Searching for a Python-based Speech Recognition Engine (for CPU Inference)
 Richard Thompson
Richard Thompson
To give my Ai learning a context to ground into, I'm writing a funny little app I've called VoxPlan (in Python) which allows you to organise goals and tasks in a hierarchical tree and display them in an interactive GUI.
I'm very interested in exploring Human-Computer Interaction and novel interfacing methods and in particular the idea of controlling computers with speech. I always expected operating systems to become voice-responsive sooner, and have always been very unimpressed with Siri and the other mobile phone-based voice apps.
As I write this, VoxPlan is still in its very early stages and I've yet to get it onto GitHub. But I've been reliably informed that this is the way to go and so I will get onto this when I can.
My idea is to find a way to gradually build different Ai technologies into VoxPlan as I learn about them, as a kind of learning sandbox.
Given its name, the most obvious place to start would be the ability to recognise voice commands and operate independently of the keyboard. As I've only implemented a few basic functions such as creating, editing and deleting a 'Goal Node,' you'd think this would be fairly easy to get going with.
Later, it would be cool for the app to be able to help with formulating goals and possibly even elaborating them so they're easier to visualise and map out sequentially. I imagine this would involve interacting with an established language model like Chat GPT.
Selecting a speech recognition model for my Python App
It appears there are currently a few ways to incorporate speech recognition into an application. There are some online services available which your app would use an API to interact with. Examples of these would be :
It's probably very good but it looks very corporate and you have to pay. It also looks like you need to be connected to the internet to use it. I want my application to work offline so that's another reason this isn't an option.
Another online API. The advantage of these paid services, I'm sure, is that they're very easy to implement and require very few lines of code to get going. I'm really looking for something open source though I think.
A List of Open-source Automatic Speech Recognition (ASR) Models
One of the reasons I've become so excited about AI is the sheer volume of open-source projects out there offering powerful capabilities for free and also providing access to their code. It's pretty amazing.
In terms of my requirements, I'm looking for the most accurate thing I can use, that can be accessed relatively easily from my Python program, and doesn't require any GPU to work, as I'm running everything on my Macbook Pro.
At the other end of the spectrum to the "pre-made" models above, is obviously training and fine-tuning your own transformer model. This is covered on the HuggingFace ASR page and is clearly way above my head for now. I'll be interested to look into this at a later date though!
It looks like there are a number of options where people have already done the training for me, and provided a useable API into their model. I figure if I can just get something working to start with, then when my use starts showing the weaknesses of what I'm using, I'll have to expand my knowledge to improve it!
The Kaldi Speech Recognition Toolkit looks like a comprehensive model and very well documented. It's a C++ library though and I'm not quite there yet!!
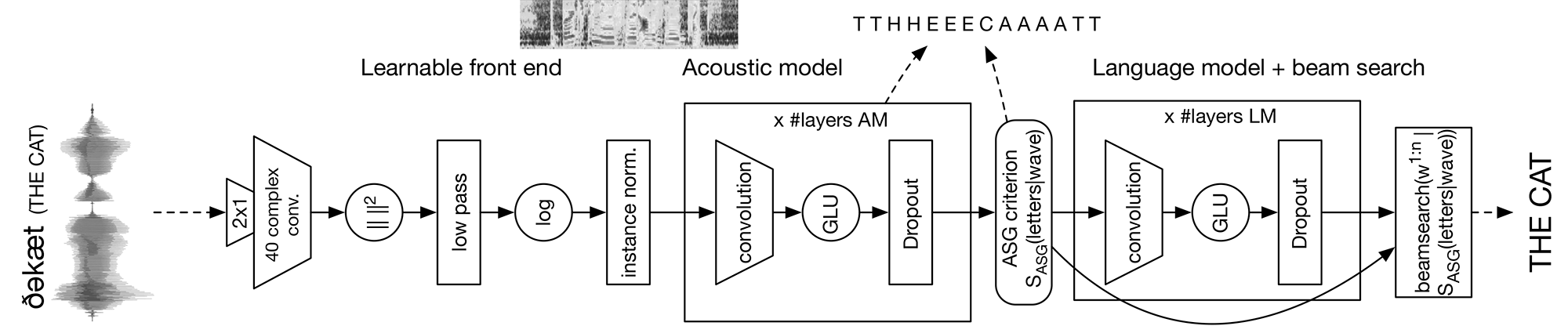
META's Wav2Letter++ Project is advertised as the fastest state-of-the-art end-to-end speech recognition system available. It uses convolutional neural networks apparently. I haven't learned what they are yet but it looks like they provide a more efficient pipeline for processing audio data. It's written in C++ and so again a bit over my head for now. I did write a neural network in C++ when I did a research assistantship placement at Carnegie Mellon Uni but that was a long time ago now, and I haven't gotten onto C++ again yet. The Wav2Letter++ speech recognition system is built on top of a more general-purpose machine learning library called Flashlight, which META has also made available, and looks to be able to run on either CPU or GPU inference.
