Big Data - 5
 Vishesh Raghuvanshi
Vishesh Raghuvanshi
Mining Social Network Graphs
What is social network graph mining
Social network graph mining involves analyzing the structure of a social network to discover useful patterns and information. It typically involves:
Representing the social network as a graph
Analyzing the graph structure using techniques like:
Clustering to find densely connected groups
Centrality measures to identify important nodes
Pathfinding to determine the shortest paths between nodes
Recommendation systems based on network structure and node attributes
Visualizing the graph to gain insights
The goal is to gain useful insights from the network structure that can help with applications like:
Recommending friends or connections
Detecting communities
Finding influential users
Predicting the spread of information
Applications of social network analysis
Some applications of social network graph mining include:
Recommendation systems - Recommending friends, groups to join, pages to follow based on your network
Viral marketing and influence analysis - Identifying influential users who can help spread information or products
Detecting communities and subgroups - Helping users find others with similar interests
Fraud detection - Identifying suspicious patterns in transaction or communication networks
Job recommendations - Recommending jobs to users based on their network of connections
Predicting the spread of information - Understanding how information and ideas spread through the network
Expertise location - Identifying experts in particular domains based on their connections
Social Networks as a Graph

Nodes represent actors
In a social network graph, nodes typically represent:
Individual people
Groups
Organizations
Pages
Any entity that has relationships with other entities in the network
Edges represent relationships
Edges between nodes represent some type of relationship between the actors. For example:
Friendship
Collaboration
Membership
Following
Communication
Edges can be either directed or undirected depending on the type of relationship.
Weighted and directed graphs

Social network graphs are often:
Weighted - Edges have weights that represent the strength or frequency of the relationship.
Directed - Relationships have a direction. For example, followers on Twitter form a directed relationship.
For example:
An edge from A to B with weight 5 represents that A follows B 5 times.
An edge from A to B without a weight simply indicates that A follows B.
Types of Social Networks
There are many different types of social networks based on their purpose and relationships:
Social networking sites
These are general-purpose social networks like:
Facebook - Based on friend connections
Twitter - Based on follower connections
LinkedIn - Based on professional connections
They allow people to connect, and share updates and media. Relationships are often undirected (friends) but can be directed (followers).
Collaboration networks
These networks are based on collaboration between people. Examples are:
Co-authorship networks - Nodes are authors, and edges represent co-authored papers.
GitHub - Nodes are developers, and edges represent collaboration on projects.
These networks typically have weighted edges to represent the strength or frequency of collaboration.
Information networks
These networks are based on the sharing or consumption of information. Examples are:
Citation networks - Nodes are research papers, and edges represent citations.
Reddit - Nodes are users, and edges represent replies/comments between users on posts.
They often form directed graphs since information/content flows in a particular direction.
Other types of social networks:
Communication networks - Based on calls, messages between people
Affiliation networks - Based on membership in organizations
Transaction networks - Based on financial transactions between entities.
Clustering of Social Graphs
Clustering social network graphs aims to detect densely connected groups of nodes, also known as communities. This can help reveal the underlying group structure in the network.
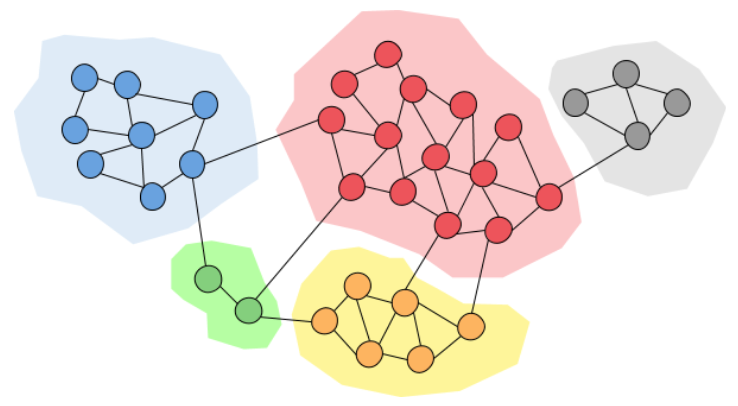
Some common algorithms for community detection in graphs are:
Community detection algorithms
Modularity optimization - Finds communities by maximizing the modularity score of the partition.
K-clique percolation - Finds communities as the union of all k-cliques that can be reached through adjacent k-cliques.
Label propagation - Starts with each node in its community and then nodes adopt the label that most of their neighbors have.
Spectral clustering - Transforms the graph into a lower dimension and then applies clustering in that space.
Clique percolation - Finds communities as the union of all cliques that can be reached through adjacent cliques.
These algorithms detect non-overlapping communities, where each node belongs to one community.
Overlapping and Hierarchical Communities
However, in many networks:
Nodes can belong to multiple communities (overlapping communities).
Communities can exist at different levels in a hierarchy.
For example, in a collaboration network:
A researcher can belong to multiple research groups.
Research groups can form departments, departments can form institutions, etc.
So more advanced algorithms can detect:
Overlapping communities - Where a node can belong to multiple communities.
