How To Implement Micro-Frontend Architecture With React
 Redha Bayu Anggara
Redha Bayu Anggara
Web applications are getting more and more complex. Many organisations are struggling to maintain monolithic frontend codebases, and to scale their frontend development processes across multiple teams.
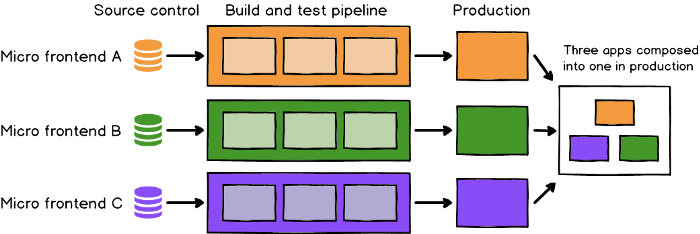
Micro frontends are just one approach to managing that complexity, by splitting products up into smaller, simpler applications that can be delivered all the way to production by independent, autonomous teams.
Introduction
The Micro Frontend style of architecture design does for the frontend of an application what microservices do for the backend, breaking monolithic structures into smaller components that can then be assembling.
React is a popular frontend tech stack, so it’s a great choice for implementing a micro-frontend. The micro-frontend architecture is still fairly new and is still being adopted by different frameworks, so best practices are still evolving. Therefore, you may find it challenging to implement a micro-frontend from scratch. Here, the create-mf-app package comes in.
According to its docs, create-mf-app creates either a module federation application, API server, or library based on one of its templates. It is framework agnostic, meaning it supports multiple frameworks and libraries including Preact, React, Svelte, etc.
Best practices for micro-frontends
Let’s cover some best practices for you to keep in mind when implementing a micro-frontend architecture.
Isolate team code
Each team should develop its features as an independent app, without using a shared state or depending on global variables. Consequently, there should be no sharing of runtime, even if all teams use the same framework.
Establish team prefixes
When isolation is not yet possible, teams should agree on the ownership of namespaces to avoid possible collisions, i.e., CSS, events, local storage, etc.
Build a resilient web app
Each independent team should implement resilient features; even if JavaScript is not enabled or it fails, the feature should still work. Additionally, you should foster performance through universal rendering and progressive enhancement.
Advantages of using a micro-frontend
Simply put, micro-frontends make web applications more maintainable. If you’ve ever been part of building a large application, you know it’s very tedious to manage everything; micro-frontends work similarly to the divide and conquer rule. Now, let’s understand the most valuable benefits of using a micro-frontend.
Deployment and security
A significant advantage of the micro-frontend architecture is that you can separate a single body into individual pieces that can be deployed independently. Vercel can support an individual repo with different frontends regardless of the language or framework, deploying them together. Otherwise, you can use deployment services like Netlify. Once the micro-frontend is deployed, you can use it as an individual frontend only.
To secure your micro-frontend, you can use an SSL certificate like Wildcard, a single or multi-domain, or a SAN SSL certificate. One SAN or multi-domain SSL certificate can secure multiple sites and subdomains.
Technology agnosticism and scalability
With a micro-frontend architecture, you can combine any language or framework in a single project, like React, Vue, Angular, etc. Each frontend team can independently choose and upgrade its own tech stack without an obligation to coordinate with other teams.
Easier learning curve
Each team handles an isolated app feature, which is easier for new developers to understand compared to a frontend monolith. Consequently, the learning curve is linear, translating to lower input costs and higher overall output for new developers.
Vertical domain ownership
Before the introduction of micro-frontends, vertical domain ownership was only possible on the backend via the microservices architecture. Companies could scale product development among independent teams to promote ownership of the backend, however, the frontend remained monolithic.
With the introduction of the micro-frontend, the frontend is split into components with vertical domains owned by each team, ranging from the database to the UI.
Code reusability
Micro-frontends foster code reusability since one team can implement and deploy a component that can be reused by multiple teams.
