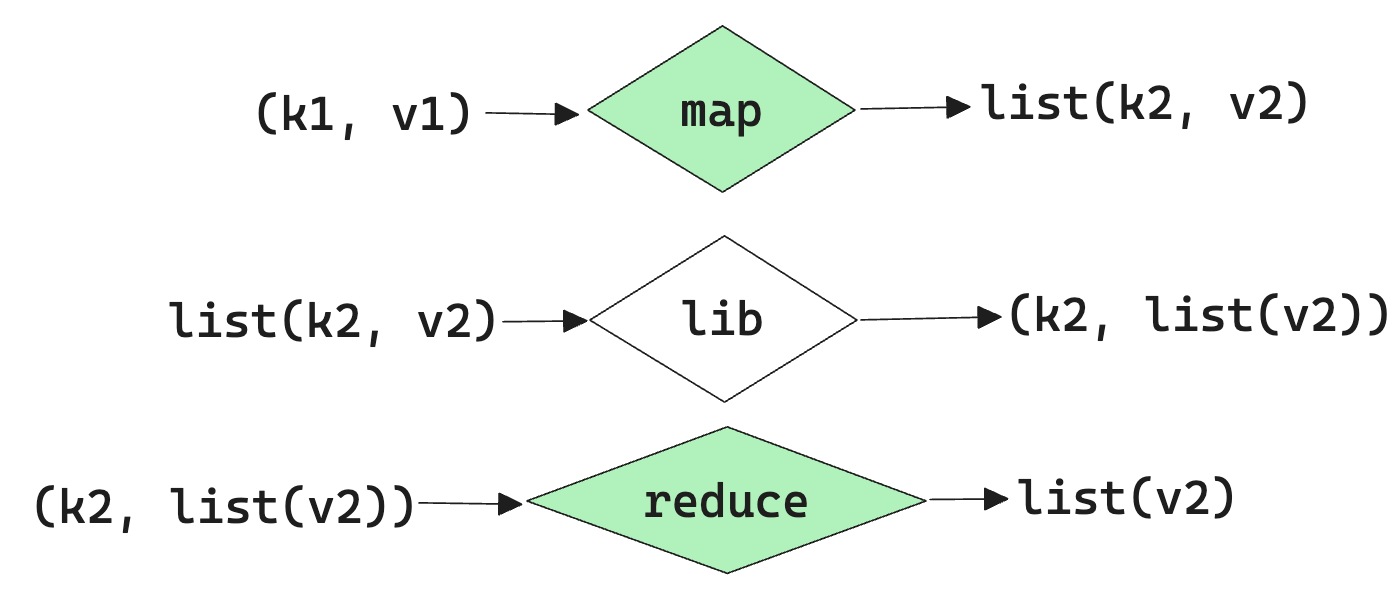
Stages of MapReduce
Now let's dive into the actual working of MapReduce.
