How to fine-tune a Large Language Model
 Saurav Navdhare
Saurav Navdhare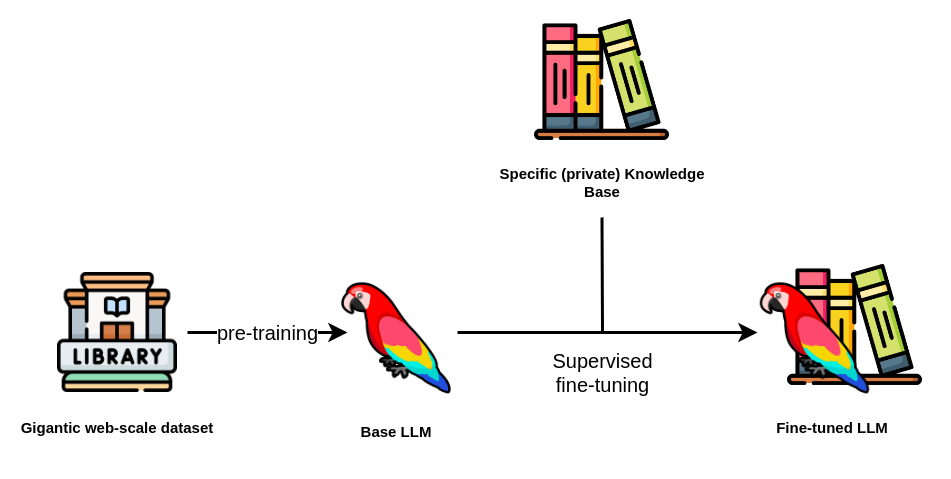
Overview
In this blog post, we have explored the concept of tuning Large Language Models (LLMs) and their significance, in the field of Natural Language Processing (NLP). We have discussed why fine-tuning is crucial explaining how it allows us to adapt trained models to specific tasks enhance their performance reduce data requirements and enable customization.
Additionally, we have provided a tutorial on the process of tuning a trained Large Language Model.
As the field of NLP continues to progress the flexibility offered by tuned LLMs has the potential to revolutionize how we engage with and leverage language models. Whether it's chatbots or industry-specific applications fine tuning opens up possibilities.
The future of NLP looks promising with fine tuning serving as the key that unlocks its potential. It empowers us to tailor language models according to our needs making them tools as we strive for advanced understanding and application of human language.
Introduction