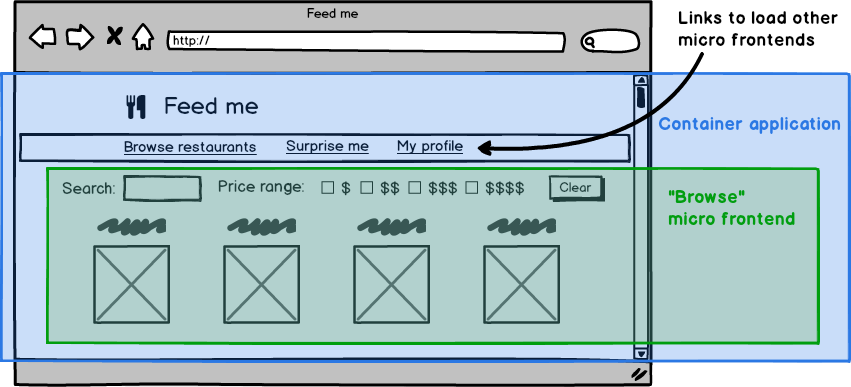
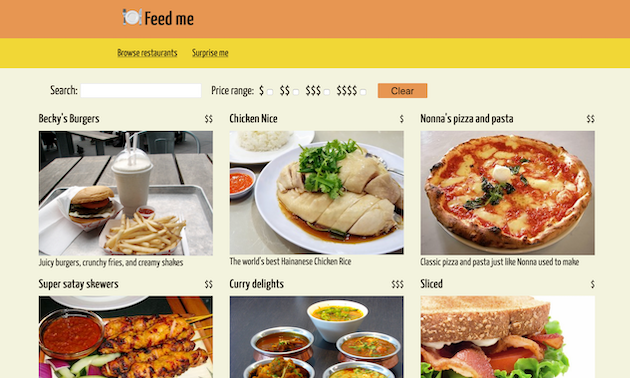
Easy testing
Before jumping into integration testing, it’s better to test individual pieces of an application. Teams will test the micro-frontend before testing the application, thereby decreasing the chances of bugs in the real system.
Apart from that, other advantages include a small codebase that’s easily maintainable and the ability to quickly add or remove any module from the system.
Prerequisites
In this tutorial, we’ll build a micro-frontend with React. To follow along, you’ll need the following:
Basic knowledge of JavaScript
Basic knowledge of React
Basic knowledge of Webpack
The latest version of Node.js installed in your system, v19 at the time of writing
To follow along with the code, check out the GitHub repo for this project.
Bootstrapping micro-frontends
Create an application folder called micro-frontend-react. To bootstrap a React micro-frontend app, from this folder, run npx create-mf-app and pass the following data to the interactive terminal:
Name:
homeProject type:
ApplicationPort number:
3000
Implementing a micro-frontend
In our micro-frontend implementation, the home application will contain and expose two components, Header and Footer. The about application imports and consumes these components.
To implement this, in the src directory in the home application, create two components, Header.jsx and Footer.jsx. Add the following respective code snippets to Header.jsx and Footer.jsx:
import React from "react"
export default function Header() {
return (
<div className="p-5 bg-blue-500 text-white -text-3xl font-bold">
Micro Frontend Header
</div>
)
}
import React from "react"
export default function Footer() {
return (
<div className="p-5 bg-blue-500 text-white -text-3xl font-bold">
Micro Frontend Footer
</div>
)
}
Next, update the App.jsx component to use the following navbars:
import React from "react";
import ReactDOM from "react-dom";
import "./index.scss";
import Header from "./Header"
import Footer from "./Footer";
const App = () => (
<div className="text-3xl mx-auto max-w-6xl">
<Header />
<div className="my-10">
Home page Content
</div>
<Footer />
</div>
);
ReactDOM.render(<App />, document.getElementById("app"));
Test the app by restarting the server, and you’ll get the following:

We need to build the about page in the about app. To do so, update the App.jsx component in the about app, as shown below:
import React from "react";
import ReactDOM from "react-dom";
import "./index.scss";
const App = () => (
<div className="text-3xl mx-auto max-w-6xl">
<div class="text-center">
<img
src="https://mdbcdn.b-cdn.net/img/new/avatars/8.webp"
class="rounded-full w-32 mb-4 mx-auto"
alt="Avatar"
/>
<h5 class="text-xl font-medium leading-tight mb-2">John Doe</h5>
<p class="text-gray-500">Web designer</p>
</div>
</div>
);
ReactDOM.render(<App />, document.getElementById("app"));
Adding module federation
We noted above that the about page in the about app needs to consume the Header and Footer components of the home application. To do this, we need to add module federation.