Splitting the Input
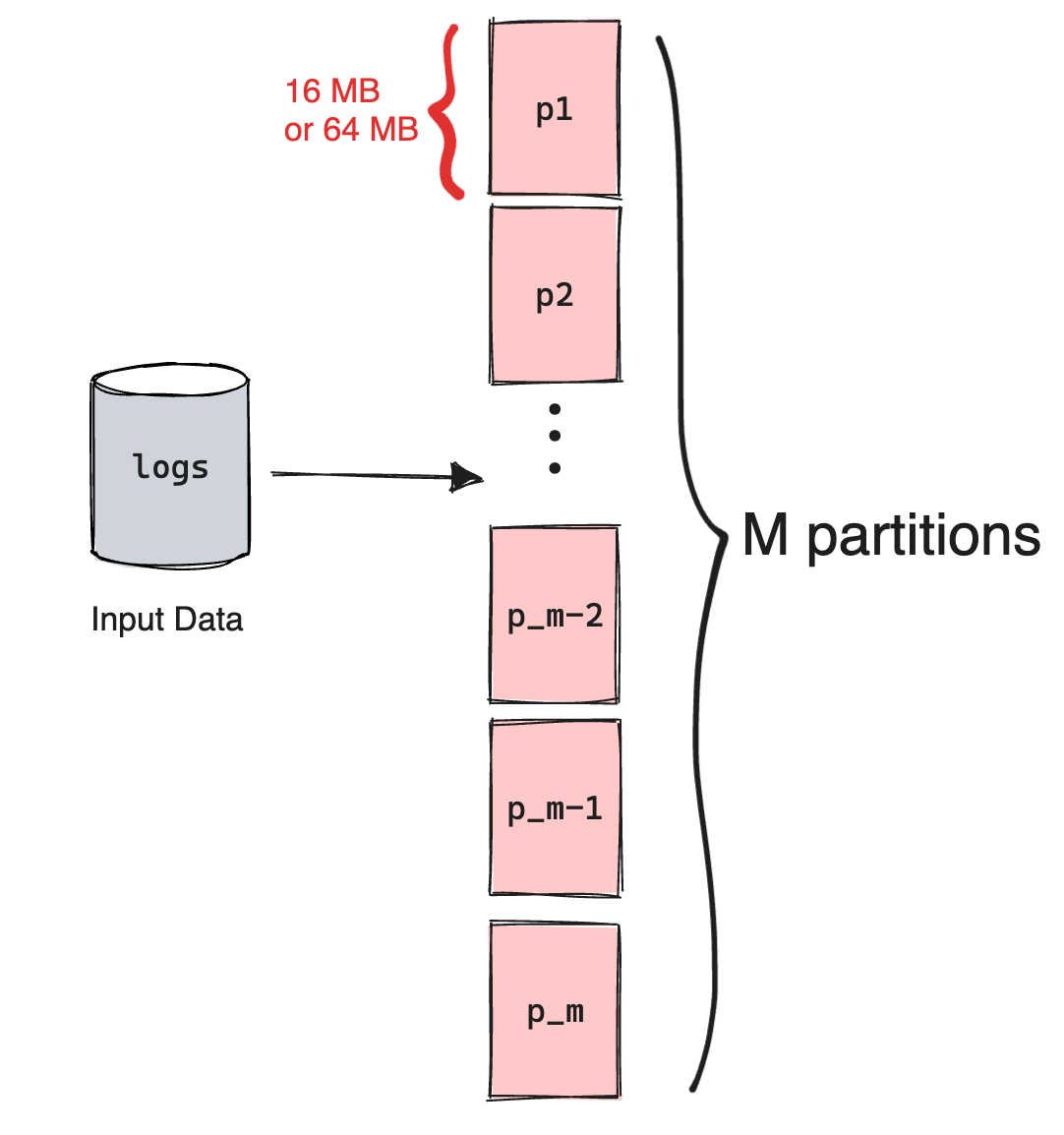
The input data is actually partitioned into smaller chunks, typically 16 MB or 64 MB. Let's say the number of chunks/splits is M. Then there will be M map operations in total.
Why 64MB? That can be a whole separate topic of discussion but you can think of it like these large amounts of data are usually stored on local disks of the machine that make up the cluster. Google File System (GFS) divides each file into 64MB blocks, so having the input data of the same size will ensure that the map function just has to read data from one block thus reducing I/O latency.
The Reduce invocations are also distributed by partitioning the intermediate key space into R pieces using a partitioning function (we will discuss this later in this blog). The number R is also set by the user.
Building the army
When we start the MapReduce function, it first starts a special process called "master". The master as you might have already guessed does a lot of management-related work like assigning Map and Reduce operations, handling exceptions, etc.
The program also starts up many copies of the program on the other machines. These are done by the fork system call. All the other programs except the master are called "worker nodes" or simply "workers". Each of the workers will be assigned a task from the M map tasks and R reduce tasks which is determined by the master.
