Understanding Browser Rendering: Discover DOM, CSSOM, and Reflow
 Rohith Akula
Rohith Akula
The most important thing on the web is the Browser.
But how do browsers render the websites that we see on the Internet?
First of all, let us understand what is a browser :
Browser is simple software that can load and execute the requested files by the user from a remote server.
The Internet is based on a network of interconnected computers and servers. When you request a web page, it must be transmitted across this network.
After receiving the requested files from the server, the browser figures out how to display the content. Here you would be asking another question about how would browsers compute any file and how they know to display the content in a specific format. And the answer to that is browsers have an engine that algorithmically decides how to display content. Browsers can render/work with many file formats. Some examples of browser engines are Gecko Engine for Mozilla, Blink for Chromium and Webkit for Safari. Here we are using the browser and browser engine interchangeably so don't get confused with it.
Note that the V8 Engine is different from the browser engines. V8 is the name of the JavaScript engine that powers Google Chrome. It's the thing that takes our JavaScript and executes it while browsing with Chrome.
How browsers load the files -> (HTML, CSS, JS)

Now let us go step by step :
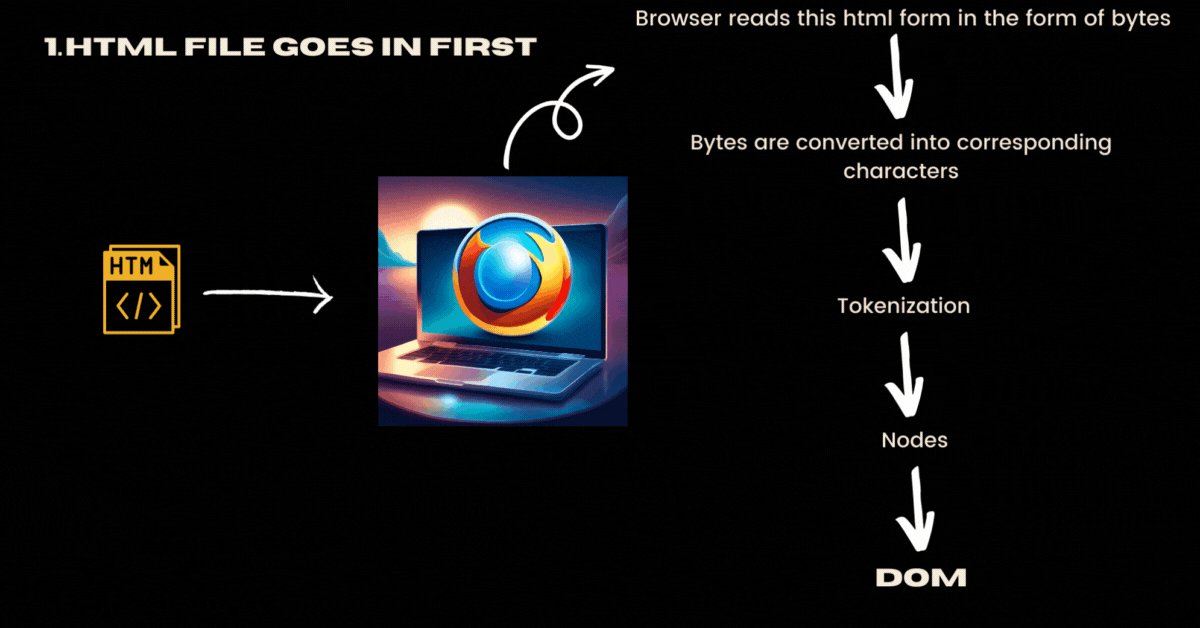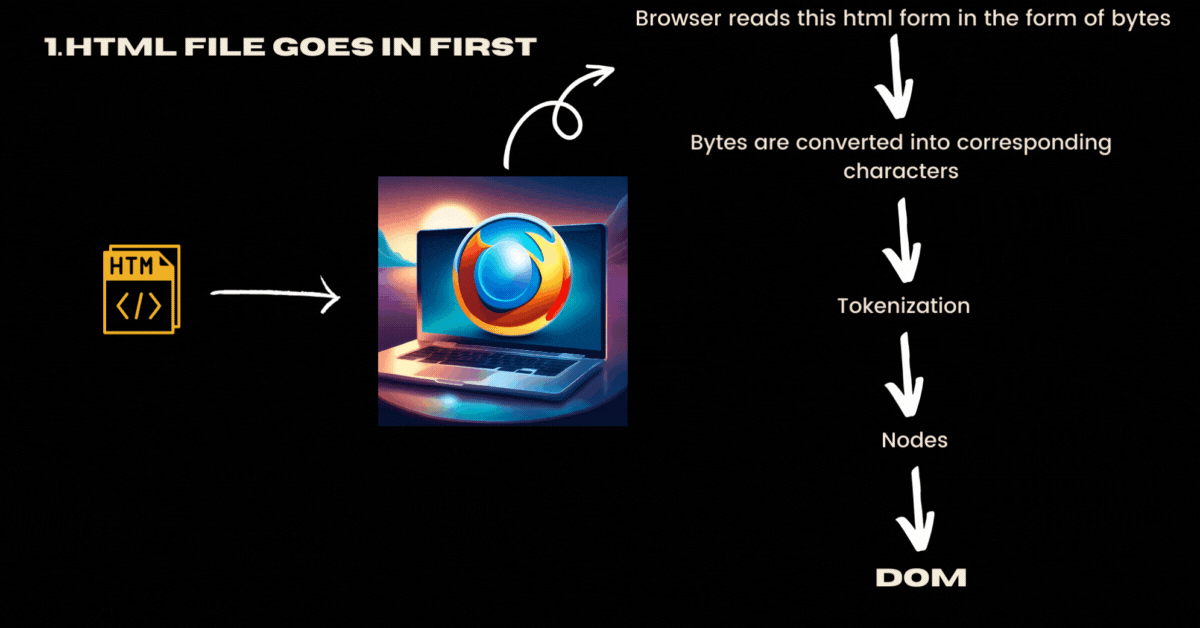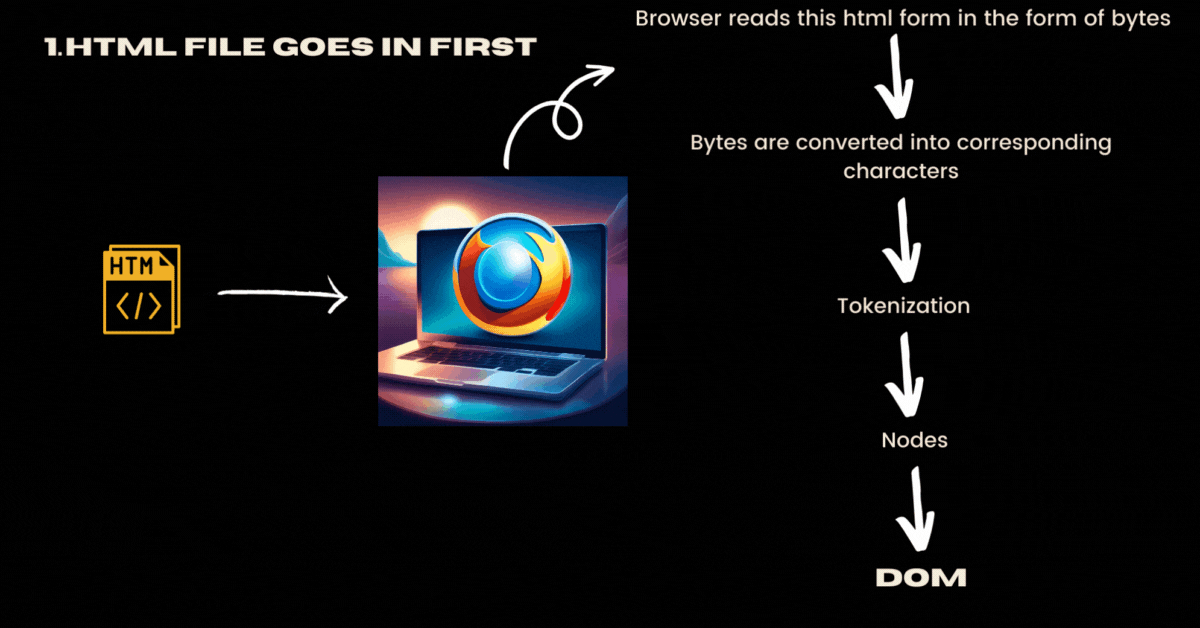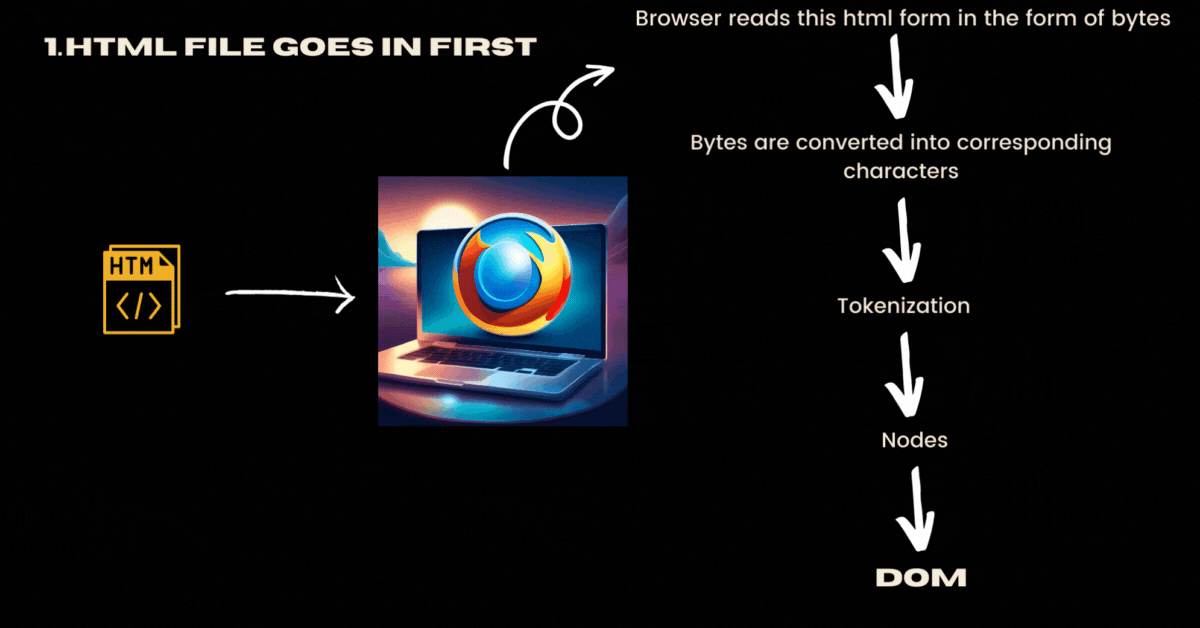