We’ll begin by turning the Header and Footer components of the home application into micro-frontends so that components in other applications can consume them.
Open the webpack.config.js file in the home app, which is already created and configured by the create-mf-app package. First, update the exposes property in the ModuleFederationPlugin configuration, as seen below:
exposes: {
"./Header": "./src/Header.jsx",
"./Footer": "./src/Footer.jsx"
},
In the code above, we specified that the home application exposes the Header and Footer components as micro-frontends. Consequently, these components can be shared.
Now, restart the server. Although nothing changes in the UI, a remote entry file has been created for us under the hood. To view the remote entry file, navigate your browser to the URL localhost:3000/remoteEntry.js.
This remote entry file, remoteEntry.js, is a manifest file of all the modules that are exposed by the home application.
To complete our setup, copy the link of the manifest file, localhost:3000/remoteEntry.js, then update the remotes property of the ModuleFederationPlugin configuration in the webpack.config.js file in the about app, as seen below:
remotes: {
home: "home@http://localhost:3000/remoteEntry.js",
},
The code above specifies that the about component has a remote micro-frontend application called home that shares its module with it. With this setup, we can access any of the components exposed from the home application.
Now, update the App.jsx component of the about application with the shared navbars, as seen below:
import React from "react";
import ReactDOM from "react-dom";
import "./index.scss";
import Header from "home/Header";
import Footer from "home/Footer";
const App = () => (
<div className="text-3xl mx-auto max-w-6xl">
<Header />
<div class="text-center">
<img
src="https://mdbcdn.b-cdn.net/img/new/avatars/8.webp"
class="rounded-full w-32 mb-4 mx-auto"
alt="Avatar"
/>
<h5 class="text-xl font-medium leading-tight mb-2">John Doe</h5>
<p class="text-gray-500">Web designer</p>
</div>
<Footer />
</div>
);
ReactDOM.render(<App />, document.getElementById("app"));
Restart the dev-server, and you’ll see following in your browser.
Key problems
React disadvantages
Rendering a complex application on a server to HTML string takes quite a long time, 10ms to 100ms in the worst cases, and is a single heavy synchronous task (renderToString). And the new API for streaming rendering (renderToPipeableStream) doesn’t solve the problem, more on that later. There are benchmarks, such as BuilderIO/framework-benchmarks, in which many frameworks outperform React by times.

