Transformers: Empowering Attention for Natural Language Processing.
 Dhrutinandan Swain
Dhrutinandan Swain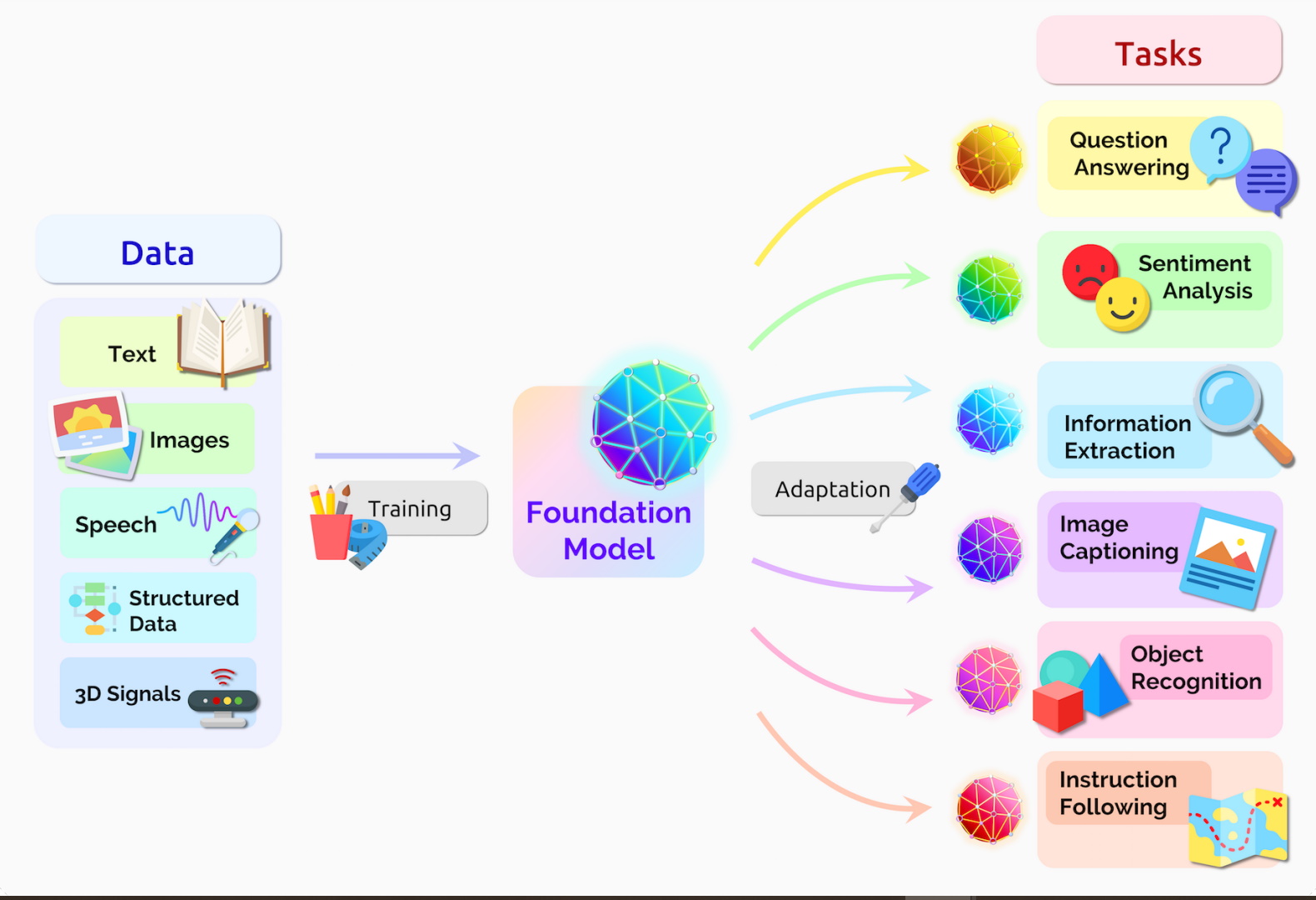
A Brief Introduction to Natural Language Processing
Natural language processing (NLP) is the field of artificial intelligence that deals with understanding and generating natural language, such as text and speech. NLP has many applications, such as machine translation, sentiment analysis, question answering, text summarization, and more.
However, NLP is also a challenging domain, as natural language is complex, ambiguous, and diverse. Traditional methods for NLP rely on hand-crafted rules or feature engineering, which are often brittle and limited in scope. Moreover, natural language is sequential, which means that the meaning of a word or a sentence depends on its context and order.