Large language models have evolved as veritable powerhouses in natural language processing and artificial intelligence, capable of comprehending, creating, and translating human language. GPT-3, GPT-4, and BERT models, for example, have been the foundation of innumerable applications ranging from chatbots and virtual assistants to language translation. But how do we train these pre-trained behemoths to do miracles for specific, real-world tasks?
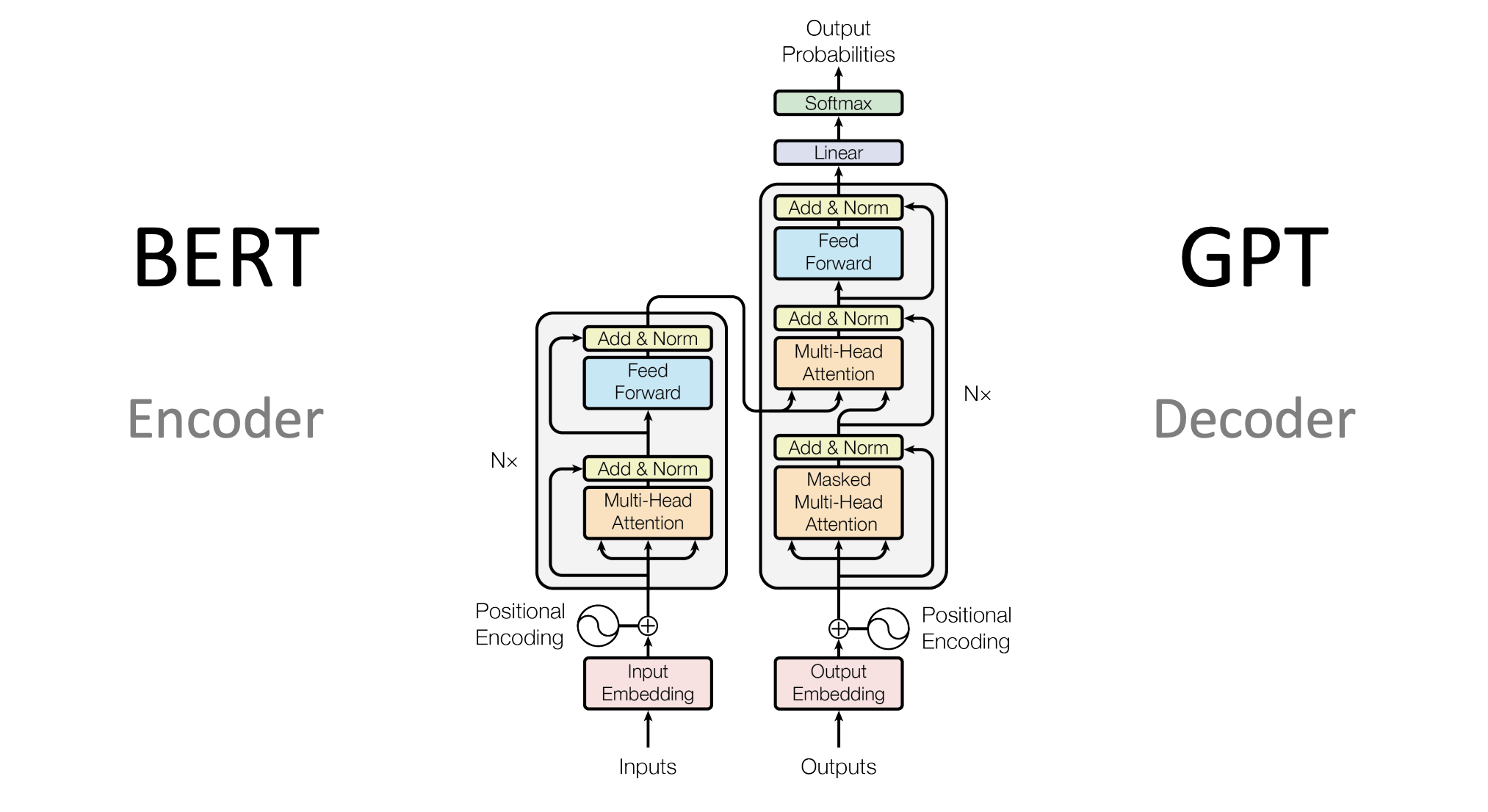
The answer can be found in the art of fine-tuning. The process of customizing these pre-trained language models to handle tasks ranging from text classification to question answering is known as fine-tuning. The magic wand turns these general-purpose language models into domain specialists, ready to manage your application's unique difficulties. In this compact book, we'll go into the fundamentals of fine-tuning, examining the methods, tactics, and recommendations that might assist you in realizing the full potential of huge language models. So, if you're ready to learn how to make these linguistic behemoths work for you, join me on this adventure into the world of fine-tuning.
What is Fine-Tuning?