Specifics of Node.js
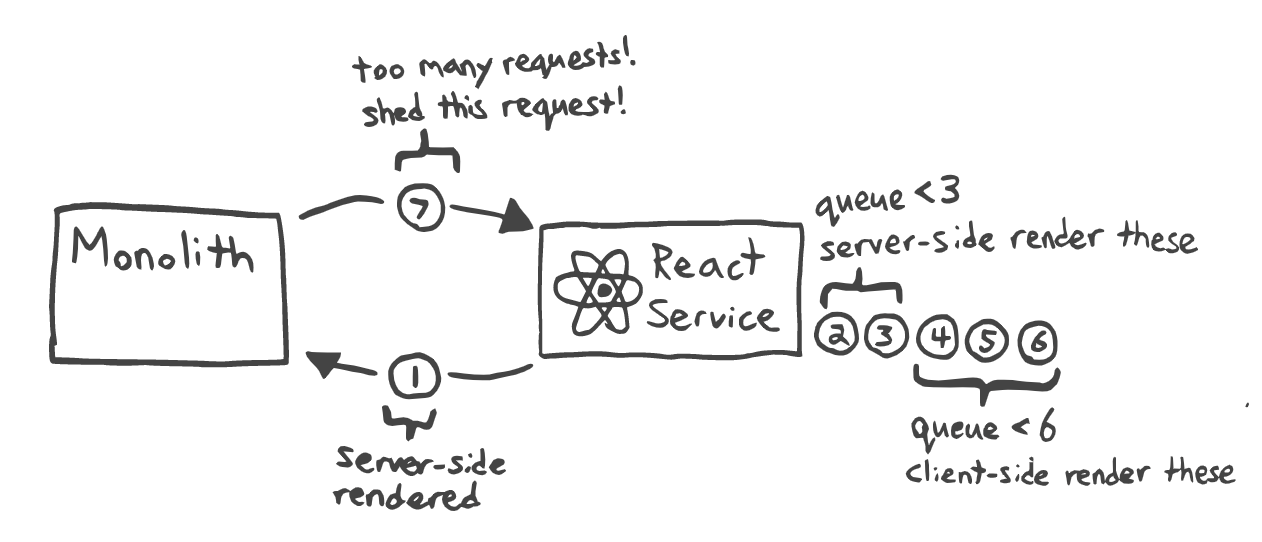
Node.js is single threaded, and quite sensitive to high loads (although I don’t have much to compare it with). One of the side effects of an overloaded application is long responses to requests for metrics or health checks.
It also means that synchronous tasks will be executed one by one. Let’s say the application received 20 requests, page rendering takes 50ms — so first request takes 50ms to respond and last one takes 1000ms, which is unacceptably slow (and in real application most of the response time is spent on third party API requests, here we purposely ignore that for simple calculations).
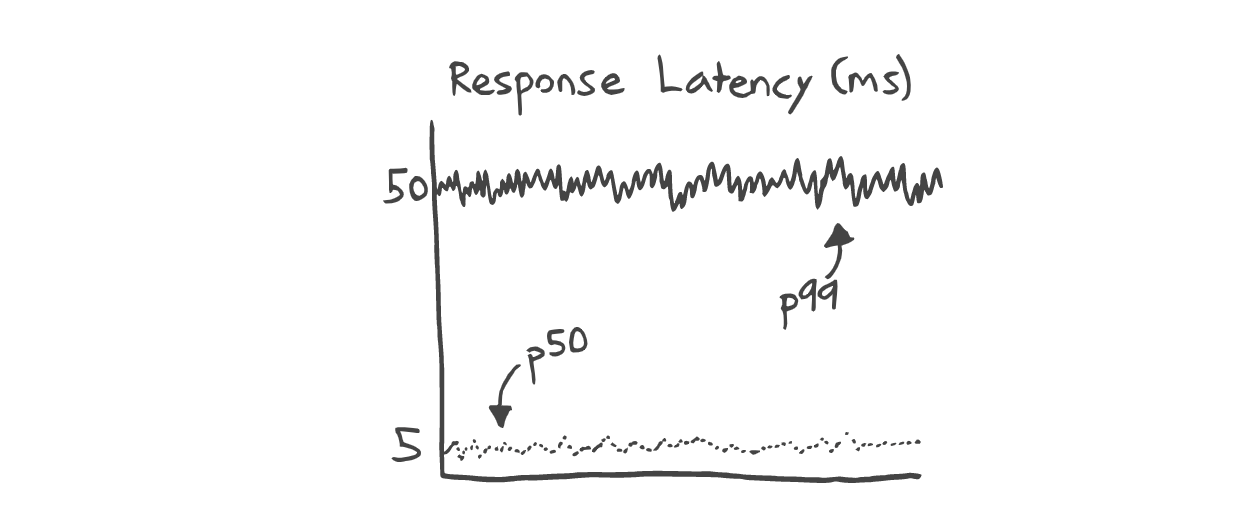
About latency
To maintain appropriate response time, we will need to horizontally scale our application by raising the number of application instances such that at the current RPS, the response time at the theoretical 95 percentile is as expected. If average rendering time is 50ms (take a bad scenario), and we want to respond in 300ms maximum, there must be no more than 4–6 RPS load per instance, which is very low, because we have to allocate enough resources for this instance as well.