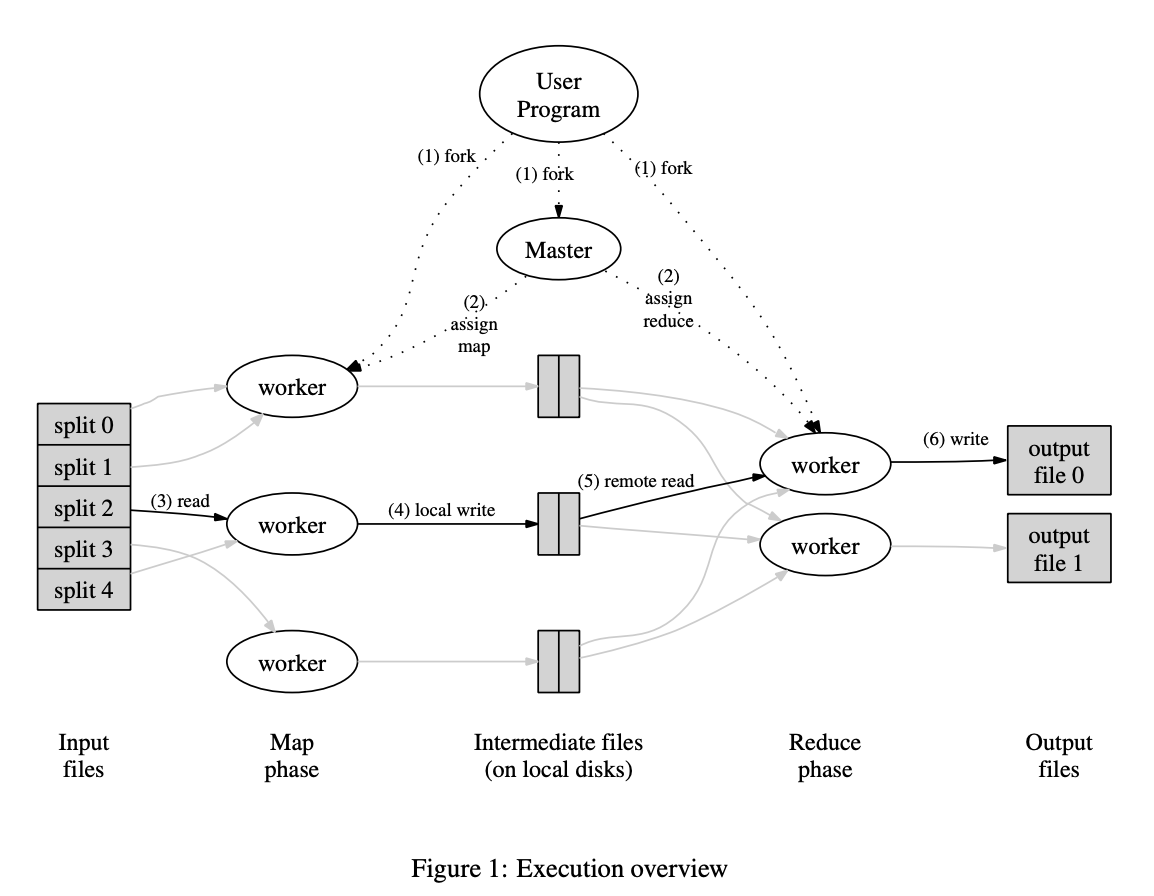
Map Stage
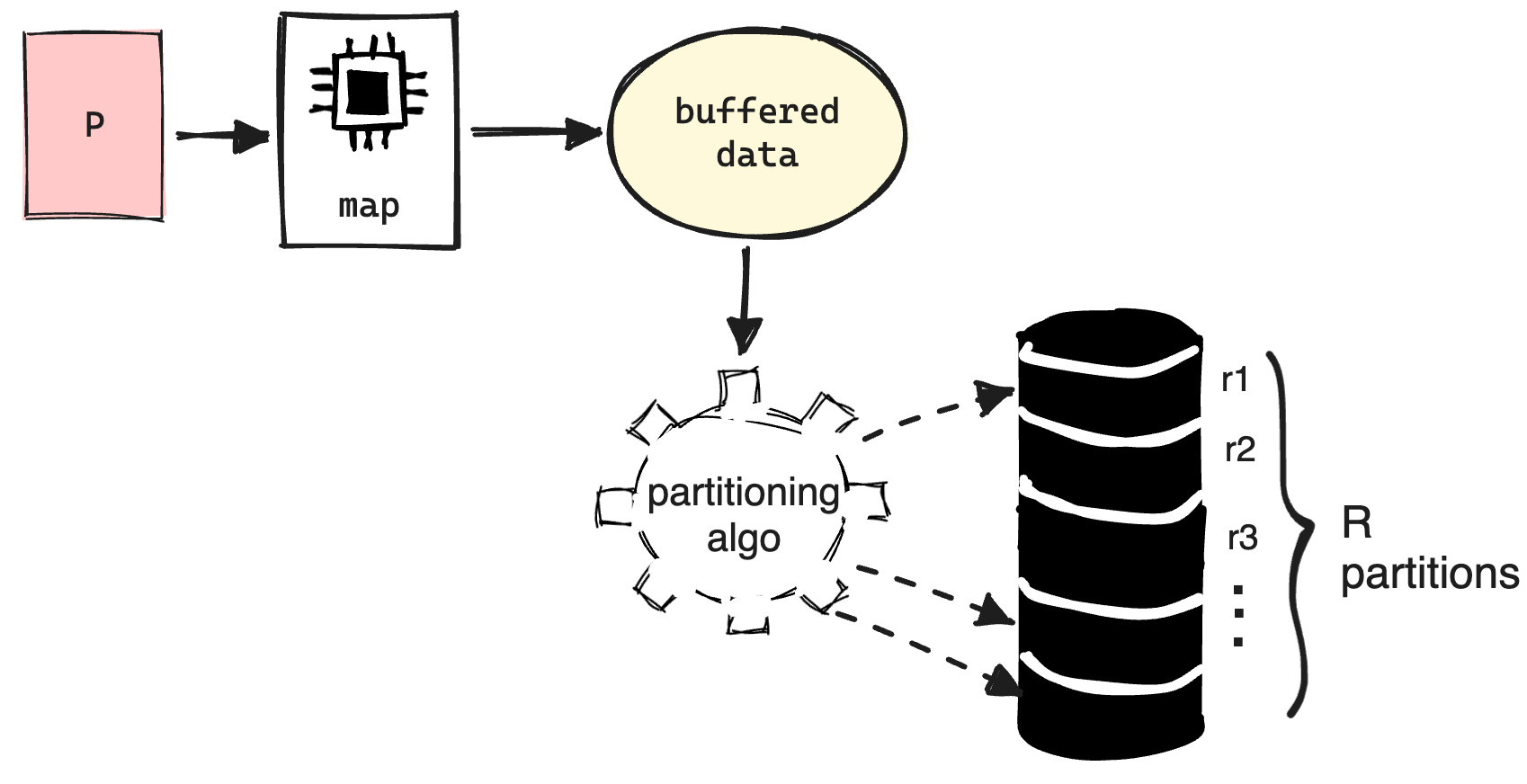
A worker who is assigned a map task reads the contents of the corresponding input split. It parses key/value pairs out of the input data and passes each pair to the user-defined Map function. The intermediate key/value pairs produced by the Map function are buffered in memory. Since the map operation doesn't depend on any other worker, all the map workers can parallelly perform this, thus allowing us to linearly scale the performance of the task of extracting data.
Before the workers with Reduce task assigned can work, these buffered pairs are written to the local disk which is partitioned into R partitions by the partitioning function. Once the partitioning is completed, the master is informed, who then signals the location to the Reduce workers to get the rest of the job done.