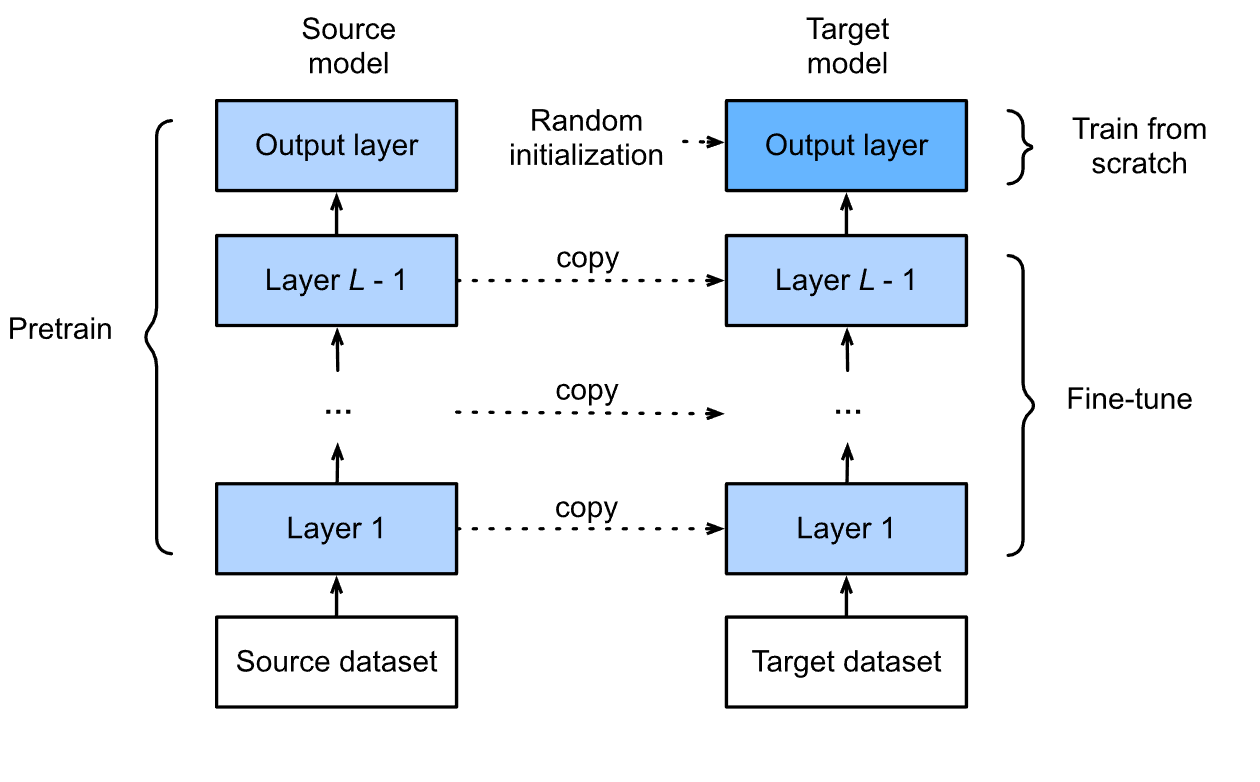
Fine-tuning entails modifying the parameters of a pre-trained model to tailor it to a specific job. Instead of training the model from scratch on a big text corpus, we start with a pre-trained model and fine-tune it for particular tasks like sentiment analysis, text production, and document similarity detection. In this manner, we may harness the model's previous expertise and adjust it to our specific purpose. Later in this post, we will go over fine-tuning a Large Language Model in greater depth.
Prompting is a simple but sophisticated strategy for instructing a language model. It entails supplying a specific context or cue to the model, which acts as the foundation for the tasks the model is intended to do. Consider teaching a detailed chapter from a child's textbook, providing a complete and explicit explanation, and then asking them to answer problems relevant to that chapter.
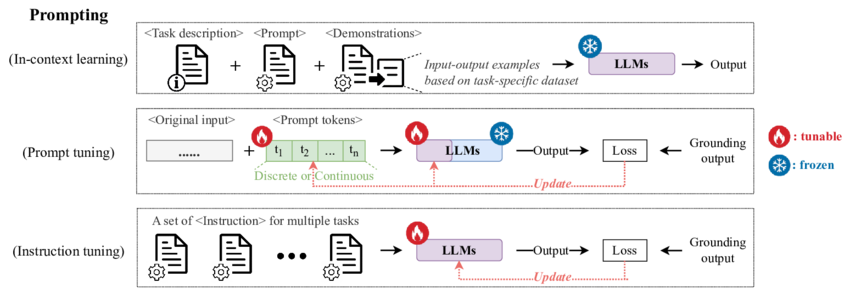
You construct a context and offer instructions to the model to guide its response in the context of Large Language Models (LLM), such as ChatGPT. Assume you wish to utilize ChatGPT to generate interview questions regarding Transformers. To improve the experience and assure accurate output, create a clear and thorough context while fully describing the task you want the model to do. As a result, the model can better comprehend your purpose and create appropriate information.