About resources
Regarding resources. It seems that single-threaded node doesn’t need more than 1 CPU (or 1000m — milliCPU in Kubernetes terms), but there is also Garbage Collector which can work in separate threads — and it seems optimal to allocate 1100m per instance, then GC can work without affecting main thread performance.
This is where the other problem comes in — low utilization of available resources, since we have to leave the pods not overloaded, for the same reason — latency. This is very important in an era of resource scarcity and expensive hardware (current reality probably all over the world).
But can we allocate less than one CPU? Unfortunately, no, as this will directly start to degrade the response timings of the application. By allocating less than 1000m per sub in k8s, synchronous tasks will start to be affected by CPU throttling, an example of the problem:
allocate 400m CPU
start the task at 200ms CPU time
every 100ms the k8s will spend 40ms on the task
in total the task will execute in 440ms
A very good overview of CPU throttling can be found here.
Streaming rendering
What about streaming rendering?
If it’s possible to redesign application architecture to deliver pages in parts, or at least head contents at the beginning — that’s great, it can give a good boost to Time To First Byte and all paint metrics. But streams have their own overhead, renderToPipeableStream is at least 10–20% slower than renderToString — and for example 100 ms task splitted into 5ms tasks still loads our applications, and suffers from throttling as well.
Let’s go back to the example with 20 requests, and render at 50 ms. With streaming rendering there may not be fast and slow requests — if all these requests came at the same time, then the response will be generated in parallel. Total for each request will be roughly the same bad response time — from 900 to 1000 ms. This is up to you to decide which behavior is better for your users.
Possible optimizations
For systematic load growth horizontal scaling is good, we can gradually increase the number of pods, and it seems to be no problem since there are actually more clients.
For spikes in load we can set up automatic scaling — e.g. raise ×2 instances for a while, then turn it off.
But there are cases where this doesn’t help, for example:
DDoS
Large advertising campaigns
Lack of available hardware
In all of these cases, we are both willing and able to provide a good user experience.
Next we look at a number of possible optimizations, some of which work well together:
Static Site Generation
Rendering at the Edge
Microservices
Code optimization
Component caching
Request Caching
Rate Limiting
Fallback page cache
Client-side rendering fallback
Clustering and Workers
And immediately a great article on the subject. Another article, less practical but also interesting.
Static Site Generation
SSG is an optimal rendering solution — we generate and cache pages at build stage or in runtime, deliver this static via CDN, and can keep unmatched loads.
Of course, there is a disadvantage, and a very big one — any kind of dynamics, personalization, A/B tests will suffer. I haven’t yet encountered projects without such dynamics, SSG was at most suitable for individual pages.
All this seems to be true for Incremental Static Regeneration at Next.js.
Rendering at the Edge
Rendering an application with Edge or Lambda functions closer to the user is a great way to improve response timings, if your framework and your deployment environment allow it.
Even without this, placing the application behind a CDN can be useful — taking Microsoft Bing as an example, the content will be closer to the user, and a good and stable connection can be guaranteed between the CDN and the application server.
Microservices
Probably a better reason to split a large application into separate services — by domain area, by individual teams. But sometimes single pages can be disproportionately heavily loaded, and affect the rest of the application pages. In some cases, putting even a single page into a separate application might be a good solution to this problem.
I will not discuss the other pros and cons of splitting into services, as this is beside the point.