Reduce Phase
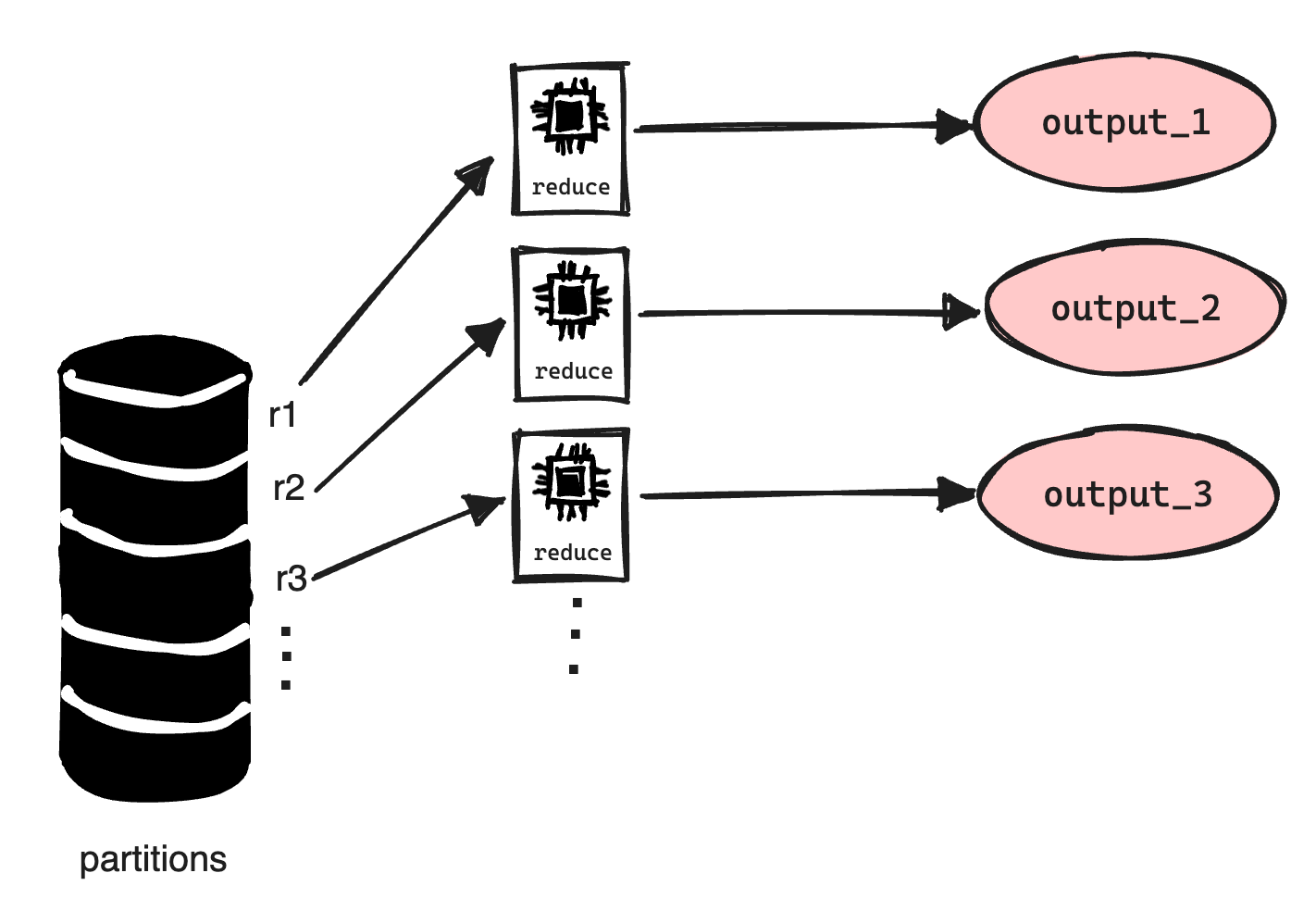
The Reduce workers then read the intermediate data by using RPC calls. Once it has read all the intermediate data, it performs a sort based on the keys. Why?