For example: "I am a software developer at a startup that specializes in autonomous drones." We're ready to give a presentation to a possible investor who is interested in our technology. I want to impress them with my expertise in drone technology and its applications. "Ask me five difficult questions about drone technology and provide detailed answers to each."
In this scenario, you're preparing for a dialogue in which the language model will ask you questions about drone technology and deliver thorough replies. This method allows you to engage the model in a simulated interview or debate on a specific topic, obtaining information and insights relevant to your needs.
The more specific and detailed your prompt, the better the outcomes. The most enjoyable aspect is that you can generate the prompt from the model itself and then add a personal touch or the necessary information.
Why Fine-tune LLMs?
Fine-tuning Large Language Models (LLMs) is a crucial step in utilizing these models effectively for specific tasks. There are several reasons to fine-tune LLMs:
Task-Specific Adaptation: LLMs are designed to be versatile and understand general language. However, to excel in specific tasks such as sentiment analysis, question-answering, or text generation, fine-tuning is essential. This process tunes the model's parameters to align with the nuances of the task, making it more proficient in generating contextually appropriate responses.
Improved Performance: Fine-tuning enhances the model's performance by fine-tuning the pre-trained weights on your particular dataset. This ensures that the model becomes better at solving the exact problem you are interested in. The result is higher accuracy and efficiency in task-specific applications.
Reduced Data Requirements: Fine-tuning often requires a smaller amount of task-specific data compared to training a model from scratch. The pre-trained LLM already contains a wealth of general language knowledge, reducing the need for extensive task-specific data collection. This is especially valuable for tasks with limited available training data.
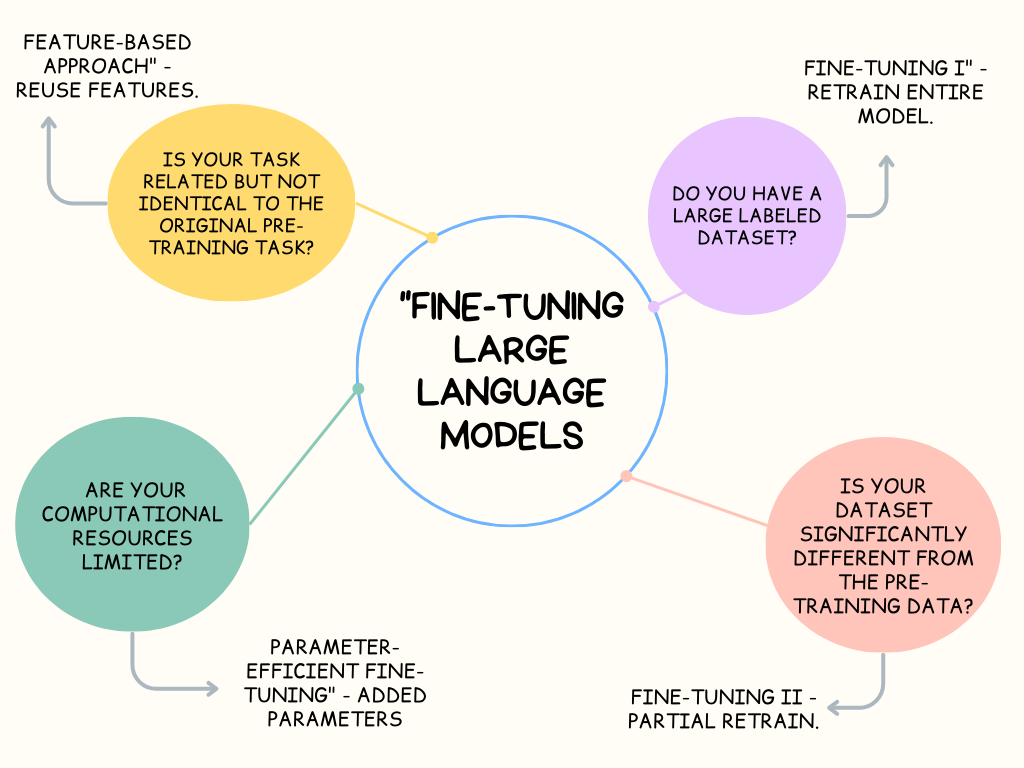
Efficiency: Training a large language model from scratch is computationally expensive and time-consuming, as it involves optimizing millions of parameters. Fine-tuning builds on the existing knowledge in the pre-trained model and only adjusts a subset of parameters, making it computationally efficient and less resource-intensive.