Code optimization
At high loads, even a few milliseconds of processor time makes a difference. The best advice here is to profile your application, Chrome DevTools are great at visualizing what time is spent on processing requests.
In our documentation there is a guide on how to profile a Node.js (a bit specific, but each SSR framework will have its own specifics to run).
Examples of problems that can be found and improved:
heavy regexp (I got one for 100+ ms work)
repetitive actions (e.g. parsing User-Agent, 2–3 ms per call, multiple calls per request with the same argument, can be stored in LRU cache)
complex components (e.g. on tinkoff.ru one of the micro frontends — Header and Footer, common across all applications. Got rid of unnecessary tags and components, slightly improved rendering time of literally all pages on the site, which are dozens of different applications)
Component caching
In theory, it is possible to cache the result of rendering of individual components and share it between requests. Do it either by some hacks with dangerouslySetInnerHTML or custom ReactDOMServer implementations.
But you get all the problems of SSG — you need to find components that have no dynamics, and big enough for optimization to make sense — it’s hard. Context, which depends on request and specific user, seems to leak out almost everywhere.
Request Caching
Must have! You should cache everything you can — usually GET requests without any personalisation. Requests are the ones that slow down an application’s response time the most.
LRU-cache is great for this. By the way, we have our own fork of the very fast node-lru-cache, from which we have removed all the unnecessary stuff for the minimum size.
Remote caches, such as Redis, are not used so as not to complicate deployment and waste resources — for the most part, there is more than enough space for in-memory caches.
To make request caches even better — they can be warmed up. For example, tramvai applications at startup make (sequentially and slowly) requests to all application pages, and users are very likely to get to the fast responses, for which the main information is already cached.

Rate Limiting
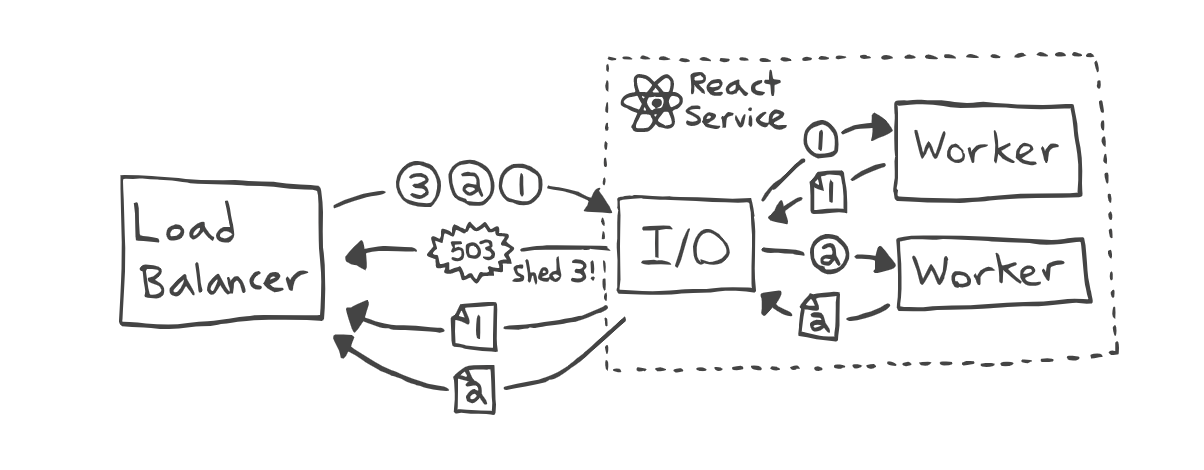
The best way to keep an application from dying is to reduce the load. There are different methods and algorithms, but in general it comes down to only a part of the requests coming into the application, and the rest are queued up, and this happens somewhere higher level, e.g. on the balancer.
It turns out that this can also be done at the level of your application, and this gives a lot of flexibility — because it is at the application level that we can understand exactly how it feels — the built-in API nodes and custom code can give us a lot of information — such as event loop lag, how much memory we consume, how much time we spend on responses.