To overcome these challenges, deep learning models have been developed that can learn from large amounts of data and capture the semantic and syntactic patterns of natural language. Among these models, one of the most powerful and influential ones is the transformer model.
What is a transformer model?
A transformer model is a neural network that learns context and understanding by tracking relationships in sequential data like the words in this sentence. Transformer models use a modern and evolving set of mathematical techniques, called attention or self-attention, to detect subtle ways even distant data elements in a series influence and depend on each other.
The transformer model was first proposed in 2017 by Google researchers in a paper titled “Attention Is All You Need”. It is notable for requiring less training time than previous recurrent neural architectures, such as long short-term memory (LSTM), and for being able to process input sequences in parallel, which enables faster and more scalable inference.
Since then, transformer models have been widely adopted and improved for various NLP tasks, such as machine translation, text generation, text summarization, sentiment analysis, question answering, and more. Some of the most popular transformer models are BERT, GPT-3, T5, XLNet, etc.
Working on a Transformer model
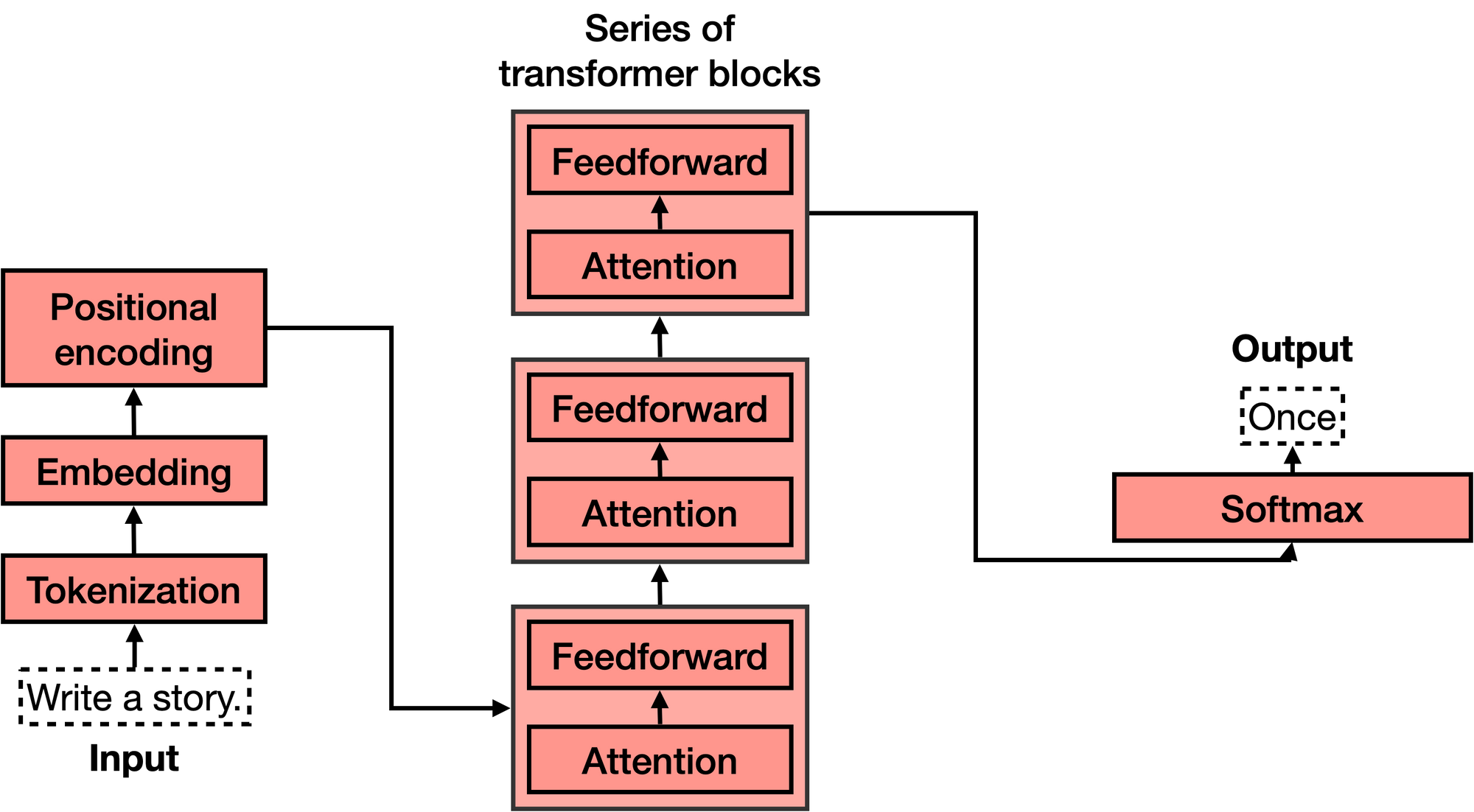
A transformer model consists of two main components: an encoder and a decoder. The encoder takes an input sequence of tokens (such as words or subwords) and transforms it into a sequence of vectors that represent the meaning and context of each token. The decoder takes the encoder output and generates an output sequence of tokens (such as words or subwords) that is relevant to the input sequence.