Domain Adaptation: Fine-tuning allows the model to adapt to specific domains or industries. For instance, if you are working in healthcare, fine-tuning the model on medical texts helps it understand medical jargon and context, resulting in more accurate and domain-specific responses.
Customization: You can instruct the model to follow specific guidelines or generate content in a certain style. For example, in chatbot applications, you can fine-tune the model to be more formal or informal based on your requirements, making it highly customizable.
Reduced Bias: By providing task-specific data and guidelines during fine-tuning, you can have more control over the model's output and mitigate any unwanted biases present in the pre-trained model's responses. This is crucial for ethical and unbiased AI applications.
Fine-tuning LLMs is essential for tailoring these models to specific tasks, enhancing their performance, reducing data requirements, and achieving efficient and versatile natural language processing applications. It allows you to harness the power of pre-trained models for your unique needs while minimizing the effort and resources required for model development.
Let's Dirty our hands a bit.
Selecting a Pre-trained Model:
Before diving into fine-tuning, it's crucial to choose the right pre-trained model. The choice of model depends on your specific task and domain. Models like BERT, GPT-3, and RoBERTa are popular choices, known for their excellent performance across various natural language processing (NLP) tasks. Here we are using `vilsonrodrigues/falcon-7b-instruct-sharded` model
Data Preparation:
Data preparation is a foundational step in fine-tuning. You'll need high-quality, labeled data for your target task. This may involve cleaning, formatting, and splitting your data into training, validation, and test sets. The better your data, the better your model's performance.
Fine-Tuning Process:
The fine-tuning process generally involves the following steps:
Loading the pre-trained model.
Adapting the model's architecture for your task.
Training on your specific data.
Fine-tuning hyperparameters.
Gradient checkpointing is a technique used during training to reduce memory consumption, making it possible to fine-tune larger models even with limited hardware resources.
Introducing PEFT:
PEFT (Parameter Efficient Fine-Tuning) is a powerful library that simplifies the fine-tuning process. It provides tools and functions for setting up a fine-tuning pipeline and can be seamlessly integrated with popular pre-trained models
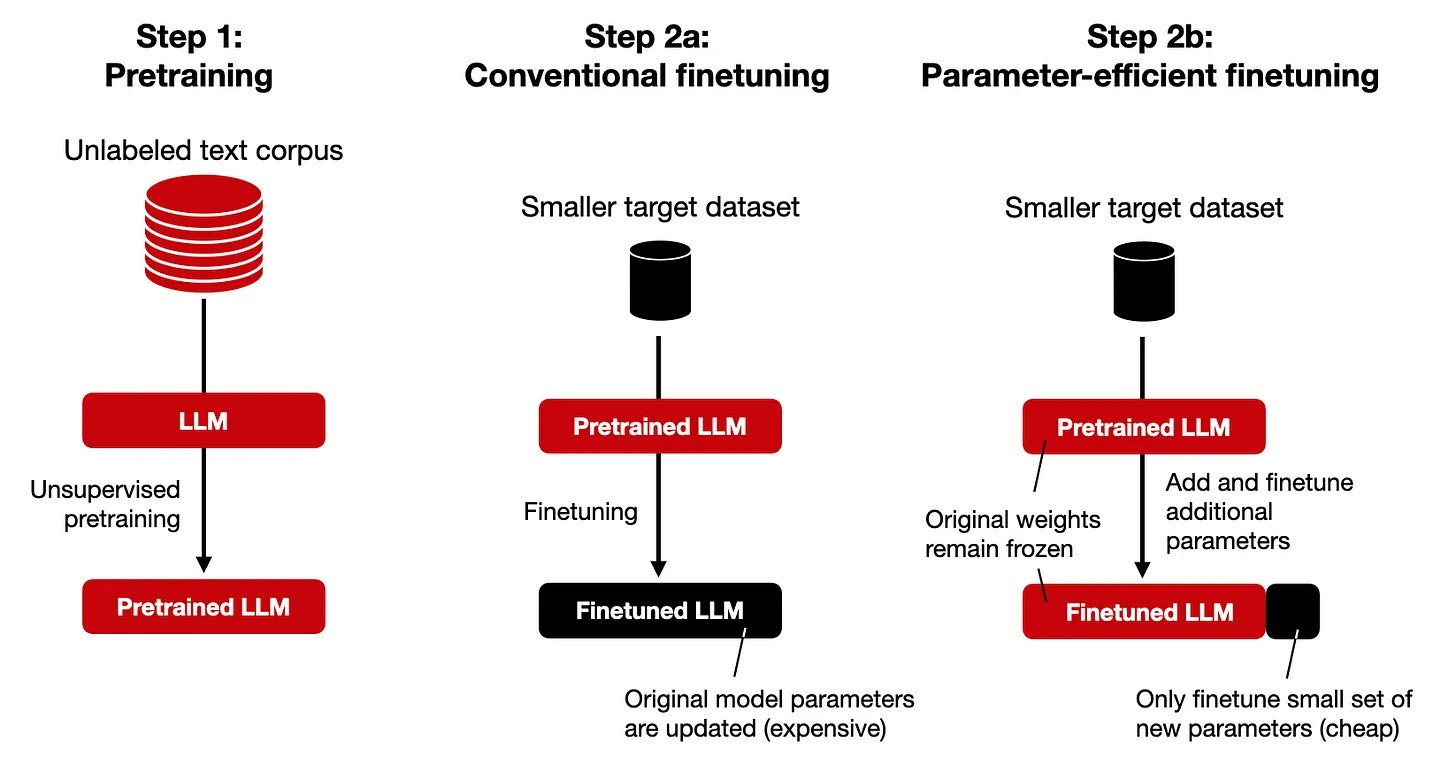
So let us fine-tune falcon-7b model using truthful_qa_generation_ita dataset. So open up your google-colab notebook and follow the below steps
Install the following libraries
!pip install -q -U bitsandbytes