Example of a fastify plugin that knows how to limit the load on an application.
For tramvai applications we have developed our own Request Limiter, and it is very cool, allowing applications not to die under any load in principle.
How it works:
Limits the number of simultaneous requests
Checks current lag in event loop, if good, increases limit, if high, decreases it
Requests over the limit go to the queue, if the size of the queue is limited — immediately answers with a 429 error
The queue is cleared at the end of the queue to make sure that the freshest request gets a response as fast as possible, since the first request in the queue has most likely already expired and has closed or reloaded the page (I cannot remember the link to the source).
429 error — not an optimal answer, but it can be improved!
At application balancer level, we can handle 5xx and 429 errors and give something useful — more about that later.
Fallback page cache
For public pages that care about SEO, a very cool solution would be to save these pages in some sort of cache, and give them back to the user when a 429 response from the app.
A number of conditions must be met before a page can be saved to the cache:
The request should be without cookies and any personalisation (e.g. custom headers)
No need to cache 5xx responses, but 404 and redirects are something to think about
The cache key should include the url, request method, device type (desktop/mobile) and other conditions that are specific for you
Who can make a request like that:
A standalone service — crawler that will walk the app pages on a regular schedule
Applications themselves can save responses to the conditions above, or generate background requests when the cache is empty
You will end up with a HTML fallback and a switcher to that fallback, also the scheme can be further complicated and store the cache somewhere remotely rather than in application/balancer/crawler memory.
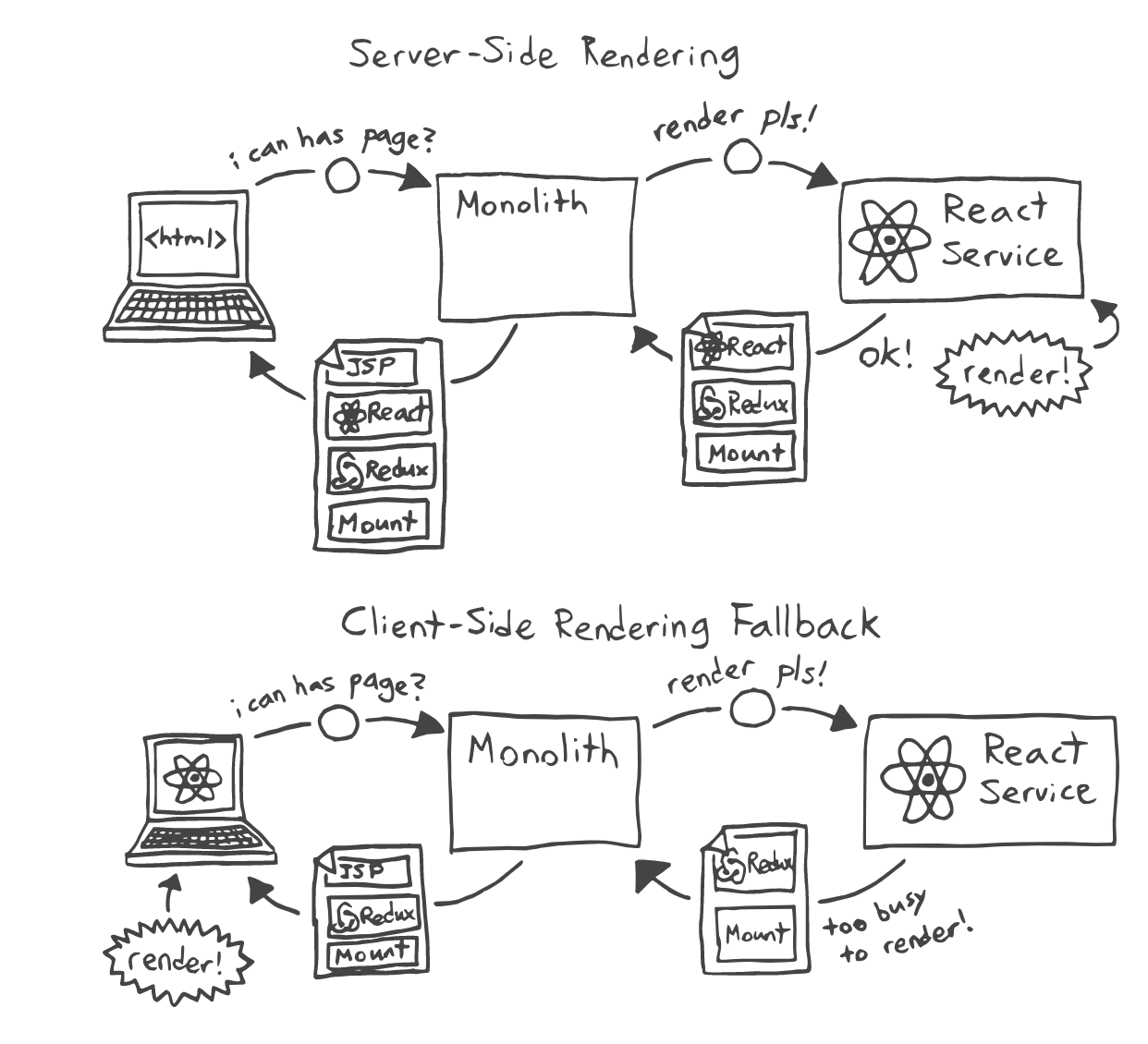
Client-side rendering fallback
One of the most robust features that our applications use is the generation of a single HTML fallback using the SSG mechanism of the tramvai framework.
The beauty of this approach is that the CSR fallback can run on any application url, as long as it has the basic scripts and styles — and the application can load the rest anyway, as with SPA transitions.
Same mechanism on the balancer, on 5xx and 429 errors, if no fallback cache is found, can give CSR fallback.
It is best used on applications that are closed with authentication, so as not to degrade SEO, but most importantly, the application remains functional in any case.