Assume that you requested a webpage and your browser downloaded the essential files from the server. Now your browser has received HTML, CSS and JavaScript files. Your browser would get these files in the form of bytes and not how you manually wrote these files like in human-readable tags format(<html>,<p>,....). Remember this is a fundamental networking concept where networks are designed to transmit binary data, which can be represented as bytes. Text, including HTML, CSS, and JavaScript, is ultimately stored and transmitted as a series of bytes.
These HTML files are generally sent by a specific character encoding (e.g., UTF-8), allowing the browser to correctly interpret and display the text.
<meta charset="UTF-8">Now these bytes are converted into corresponding characters.
As these bytes are converted into characters, the browser tokenizes the content into meaningful units, such as tags, attributes, and text. Simply put tokenizable characters are a bunch of characters in your file that produce the smallest meaningful pieces of information.
To explain it in simple terms, let us assume an example from Python:
text = "hello there how are you doing!!" words = text.split(" ") print(words)This is the output of the above code:
['This', 'is', 'a', 'sample', 'string']So words are the small tokens that build your sentence/string.
Now the browser converts the tokens into nodes.
Here every node is considered distinct with distinct properties.
Now the browser constructs DOM (Document Object Model) by interpreting the relationships between the nodes. To put it simply all the nodes are connected in a proper hierarchical order and it forms like a tree data structure.
But what about the CSS now?
Along with the DOM, CSSOM (CSS Object Model) is also prepared. It also follows the same procedure as the DOM.
CSS Bytes -> Characters -> Tokenization -> Nodes -> CSSOM