!pip install -q -U git+https://github.com/huggingface/transformers.git
!pip install -q -U git+https://github.com/huggingface/peft.git
!pip install -q -U git+https://github.com/huggingface/accelerate.git
!pip install -q -U einops
!pip install -q -U safetensors
!pip install -q -U torch
!pip install -q -U xformers
!pip install -q -U datasets
Import them
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, pipeline
import transformers
import torch
from torch.utils.data import DataLoader, Dataset
import torch
from transformers import AutoTokenizer
Load Quantized Model
model_id = "vilsonrodrigues/falcon-7b-instruct-sharded" # sharded model by vilsonrodrigues
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0}, trust_remote_code=True)
arm-up PEFT for finetuning
from peft import prepare_model_for_kbit_training
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
Let's define a function to print the parameters
def print_trainable_parameters(model):
"""
Prints the number of trainable parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
)
setting up the configuration (I will write a separate blog for this configuration so please stay tuned)
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["query_key_value"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)
print_trainable_parameters(model)
Loading the dataset
from datasets import load_dataset
data = load_dataset("truthful_qa", "generation")
tokenizer.pad_token = tokenizer.eos_token
# prompt_template = "### Instruction: {prompt}\n### Response:"
train_dataset = data['validation'].select(range(100)).map(lambda x: {"input_text": x['question'] + "\n" + x['best_answer']})
# Tokenize the datasets
train_encodings = tokenizer(train_dataset['input_text'], truncation=True, padding=True, max_length=256, return_tensors='pt')
Creating a class for the Dataset
class TextDataset(Dataset):
def __init__(self, encodings):
self.encodings = encodings
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item["labels"] = item["input_ids"].clone()
return item
def __len__(self):
return len(self.encodings["input_ids"])
Converting the encodings to Pytorch datasets
train_dataset = TextDataset(train_encodings)
Let us also define a function to generate the text and get the best possible answer from the dataset
def generate(index):
example_text = data['validation'][index]['question']
correct_answer = data['validation'][index]['best_answer']
print("Question:")
print(example_text)
encoding = tokenizer(example_text, return_tensors="pt").to("cuda:0")
output = model.generate(input_ids=encoding.input_ids, attention_mask=encoding.attention_mask, max_new_tokens=100, do_sample=True, temperature=0.000001, eos_token_id=tokenizer.eos_token_id, top_k = 0)
print("Answer:")
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("Best Answer:")
print(correct_answer)
print()
fine-tuning...