Clustering and Workers
A topic we have explored in part, there are a number of problems and questions:
fork the process before rendering — child_process.fork creates a separate process, memory sharing is not allowed
worker_thread allows partial memory sharing, a small set of objects — the rest must be serialized
cluster module where we have a master process will work as a request limiter, but is this better than balancing at the Kubernetes level?
On this topic in particular, I would like to hear your feedback!
Pairs Of Pages
Evolving toward this capability in a legacy application requires patience. A big-bang rewrite of the front-end, in addition to being incredibly risky, is usually off the table because it is a very expensive prospect. A long-term, incremental strategy is therefore required.
I think it makes sense to conceive of this problem in terms of pairs of pages. Imagine a simple, e-commerce website, with home, search results, and individual product pages.

If you upgrade both the home and search results pages to take advantage of isomorphic rendering, most users will hit the homepage first and can therefore render the search results page entirely within the browser. The same is true for the search results and product page combination.

But it’s easy to miss out on these strategic pairings. Let’s say your search results page is where all of the money is made, and so the product team is hesitant to modify it. If we invest our time into improving the home and product pages, making them isomorphic in the process, we won’t see much uptake in client-side rendering. This is because in order to get from the homepage to a product page, most users will navigate through a search results page. Because the search results page is not isomorphic, a server-side render will be required. If we’re not careful, it’s easy to perform a kind of inverse Pareto optimization, investing 80% of the resources to achieve only 20% of the gains.

Conclusion
These optimisations are probably not the only possible ones, but we have tried/integrated them all into our applications.
Share your options for optimizing and scaling SSR applications!
A huge thanks to all the colleagues who debugged / profiled / studied / developed / monitored all these optimisations on various tinkoff.ru applications, you are oh-so-cool!
And thank you for your reading!
Subscribe to my newsletter
Read articles from Redha Bayu Anggara directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Redha Bayu Anggara
Redha Bayu Anggara
Software Engineer