Hierarchical communities - Communities at different levels, forming a dendrogram.
Direct Discovery of Communities
There are several algorithms for directly discovering communities in a social graph without any prior information:
Centrality measures
Centrality measures like degree centrality, betweenness centrality and closeness centrality can help identify important nodes that are likely in the centre of communities.
These central nodes can then be used as seeds to grow communities.
For example:
Nodes with a high degree of centrality are likely hubs within a community.
Nodes with high betweenness centrality act as bridges between communities.
Clique percolation method
This method looks for fully connected subgraphs called k-cliques in the graph.
Then it forms communities by:
Finding all k-cliques
Joining two k-cliques that share k-1 nodes
Repeating this process to grow communities
This forms non-overlapping communities.
Label propagation
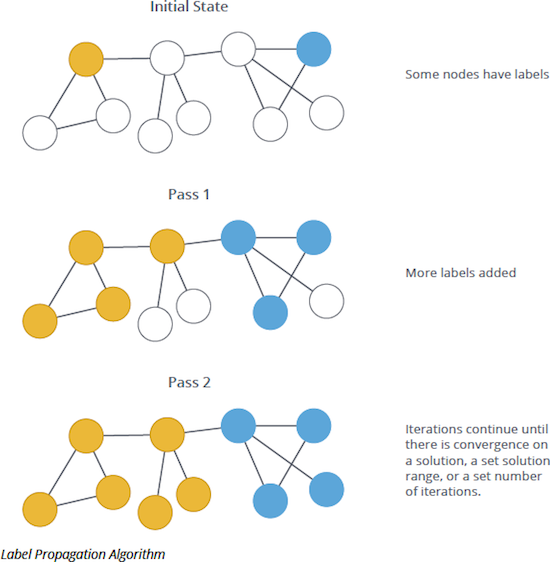
This is a simple and efficient algorithm. It works as follows:
Assign each node a unique label initially
Each node adopts the label that most of its neighbors have
Repeat step 2 until stability (nodes keep their label)
Nodes with the same label at the end form a community.
This forms non-overlapping communities.
Recommender Systems
Recommender systems are software tools and techniques that provide suggestions for items that a user may like. They have become ubiquitous in applications like e-commerce, media streaming, news etc.
There are three main approaches to building recommender systems:
Content-based recommendations
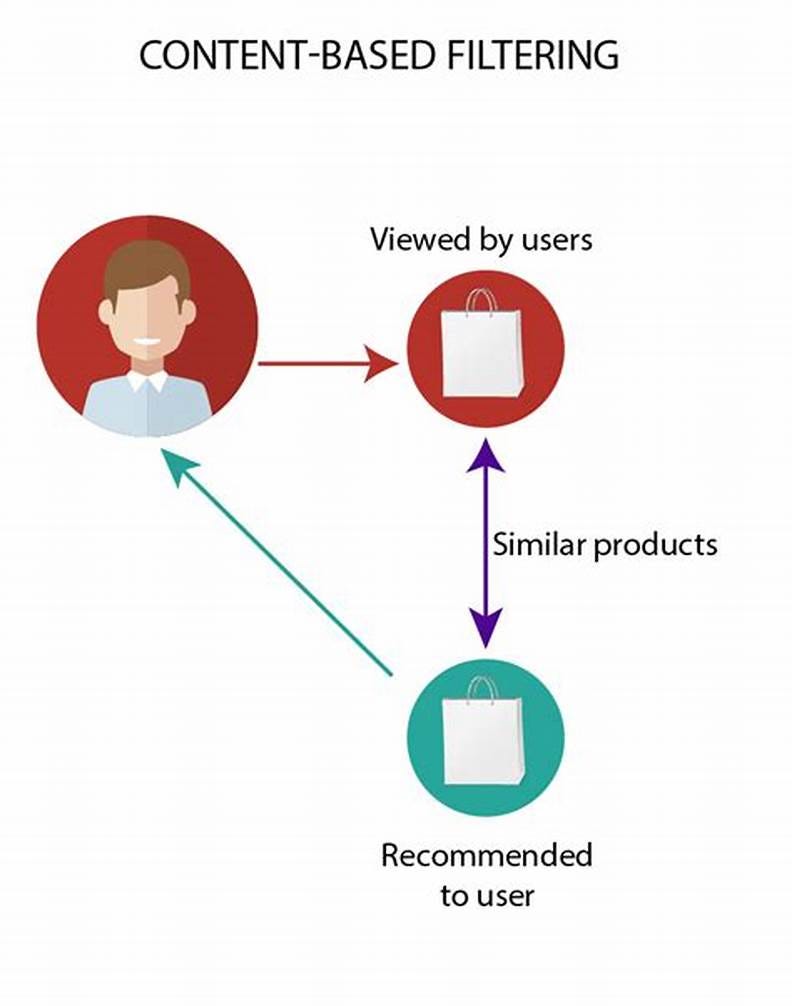
These recommend items similar to what a user has liked in the past. They work as follows:
Create profiles of items based on attributes (genre, author etc)
Create profiles for users based on items they have liked
Match new items to users based on similarity between item and user profiles
Advantages:
New users can be recommended items
Recommendations are explainable
Disadvantages:
Limited to item attributes
Does not discover new correlations
Collaborative filtering
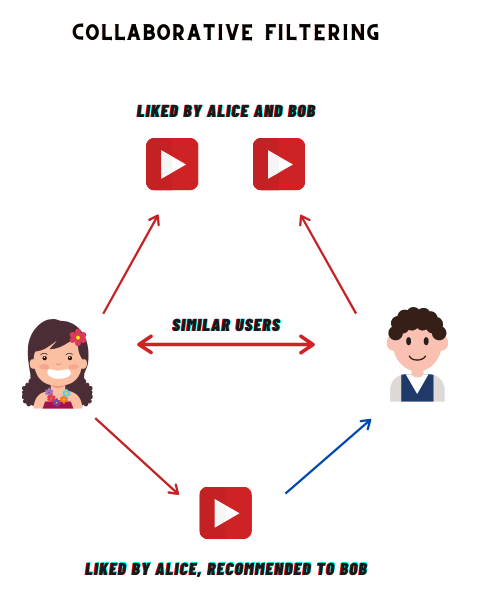
These recommend items that people with similar tastes and preferences have liked in the past. They work as follows:
Collect user preferences (ratings, purchases etc)
Find similar users based on item preferences
Recommend items that similar users have liked and the current user has not seen yet
Advantages:
High accuracy since based on real user preferences
Discovers new correlations not evident from item attributes
Disadvantages:
Cannot recommend to new users
Requires a large amount of user preference data
Hybrid recommender systems

These combine the content-based and collaborative filtering approaches to get the best of both worlds. They:
Use content-based recommendations to bootstrap recommendations for new users
Then incorporate collaborative filtering as more user data becomes available
This hybrid approach can overcome some limitations of each technique.
Building Recommender Systems
The process of building a recommender system typically involves the following steps:
Data collection and preprocessing
The first step is to collect the relevant data. This includes:
Item data: attributes, descriptions, categories, etc.
User data: profiles, preferences, demographic info, etc.
Interaction data: ratings, purchases, likes, follows, etc.
This raw data then needs to be preprocessed:
Clean missing or invalid values
Encode categorical attributes
Normalize numeric attributes