trainer = transformers.Trainer(
model=model,
train_dataset=train_dataset,
# eval_dataset=val_dataset,
args=transformers.TrainingArguments(
num_train_epochs=30,
per_device_train_batch_size=16,
gradient_accumulation_steps=4,
warmup_ratio=0.05,
# max_steps=100,
learning_rate=2e-4,
fp16=True,
logging_steps=1,
output_dir="outputs",
optim="paged_adamw_8bit",
lr_scheduler_type='cosine',
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
model.config.use_cache = False # silence the warnings. Please re-enable for inference!
trainer.train()
Evaluating the model
model.config.use_cache = True
model.eval()
generating the text
generate(0)
Conclusion
Finally, with the introduction of Large Language Models (LLMs) such as GPT-3, BERT, and others, the domain of Natural Language Processing has experienced a significant revolution. These models, which have been pre-trained on massive volumes of text data, possess an intuitive understanding of human language and have evolved into effective tools for various applications. However, fine-tuning is often necessary to unlock their full potential.
We can fine-tune these adaptable, pre-trained models to tailor them to specific tasks, industries, or domains. Fine-tuned LLMs enable us to deliver highly accurate and context-aware results in sentiment analysis, content generation, translation, and even domain-specific dialogues.
We examined a fine-tuning technique. As we advance in the field of NLP, the adaptability and flexibility of fine-tuned LLMs will be crucial in driving the technology to new heights. The possibilities range from chatbots to content recommendation systems. We can fine-tune these language models to meet our specific needs, making them valuable assets in our pursuit of realizing the full potential of human language understanding. NLP has a bright future, and fine-tuning is the key to unlocking its brilliance.
Subscribe to my newsletter
Read articles from Saurav Navdhare directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Saurav Navdhare
Saurav Navdhare
Aspiring machine learning engineer and full stack developer with expertise in artificial intelligence, blockchain technology, and building scalable web applications. Skilled in Python, JavaScript, Solidity, React, Node.js, TensorFlow, PyTorch, and Django. Passionate about leveraging AI and blockchain innovations to solve challenging real-world problems. Experience building and deploying deep learning models using TensorFlow and PyTorch for computer vision, NLP, and predictive analytics. Skilled in techniques like CNNs, RNNs, LSTM, transfer learning, and reinforcement learning. Adapt at explaining complex AI concepts and ML models to stakeholders. Proficient in developing full stack applications using React, Node.js, Express, and MongoDB. Familiar with web development best practices, APIs, databases, version control with Git, and hosting platforms like AWS and Heroku. Focused on writing clean, well-documented, and tested code. Strong communication, collaboration, and leadership skills honed through technical team projects and student organization leadership roles. Able to clearly explain complex technical concepts to non-technical audiences. Passionate about continuous learning and staying up-to-date on the latest technologies. Looking to join a collaborative team of developers to build innovative products that leverage cutting-edge technologies like artificial intelligence, machine learning, and blockchain. Excited to push my skills to the next level and have a positive impact while solving real-world problems.