Either way, their little diagram for how it works gives some idea of how complex the system is. I'm not smart enough yet to make sense of this, but it looks like the main processing happens between an acoustic model - assumedly based around the acoustic structure of the waveform - and the language model - probably based on a dictionary or possibly a more complex encoding of the structure of language. It would make sense that these would provide mutually constraining activation to lead to the final interpretation of the utterance.
Lightning Flash seems to be another deep learning framework, "for fast prototyping, baselining, finetuning and solving deep learning problems." It seems to create the functionality to do a variety of machine-learning tasks in Python. However, it seems to be more focused on training and fine-tuning a model to a specific set of data rather than using an existing model.
It uses another of META's open source engines, this time something called wav2vec 2.0, a model that seems to use unsupervised learning to derive structure from the acoustic form of language, before being trained how to label (i.e. convert speech to text) the data. This method apparently makes the training of the network much more efficient. From a CogSci perspective, this would mirror the human method of learning language, in that in the normal acquisition of language, we would first derive some sense of the structure of sounds before we can understand language, words, and their meaning.
While this seems very interesting, it's not immediately obvious how I would use this in my application.
DeepSpeech looks quite good and does have some Python bindings, but doesn't appear to have much helpful documentation to get me started.
I just stumbled on this: Coqui, a text-to-speech studio. Check it out - it looks like AI voice creation has been taken to a new level. It looks very cool. I shall be investigating their open-source text-to-speech engine later too. For completeness, I will mention that Coqui also has a speech recognition engine. While it looks quite cool, they're no longer maintaining it, so I'll keep looking for something else.
SpeechBrain looks to be a very comprehensive speech processing package that again is designed for training a model on your own data. I will look at this at a later date, when I want to get to the next layer of granularity in how speech-recognising networks work, and get them to work better.
I've discovered CMU Sphinx / Pocketsphinx. Their page has a tutorial which says it's intended for developers who need to apply speech recognition technology in their applications, not for speech recognition researchers. That's a good start. However, it does also say that modern toolkits such as the ones I've named above - Kaldi, Coqui, Nemo, wav2vec2, etc. will perform much , much better on larger vocabulary tasks. Hmm...
However, there is a tutorial on how to use the model along with a media pipeline library GStreamer to produce the kind of real-time speech interpretation I need.
Finally, we have whisper.cpp, a C++ port of OpenAI's Whisper Text to Speech engine. I'm pretty sure it allows what would otherwise be a GPU-only inference, to occur on a CPU, which is good for me. Attached to this but by a different author, is PyWhisperCpp, which seems to be a Python API into the program.
Now that I'm confident I've done a decent review of the options, I can look at implementing something. That's a task for another day though....
Conclusion
From the comments on the CMU Sphinx website, whisper.cpp would surely be more accurate. I like the idea of being able to implement the most accurate model available to me at my current level of knowledge.
So in the next article, I'll be playing around with implementing whisper.cpp via the PyWhisperCpp port / API interface.
Subscribe to my newsletter
Read articles from Richard Thompson directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Richard Thompson
Richard Thompson
Spending a year and a half re-educating myself as a Cognitive Scientist / Ai Engineer.