Note that the Cascading algorithm helps CSS determine what style will be added to a particular HTML element.
The DOM and CSSOM are now ready to be combined.
Now the browser combines the DOM and CSSOM trees into something called a Render Tree.
DOM + CSSOM = Render Tree
Before we draw the Render Tree on the browser viewport, there is one more step involved called "layout" also referred to as the Reflow step.
In this step, the browser calculates the sizes, metrics and positions for each element.
And the final step here is Painting, browser starts to paint the elements on the screen after all the calculations.
About JavaScript
We are done with DOM and CSSOM, we also have a JavaScript file to add a dynamic touch to our page. But this topic is altogether a separate one and we will see this in another blog post. But for now, remember that the interpretation of JS is handled by the V8 engine in Google Chrome and JS operations are a bit costlier.
But whenever you refer to any HTML document, you see the script tag at the end and only after the body tag, Do you know why?
Because the moment your browser sees the script tag it halts the DOM construction as JS can manipulate or create HTML elements.
For example, if you write the script tag at the beginning of an HTML document followed by some JavaScript operations, and whenever you access any HTML element here you would get undefined as the DOM construction is not yet finished (so we cannot access) and also this may slow down the whole process.
There are also ways to avoid these with Async loading of script tags, more about in future blogs.
Subscribe to my newsletter
Read articles from Rohith Akula directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by