Both the encoder and the decoder are composed of multiple layers of sub-modules called attention layers. An attention layer is a mechanism that allows the model to focus on different parts of the input or output sequence depending on the task. For example, in machine translation, an attention layer can help the model align the source and target languages by paying more attention to the words that are related.
There are different types of attention layers, such as self-attention, cross-attention, multi-head attention, etc. The main idea behind attention is to compute a weighted sum of the input or output vectors based on their similarity or relevance. This way, the model can learn to capture long-range dependencies and complex relationships among the tokens.
Importance of Attention in Transformer Models
Attention is a key concept that enables transformer models to achieve superior performance on various natural language processing tasks. Attention allows the model to selectively focus on different parts of the input sequence when making predictions, rather than treating the entire sequence as a fixed-length vector. This has been a key factor in the success of the transformer and has inspired a wide range of follow-on research and new models.
Attention also helps the model to capture long-range dependencies and complex relationships among the tokens in the input sequence. For example, in machine translation, attention can help the model align the source and target languages by paying more attention to the related words. Attention can also help the model handle different types of input sequences, such as words, subwords, characters, or even images.
Attention is not only useful for encoding the input sequence but also for decoding the output sequence. By using attention, the model can generate more coherent and relevant outputs that are conditioned on both the input sequence and the previous outputs. For example, in text generation, attention can help the model avoid repetition and maintain consistency.
In summary, attention is a powerful mechanism that allows transformer models to learn context and understanding from sequential data. It enables the model to process input sequences in parallel, which makes them faster and more scalable than previous models. It also enables the model to generate output sequences that are more accurate and fluent than previous models. Attention is therefore an essential component of transformer models and their applications.
Importance of Transformer Models in AI
Transformer models are important because they have revolutionized NLP by achieving state-of-the-art results on many benchmarks and tasks. Transformer models have also enabled new possibilities for natural language understanding and generation, such as creating realistic dialogues, writing coherent stories, summarizing long documents, answering complex questions, etc.
Transformer models are also important because they are driving a paradigm shift in AI. Some researchers call them “foundation models” because they see them as general-purpose models that can learn from large amounts of data and perform multiple tasks across domains. These models have the potential to become more powerful and intelligent as they are trained on more data and tasks.
However, transformer models also pose some challenges and risks for AI research and society. Some of these challenges include:
Data quality: Transformer models require large amounts of data to train effectively. However, not all data is reliable or unbiased. For example, some data may contain errors, noise, misinformation, or harmful content. This can affect the performance and behavior of the models.
Model interpretability: Transformer models are often complex and opaque. It is hard to understand how they make decisions or what they learn from the data. This can lead to difficulties in debugging, testing, or explaining the models.
Model ethics: Transformer models can generate impressive outputs that may seem human-like or trustworthy. However, these outputs may not always be accurate or appropriate. For example, some outputs may be misleading, offensive, harmful, or unethical. This can raise ethical issues such as privacy, accountability, fairness, or safety.
Therefore, transformer models need to be developed and used with care and responsibility. They also need to be evaluated and regulated by appropriate standards and frameworks.
Conclusion
Transformer models are a new paradigm for natural language processing that uses attention mechanisms to learn context and understanding from sequential data. They have achieved remarkable results and enabled new applications for natural language understanding and generation which contributed to language translation to drug Recommendation workflow. However, they also pose some challenges and risks that need to be addressed and mitigated. Transformer models are an exciting and promising direction for AI research and development.
Credits
Subscribe to my newsletter
Read articles from Dhrutinandan Swain directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by