Proximity Power: Mastering K-Nearest Neighbors (KNN) for Data Predictions
 Saurabh Naik
Saurabh Naik
Introduction:
K-Nearest Neighbors, commonly known as KNN, is a versatile and intuitive algorithm used in both classification and regression tasks. Whether you're categorizing emails, identifying handwritten digits, or predicting house prices, KNN is a valuable tool in your machine-learning arsenal. In this blog post, we'll dive deep into the inner workings of KNN, explore its essential components, and understand how it can be applied to various problems.
The Essence of KNN:
At its core, KNN is a simple yet powerful algorithm that operates based on the principle of similarity. It assumes that similar data points tend to have similar outcomes. The key component of KNN is:
Hyperparameter "k":
"K" is the hyperparameter that defines the number of neighbors to consider when making a prediction. It's a critical choice in the KNN algorithm and greatly influences its performance. Selecting an appropriate "k" value is often a trade-off between bias and variance. A smaller "k" makes the model more sensitive to noise, while a larger "k" can lead to over-smoothed predictions.
Lazy Learning:
KNN is often referred to as a "lazy learner" because it doesn't explicitly learn a model during training. Instead, it memorizes the entire training dataset and makes predictions based on the closest neighbors at prediction time. This means there's no upfront computation required during training, making KNN efficient for large datasets.
KNN for Classification:
In classification tasks, KNN is employed to assign a class label to a given data point. Here's how it works:
Find the K Closest Neighbors: To classify a data point, KNN identifies the "k" data points from the training set that are closest to the target data point. The proximity is usually measured using distance metrics like Euclidean distance.
Majority Voting: Once the K nearest neighbors are determined, KNN looks at their class labels and counts how many belong to each class. The class with the highest count (majority) among the neighbors is assigned to the target data point.
This process ensures that the classification decision is influenced by the most similar neighbors, hence the name "K-Nearest Neighbors."
KNN for Regression
KNN is not limited to classification; it's equally capable of tackling regression tasks. In regression, the goal is to predict a continuous target variable. Here's how KNN handles regression:
Find the K Closest Neighbors: Similar to classification, KNN identifies the "k" data points from the training set that are closest to the target data point using a distance metric.
Calculate the Mean: Instead of voting, as in classification, KNN computes the mean (average) of the target values (e.g., house prices) for the "k" nearest neighbors.
Assign the Mean Value: The calculated mean value is assigned as the prediction for the target data point.
A Visual Representation:
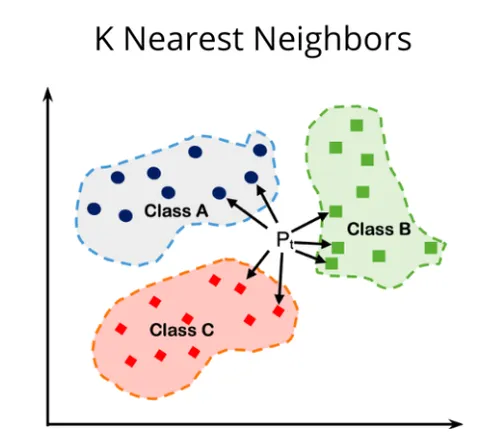
The visual representation of KNN illustrates the concept of finding the closest neighbors and making predictions based on their characteristics. This proximity-based approach is what makes KNN both intuitive and effective.
Conclusion
K-Nearest Neighbors is a robust and adaptable algorithm that finds its place in various machine-learning applications. By understanding its core principles, hyperparameter tuning, and the subtle differences in its application for classification and regression, you'll be better equipped to harness the power of KNN in your data science projects. Whether you're venturing into classification or regression, KNN stands ready as a versatile tool to help you make data-driven decisions.
Subscribe to my newsletter
Read articles from Saurabh Naik directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Saurabh Naik
Saurabh Naik
🚀 Passionate Data Enthusiast and Problem Solver 🤖 🎓 Education: Bachelor's in Engineering (Information Technology), Vidyalankar Institute of Technology, Mumbai (2021) 👨💻 Professional Experience: Over 2 years in startups and MNCs, honing skills in Data Science, Data Engineering, and problem-solving. Worked with cutting-edge technologies and libraries: Keras, PyTorch, sci-kit learn, DVC, MLflow, OpenAI, Hugging Face, Tensorflow. Proficient in SQL and NoSQL databases: MySQL, Postgres, Cassandra. 📈 Skills Highlights: Data Science: Statistics, Machine Learning, Deep Learning, NLP, Generative AI, Data Analysis, MLOps. Tools & Technologies: Python (modular coding), Git & GitHub, Data Pipelining & Analysis, AWS (Lambda, SQS, Sagemaker, CodePipeline, EC2, ECR, API Gateway), Apache Airflow. Flask, Django and streamlit web frameworks for python. Soft Skills: Critical Thinking, Analytical Problem-solving, Communication, English Proficiency. 💡 Initiatives: Passionate about community engagement; sharing knowledge through accessible technical blogs and linkedin posts. Completed Data Scientist internships at WebEmps and iNeuron Intelligence Pvt Ltd and Ungray Pvt Ltd. successfully. 🌏 Next Chapter: Pursuing a career in Data Science, with a keen interest in broadening horizons through international opportunities. Currently relocating to Australia, eligible for relevant work visas & residence, working with a licensed immigration adviser and actively exploring new opportunities & interviews. 🔗 Let's Connect! Open to collaborations, discussions, and the exciting challenges that data-driven opportunities bring. Reach out for a conversation on Data Science, technology, or potential collaborations! Email: naiksaurabhd@gmail.com