So that all the occurrences of the same key are grouped together. The sorting is needed because typically many different keys map to the same reduce task.
Let me be frank, it took me some time to wrap my head around this, and I am still not sure if I got it correctly. So if you think my understanding is wrong please don't hesitate to correct me.
Previously we saw that we have M map operations and R reduce operations. Sometimes the same worker is assigned multiple Reduce jobs. Sorting the data makes it easier for the worker to distinguish between the new intermediate data and the old intermediate data. Once the worker finds that the partition has some new data it starts the reduce job again.
In the reduce step it also performs a merge of all the values corresponding to a particular key. So, sorting the keys makes it easier to merge. This will get clear once we go through the steps again taking the example of a word counter.
Finally, the reduce worker goes through the sorted intermediate data and for each unique intermediate key, it passes the key and the set of intermediate values to the user's Reduce function. The output is then appended to the final output file.
Last stage
When all the Reduce workers have completed execution, the master passes control back to the user program. The output of MapReduce is stored in the R output files that the R reduce workers created.
Partitioning Function
Let's understand what the partitioning function is all about. As a user, you can define the number of output files you want your data to split between. That number is denoted as R and MapReduce will assign the same number of Reduce workers. So if R = 10, it means that MapReduce will partition the data from the map workers into 10 splits. Each split will be assigned to one Reduce worker which means that there will be 10 Reduce workers. And then each Reduce worker will write the output to a file so the user will have their processed data split into 10 files.
By default, the partitioning algorithm that is used is hash(key) mod R. This usually gives a fairly balanced partition. In some situations, you might want to use a custom function as well. Taking the example from the paper, if your keys are a bunch of URLs and you want them to be partitioned based on the hostname, then you can use a function that extracts the hostname and then applies the hash and mod. So something like: hash(getHostName(key)) mod R.
