AWS DeepRacer - Quick Overview
 Matej Zamecnik
Matej ZamecnikLately, I have been thinking about gaining some new interesting experiences. When I received an invitation to participate in the 2023 AWS DeepRacer Grand Prix at my company, I was instantly in 'Let's try it' mode.
What is DeepRacer?
AWS DeepRacer is a fully autonomous 1/18th scale race car driven by reinforcement learning.
How to start?
I decided to go through AWS SkillBuilder training - duration 4h30m. I received 5h of compute time to train the model. First of all
Theory
Reinforcement learning (RL)
Continuously improves its model by mining feedback from the previous iteration
the agent learns by trial and error
Learn from its mistakes
The agent is the entity that exhibits a certain behavior (action) based on its experience interacting with the environment around it (see the picture below).
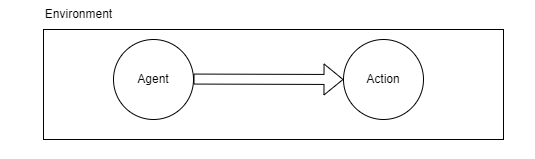
Action
discrete (move left, right, ...)
continuous (fluctuating speed, ...) It causes the environment to go from state to new state.
If the agent sees the entire env at once or not -> Partial state (see only the obstacle in front of the agent) / Absolute state
Based on the new state after performing the action the agent gets scaler value (Reward) from the environment. Earning these points helps the agent to perform in the future. It wants to be rewarded.
It is a looping process of actions and rewards (see the picture below), and it is called the task. It is continuous or discrete.
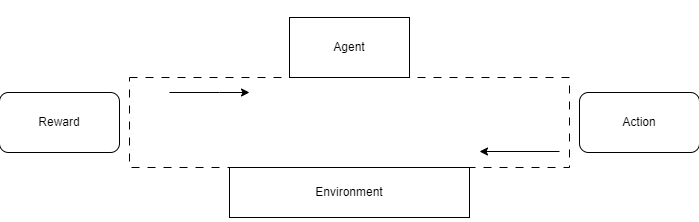
Discount factor
The goal of the RL algorithm is to maximize the sum of rewards → discount factor gamma (hyperparameter)
If the discount factor is 0, the agent wants to maximize the reward in the short term. It only cares about one obstacle at a time. On the other hand, the discount factor set to 1 is looking further ahead.
Discount factor is important in continuous problems.
Policy
It is the mapping between actions and states. It is the place where all the information about actions and rewards is stored. If this state, take this action. If another state, take another action.
Policy can be modeled in two ways:
Stochastically - includes the probability of taking the action.
Deterministically - direct mapping between state and action.
During the training process of the RL model is the goal to learn the most effective policy to maximize rewards.
Deep RL = policy action is a neural network
How to evaluate the policy? Through Value function - what actions to take to maximize the rewards in the long term. Expected sum of rewards.
AWS DeepRacer uses the PPO (Proximal Policy Optimization) algorithm to train the model. It is very efficient. It uses neural networks:
Policy network - decides which action to take given images and input
Value network - estimates accumulate results we are likely to get given these images and input.
So basically, we need to create the most optimized RL model to win the race.
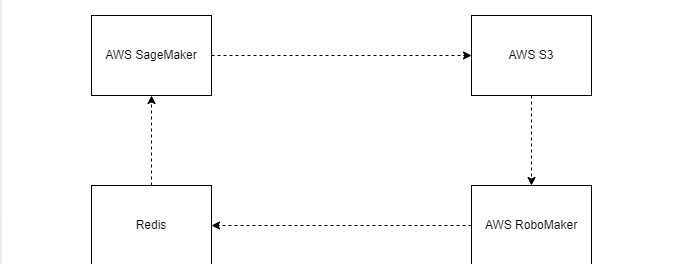
AWS SageMaker - used to train the RL model
AWS RoboMaker - used to create a virtual environment
SageMaker notebook integrates the RL algorithm that produces the model. A persistent copy of this model is stored in S3. This is brought into the simulation using Gazebo (simulates the law of physics). As interactions between agent and environment unfold, that experience data is collected and stored in Redis (in-memory database). And this is a continuous cycle.
Optimization is not done just by training and interaction between SageMaker and RoboMaker. There are additional parameters (internal to the models) and hyperparameters (external to the model, set by humans).
We don’t know the best values of hyperparameters, it is trial and error.
The way this RL learns something is by rewards and rewards function.
To train the best model possible, we need to find the appropriate combination of hyperparameters and reward function.
Reward function
Which action should be rewarded or penalized? The challenge is to define a reward function that covers factors defined by hyperparameters.
Basic function - includes just one hyperparameter
Advanced function - includes more than one hyperparameter
The function is written in Python.
Hyperparameters
Set by humans to improve lap times. There isn’t one single way to set them.
Important hyperparameters are:
Batch size
- Defines how much your training data should work through before each new update. How many images will be used for training?
Number of epochs
How many times the algorithm will pass through the batch data set before updating the training weights?
Increase the number of epochs until the validation accuracy is minimized.
Learning rate
- Controls the speed at which the algorithm learns. The time in between weight updates. The too-large rate might prevent finding the optimal solution.
Exploration
Gives the option to find the balance between exploitation (decision based on info which algo already has) and exploration (when algo gathers new info).
Very important.
Entropy
- Controls the degree of randomness of action (exploration)
Discount factor
Specifies how much of the future reward contributes to the expected rewards
smaller = agent only considers immediate rewards
larger = agent looks further into the future to consider rewards
Loss type
how algo gradually changes from random action to strategic action to increase rewards.
Huber Loss - small updates
Mean Square Error Loss - larger updates (train faster)
Episodes
- how many times you will go through the loop of learning in the training?
I will experiment with hyperparameters and reward function and soon come back here with my findings.
Subscribe to my newsletter
Read articles from Matej Zamecnik directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Matej Zamecnik
Matej Zamecnik
Oracle DBA | SQL | Cloud & Data Architecture