Split into training and test sets
Model training
After the data is ready, a recommender model is trained on the training set. This involves:
Choosing a recommendation approach: content-based, collaborative filtering or hybrid
Selecting a suitable algorithm: kNN, matrix factorization, neural networks, etc.
Training the model by finding patterns in the user-item interactions.
This results in a trained model that can make recommendations.
Making recommendations
Once the model is trained, it can be used to:
Generate a ranked list of recommendations for each user
Compute recommendation scores for unseen items
Provide real-time recommendations as users interact with the system
The recommendations can then be evaluated using various metrics on the held-out test set.
Challenges in Social Network Analysis
There are several key challenges in analyzing social networks and building applications based on social data:
Data sparsity
This refers to the fact that users typically interact with or rate only a small subset of all available items. This makes it difficult to find meaningful patterns and correlations in the data.
Data sparsity can be addressed by:
Collecting more user interaction data over time
Incorporating side information like item attributes, user profiles, etc.
Cold start problem
This refers to the difficulty of recommending items to new users or items that have no interaction data. Since there are no preferences to base recommendations on, cold start is a major challenge.
It can be addressed by:
Using content-based recommendations initially
Bootstrapping from similar users' preferences
Incorporating implicit feedback when explicit feedback is not available
Privacy and security
Social network data contains sensitive information about users, their connections and activities. This raises privacy and security concerns.
Some issues include:
Unauthorized access to data
Identifying users based on anonymized data
Inferring private attributes from public data
Misuse of recommendations for manipulation
Solutions require:
Secure data storage and access control
Anonymization techniques
Privacy-preserving algorithms
Transparency about data use and clear policies
Applications of Social Network Analysis
Social network analysis has many useful applications in business and research:
Customer segmentation
By analyzing the connections and interactions between customers in a social network, businesses can gain insights into natural customer groups or segments. This allows them to:
Tailor products and services to specific segments
Target marketing campaigns more effectively
Improve customer experience and loyalty

Fraud detection
By looking for suspicious patterns in social networks, fraud and criminal activity can be detected. For example:
Identifying rings of accounts engaged in fraudulent activities
Detecting money laundering networks
Uncovering identity theft syndicates
Market research
By studying social networks, businesses can gain valuable insights into:
Emerging trends and popular topics
Customer opinions and sentiments about products/brands
The diffusion of new products and ideas through the network
This allows them to innovate and adapt to the market more quickly.
Some other applications of social network analysis include:
Measuring influence and recommending influencers
Improving team performance through network analysis
Detecting the spread of misinformation and rumors
Mapping the spread of diseases through communities
Subscribe to my newsletter
Read articles from Vishesh Raghuvanshi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by