Example
Let's take the example of the Character Count. We have an input text file with a bunch of words and we have to calculate the frequency of all the characters appearing in the input.
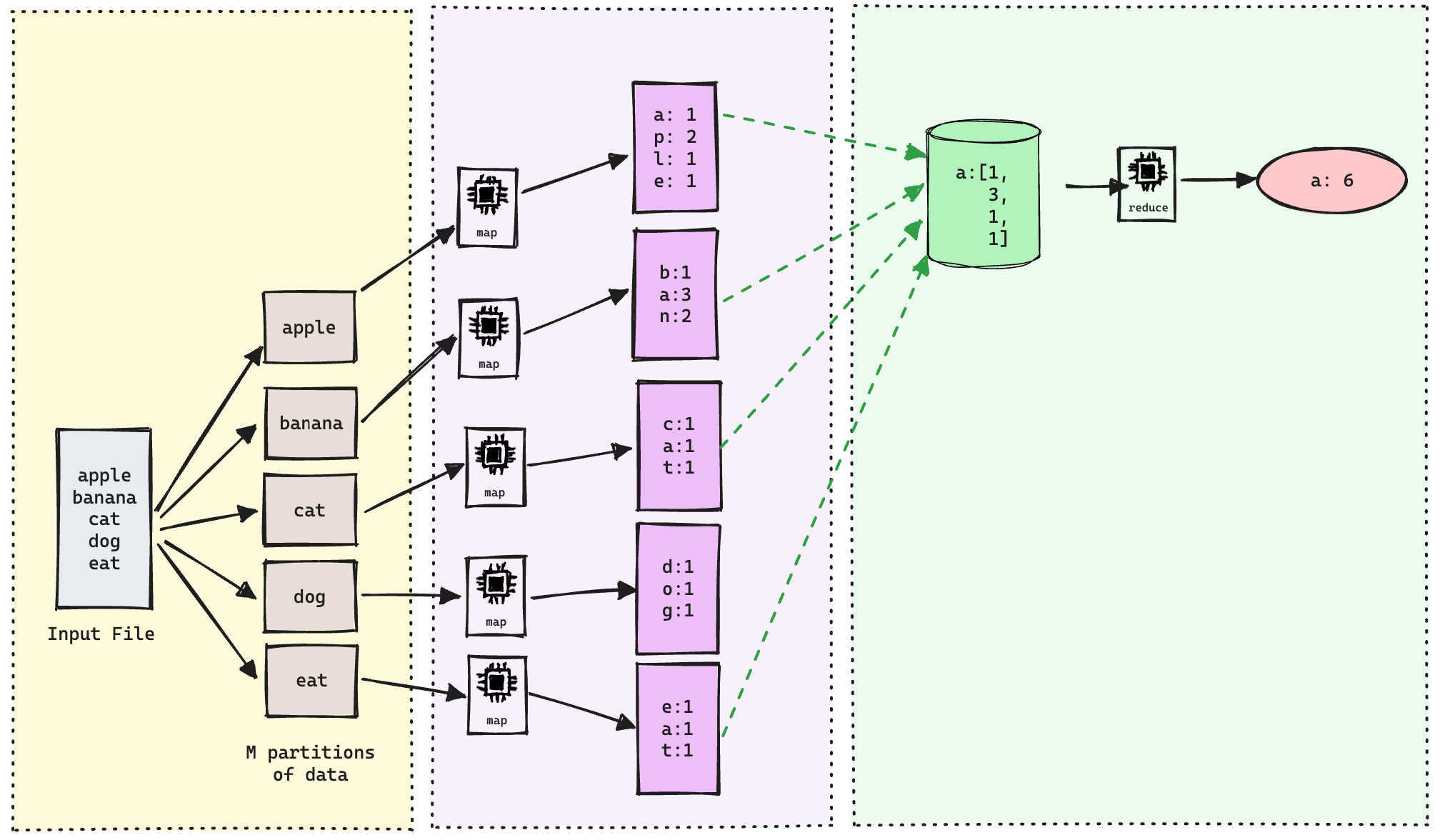
So, first, we have the input data being split into M partitions. In our case M = 5. So the master worker will assign 5 map workers to map each of these input partitions using the user-defined map function which can be something like this.
map(String key, String value):
// key: document name
// value: document content
for each char c in value:
EmitIntermediate(c, "1");
So, for the text "apple" our map function will return:
a: 1
p: 2
l: 1
e: 1
Now, the intermediate output will be "shuffled" by using our partitioning algorithm. Since we are going to consider only the lowercase English alphabet we can have R = 26 for our partitioning algorithm. That way each output will contain the count of one letter. Simply put, our partitioning function will group all the a's and then pass it to our reducer function.
So, in our case, the reducer function will get the following input:
a: [1, 3, 1, 1]
Since we want the total count, we can have a reducer function like this:
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += v;
Emit(AsString(result));
This will give us the final result: a: 6.
So this was a very basic overview of the MapReduce workflow. Keep in mind, that this is not a very generic parallel programming paradigm but only applies to problems that fit into these map-reduce paradigms. But from my work experience, I have seen that a lot of the data analysis work does actually fall into this category. Otherwise, why would Google come up with this in the first place xD.
There are many more technical concepts of MapReduce that I didn't cover in this blog. Do go through the research paper for an even more in-depth analysis. In case you have any doubts, feel free to ping me or put them in the comments.
I hope you found my blog useful. If you have any feedback share it in the comments. You can sign up for the Hashnode newsletter to get notified every time I post a blog. Learn more about me at arnabsen.dev/about. Have a nice day.
Subscribe to my newsletter
Read articles from Arnab Sen directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Arnab Sen
Arnab Sen
Read here -> arnabsen.dev/about